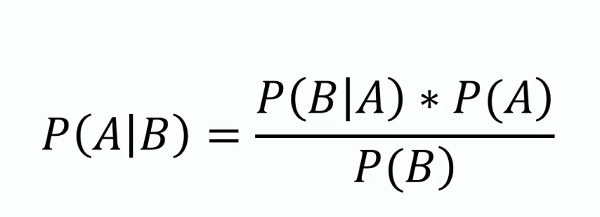

Bayesiska nätverk
Ett bayesiskt nätverk (BN) är en probabilistisk grafmodell som representerar variabler och deras villkorliga beroenden via en riktad acyklisk graf (DAG). Bayesi...
3 min läsning
Bayesian Networks
AI
+3
Naiv Bayes är en enkel men kraftfull familj av klassificeringsalgoritmer som utnyttjar Bayes sats, vanligt förekommande för skalbara uppgifter som skräppostdetektering och textklassificering.
Naiv Bayes är en familj av enkla, effektiva klassificeringsalgoritmer baserade på Bayes sats, med antagandet om villkorligt oberoende mellan funktioner. Den används ofta för skräppostdetektering, textklassificering och mer tack vare sin enkelhet och skalbarhet.
Naiv Bayes är en familj av klassificeringsalgoritmer baserade på Bayes sats, som tillämpar principen om villkorlig sannolikhet. Termen ”naiv” syftar på det förenklade antagandet att alla funktioner i en datamängd är villkorligt oberoende av varandra givet klassetiketten. Trots att detta antagande ofta bryts i verkliga data är Naiv Bayes-klassificerare erkända för sin enkelhet och effektivitet i olika tillämpningar, såsom textklassificering och skräppostdetektering.
Bayes sats
Denna sats utgör grunden för Naiv Bayes och ger en metod för att uppdatera sannolikhetsuppskattningen för en hypotes i takt med att mer bevis eller information blir tillgänglig. Matematiskt uttrycks den som:
där ( P(A|B) ) är den posteriora sannolikheten, ( P(B|A) ) är sannolikheten, ( P(A) ) är den priori sannolikheten och ( P(B) ) är beviset.
Villkorligt oberoende
Det naiva antagandet att varje funktion är oberoende av alla andra funktioner givet klassetiketten. Detta antagande förenklar beräkningen och gör att algoritmen skalar väl med stora datamängder.
Posterior sannolikhet
Sannolikheten för klassetiketten givet funktionsvärdena, beräknad med hjälp av Bayes sats. Detta är den centrala komponenten vid prediktioner med Naiv Bayes.
Typer av Naiv Bayes-klassificerare
Naiv Bayes-klassificerare fungerar genom att beräkna den posteriora sannolikheten för varje klass givet en uppsättning funktioner och väljer den klass med högst posterior sannolikhet. Processen omfattar följande steg:
Naiv Bayes-klassificerare är särskilt effektiva i följande tillämpningar:
Tänk dig en skräppostfiltreringsapplikation som använder Naiv Bayes. Träningsdata består av e-post med etiketter ”skräppost” eller ”inte skräppost”. Varje e-post representeras av en uppsättning funktioner, såsom förekomst av specifika ord. Under träningen beräknar algoritmen sannolikheten för varje ord givet klassetiketten. För ett nytt e-postmeddelande beräknar algoritmen den posteriora sannolikheten för ”skräppost” respektive ”inte skräppost” och tilldelar etiketten med högst sannolikhet.
Naiv Bayes-klassificerare kan integreras i AI-system och chattbottar för att förbättra deras förmåga till naturlig språkbehandling. Till exempel kan de användas för att identifiera användarens intention, klassificera texter i fördefinierade kategorier eller filtrera olämpligt innehåll. Denna funktionalitet förbättrar interaktionskvaliteten och relevansen hos AI-drivna lösningar. Dessutom gör algoritmens effektivitet den lämplig för realtidsapplikationer, vilket är viktigt för AI-automation och chattbottsystem.
Naiv Bayes är en familj av enkla men kraftfulla sannolikhetsalgoritmer baserade på användning av Bayes sats med starka oberoendeantaganden mellan funktionerna. Den används ofta för klassificeringsuppgifter tack vare sin enkelhet och effektivitet. Här är några vetenskapliga artiklar som diskuterar olika tillämpningar och förbättringar av Naiv Bayes-klassificeraren:
Improving spam filtering by combining Naive Bayes with simple k-nearest neighbor searches
Författare: Daniel Etzold
Publicerad: 30 november 2003
Denna artikel undersöker användningen av Naiv Bayes för e-postklassificering och lyfter fram dess enkelhet och effektivitet. Studien presenterar empiriska resultat som visar hur en kombination av Naiv Bayes och k-närmsta grannesökning kan förbättra skräppostfiltrens noggrannhet. Kombinationen gav små förbättringar i noggrannhet vid stort antal funktioner och betydande förbättringar vid färre funktioner. Läs artikeln.
Locally Weighted Naive Bayes
Författare: Eibe Frank, Mark Hall, Bernhard Pfahringer
Publicerad: 19 oktober 2012
Denna artikel behandlar Naiv Bayes största svaghet, nämligen antagandet om attributoberoende. Den introducerar en lokalt viktad version av Naiv Bayes som lär sig lokala modeller vid prediktionstillfället och därigenom mildrar oberoendeantagandet. De experimentella resultaten visar att denna metod sällan försämrar noggrannheten och ofta förbättrar den avsevärt. Metoden får beröm för sin konceptuella och beräkningsmässiga enkelhet jämfört med andra tekniker. Läs artikeln.
Naive Bayes Entrapment Detection for Planetary Rovers
Författare: Dicong Qiu
Publicerad: 31 januari 2018
I denna studie diskuteras tillämpningen av Naiv Bayes-klassificerare för fastkörningsdetektion hos planetariska rovers. Den definierar kriterierna för fastkörning och demonstrerar användningen av Naiv Bayes för att upptäcka sådana situationer. Artikeln redogör för experiment med AutoKrawler-rovers och ger insikter om Naiv Bayes effektivitet för autonoma räddningsprocedurer. Läs artikeln.
Naiv Bayes är en familj av klassificeringsalgoritmer baserade på Bayes sats, som antar att alla funktioner är villkorligt oberoende givet klassetiketten. Det används brett för textklassificering, skräppostfiltrering och sentimentanalys.
De viktigaste typerna är Gaussisk Naiv Bayes (för kontinuerliga funktioner), Multinomial Naiv Bayes (för diskreta funktioner som ordräkning) och Bernoulli Naiv Bayes (för binära/booleanfunktioner).
Naiv Bayes är enkel att implementera, beräkningsmässigt effektiv, skalbar till stora datamängder och hanterar högdimensionell data väl.
Dess huvudsakliga begränsning är antagandet om funktionsoberoende, vilket ofta inte stämmer för verkliga data. Den kan också tilldela noll sannolikhet till osedda funktioner, vilket kan motverkas med tekniker som Laplaceutjämning.
Naiv Bayes används i AI-system och chattbottar för intentionsdetektion, textklassificering, skräppostfiltrering och sentimentanalys, vilket stärker förmågan till naturlig språkbehandling och möjliggör realtidsbeslut.
Smarta chattbottar och AI-verktyg under ett och samma tak. Koppla ihop intuitiva block för att förvandla dina idéer till automatiserade Flöden.
Ett bayesiskt nätverk (BN) är en probabilistisk grafmodell som representerar variabler och deras villkorliga beroenden via en riktad acyