
Maskininlärning
Maskininlärning (ML) är en underkategori av artificiell intelligens (AI) som gör det möjligt för maskiner att lära sig av data, identifiera mönster, göra föruts...
3 min läsning
Machine Learning
AI
+4
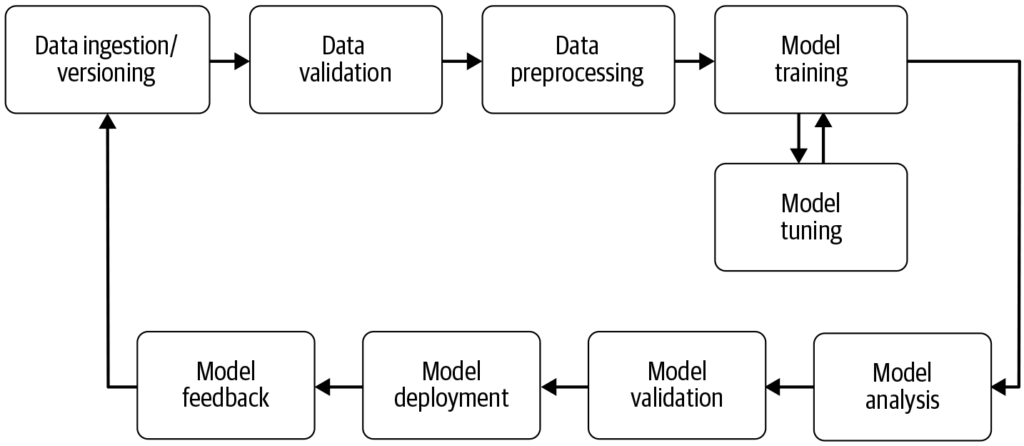
En maskininlärningspipeline automatiserar stegen från datainsamling till driftsättning av modeller och ökar effektivitet, reproducerbarhet och skalbarhet i maskininlärningsprojekt.
En maskininlärningspipeline är ett automatiserat arbetsflöde som effektiviserar utveckling, träning, utvärdering och driftsättning av modeller. Det ökar effektiviteten, reproducerbarheten och skalbarheten och underlättar arbetsmoment från datainsamling till driftsättning och underhåll av modellen.
En maskininlärningspipeline är ett automatiserat arbetsflöde som omfattar en serie steg involverade i utveckling, träning, utvärdering och driftsättning av maskininlärningsmodeller. Den är utformad för att effektivisera och standardisera processerna som krävs för att omvandla rådata till handlingsbara insikter genom maskininlärningsalgoritmer. Pipeline-ansatsen möjliggör effektiv hantering av data, modellträning och driftsättning, vilket gör det enklare att hantera och skala maskininlärningsaktiviteter.
Källa: Building Machine Learning
Datainsamling: Det inledande steget där data samlas in från olika källor såsom databaser, API:er eller filer. Datainsamling är en metodisk process som syftar till att samla in meningsfull information för att bygga ett konsekvent och komplett dataset för ett specifikt affärssyfte. Denna rådata är avgörande för att bygga maskininlärningsmodeller men kräver ofta förbehandling för att vara användbar. Som AltexSoft påpekar innebär datainsamling ett systematiskt insamlande av information för att stödja analys och beslutsfattande. Denna process är viktig då den utgör grunden för alla efterföljande steg i pipelinen och är ofta kontinuerlig för att säkerställa att modeller tränas på relevant och uppdaterad data.
Datapreprocessering: Rådata rensas och omvandlas till ett lämpligt format för modellträning. Vanliga preprocesseringssteg inkluderar hantering av saknade värden, kodning av kategoriska variabler, skalning av numeriska egenskaper samt uppdelning av data i tränings- och testuppsättningar. Detta steg säkerställer att datan är i rätt format och fri från inkonsekvenser som kan påverka modellens prestanda.
Feature Engineering: Skapande av nya egenskaper eller urval av relevanta egenskaper från datan för att förbättra modellens prediktiva kraft. Detta steg kan kräva domänspecifik kunskap och kreativitet. Feature engineering är en kreativ process som omvandlar rådata till meningsfulla egenskaper som bättre representerar det underliggande problemet och ökar prestandan hos maskininlärningsmodeller.
Modellval: Lämplig(a) maskininlärningsalgoritm(er) väljs utifrån problemtyp (t.ex. klassificering, regression), datakaraktäristik och prestandakrav. Hyperparameterjustering kan också beaktas i detta steg. Valet av rätt modell är avgörande då det påverkar noggrannheten och effektiviteten i prediktionerna.
Modellträning: Den valda modellen eller modellerna tränas med hjälp av träningsdatan. Detta innebär att lära sig de underliggande mönstren och sambanden i datan. Förtränade modeller kan också användas istället för att träna en ny modell från grunden. Träningen är ett viktigt steg där modellen lär sig av datan för att kunna göra välgrundade prediktioner.
Modellevaluering: Efter träning utvärderas modellens prestanda med hjälp av en separat testuppsättning eller genom korsvalidering. Utvärderingsmåtten beror på det specifika problemet men kan inkludera noggrannhet, precision, recall, F1-score, medelkvadratiskt fel med mera. Detta steg är avgörande för att säkerställa att modellen presterar bra på osedd data.
Modellens driftsättning: När en tillfredsställande modell har utvecklats och utvärderats kan den driftsättas i en produktionsmiljö för att göra prediktioner på ny, osedd data. Driftsättning kan innebära att skapa API:er och integrera med andra system. Driftsättning är det sista steget i pipelinen där modellen görs tillgänglig för verklig användning.
Övervakning och underhåll: Efter driftsättning är det viktigt att kontinuerligt övervaka modellens prestanda och träna om den vid behov för att anpassa sig till förändrade datamönster, så att modellen förblir korrekt och tillförlitlig i verkliga miljöer. Denna pågående process säkerställer att modellen förblir relevant och korrekt över tid.
Naturlig språkbehandling (NLP): NLP-uppgifter involverar ofta flera upprepbara steg såsom dataimport, textstädning, tokenisering och sentimentanalys. Pipelines hjälper till att modulera dessa steg och möjliggör enkla ändringar och uppdateringar utan att påverka andra komponenter.
Prediktivt underhåll: Inom industrier som tillverkning kan pipelines användas för att förutspå utrustningsfel genom att analysera sensordata, vilket möjliggör proaktivt underhåll och minskad stilleståndstid.
Finans: Pipelines kan automatisera bearbetning av finansiell data för att upptäcka bedrägerier, bedöma kreditrisker eller förutsäga aktiekurser, och därmed förbättra beslutsprocesser.
Sjukvård: Inom vården kan pipelines bearbeta medicinska bilder eller patientjournaler för att bistå i diagnostik eller förutspå patientutfall och därigenom förbättra behandlingsstrategier.
Maskininlärningspipelines är en integrerad del av AI och automation](https://www.flowhunt.io#:~:text=automation “Bygg AI-verktyg och chattbotar med FlowHunts plattform utan kod. Utforska mallar, komponenter och sömlös automation. Boka en demo idag!”) genom att tillhandahålla en strukturerad ram för att automatisera maskininlärningsuppgifter. Inom området AI-automation, säkerställer pipelines att modeller tränas och driftsätts effektivt, vilket möjliggör att AI-system såsom [chattbotar kan lära sig och anpassa sig till ny data utan manuell inblandning. Denna automation är avgörande för att skala AI-applikationer och säkerställa att de levererar konsekvent och tillförlitlig prestanda inom olika områden. Genom att använda pipelines kan organisationer stärka sina AI-förmågor och se till att deras maskininlärningsmodeller förblir relevanta och effektiva i föränderliga miljöer.
Forskning om maskininlärningspipeline
“Deep Pipeline Embeddings for AutoML” av Sebastian Pineda Arango och Josif Grabocka (2023) fokuserar på utmaningarna med att optimera maskininlärningspipelines inom Automated Machine Learning (AutoML). Artikeln introducerar en ny neural arkitektur som är utformad för att fånga djupa interaktioner mellan pipeline-komponenter. Författarna föreslår att pipelines bäddas in i latenta representationer via en unik per-komponentskodare. Dessa inbäddningar används inom en Bayesian Optimization-ram för att söka efter optimala pipelines. Artikeln betonar användningen av meta-lärande för att finjustera nätverkets parametrar för pipeline-inbäddning och visar toppresultat i pipelineoptimering över flera dataset. Läs mer.
“AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model” av Tien-Dung Nguyen m.fl. (2020) behandlar den tidskrävande utvärderingen av maskininlärningspipelines under AutoML-processer. Studien kritiserar traditionella metoder som Bayesian och genetiska optimeringar för deras ineffektivitet. För att motverka detta presenterar författarna AVATAR, en surrogatmodell som effektivt kan utvärdera pipeline-giltighet utan faktisk körning. Detta tillvägagångssätt påskyndar sammansättning och optimering av komplexa pipelines avsevärt genom att tidigt filtrera bort ogiltiga pipelines. Läs mer.
“Data Pricing in Machine Learning Pipelines” av Zicun Cong m.fl. (2021) undersöker den avgörande rollen data spelar i maskininlärningspipelines och behovet av datapricing för att underlätta samarbete mellan flera aktörer. Artikeln sammanfattar de senaste framstegen inom datapricing i kontext av maskininlärning, med fokus på dess betydelse i olika steg av pipelinen. Den ger insikter om prissättningsstrategier för insamling av träningsdata, samarbetsbaserad modellträning och leverans av maskininlärningstjänster, och belyser bildandet av ett dynamiskt ekosystem. Läs mer.
En maskininlärningspipeline är en automatiserad sekvens av steg—från datainsamling och förbehandling till modellträning, utvärdering och driftsättning—som effektiviserar och standardiserar processen att bygga och underhålla maskininlärningsmodeller.
Nyckelkomponenter inkluderar datainsamling, datapreprocessering, feature engineering, modellval, modellträning, modellevaluering, modellens driftsättning samt löpande övervakning och underhåll.
Maskininlärningspipelines ger modularisering, effektivitet, reproducerbarhet, skalbarhet, förbättrat samarbete och enklare driftsättning av modeller i produktionsmiljöer.
Användningsområden inkluderar naturlig språkbehandling (NLP), prediktivt underhåll inom tillverkning, finansiell riskbedömning och bedrägeridetektion samt diagnostik inom sjukvården.
Utmaningar inkluderar att säkerställa datakvalitet, hantera pipeline-komplexitet, integrera med befintliga system samt kontrollera kostnader relaterade till beräkningsresurser och infrastruktur.
Boka en demo för att upptäcka hur FlowHunt kan hjälpa dig att automatisera och skala dina arbetsflöden för maskininlärning med enkelhet.
Maskininlärning (ML) är en underkategori av artificiell intelligens (AI) som gör det möjligt för maskiner att lära sig av data, identifiera mönster, göra föruts...
BigML är en plattform för maskininlärning som är utformad för att förenkla skapandet och driftsättningen av prediktiva modeller. Grundad 2011, har dess uppdrag ...
MLflow är en öppen plattform utformad för att effektivisera och hantera hela maskininlärningslivscykeln. Den erbjuder verktyg för experimentuppföljning, kodpake...
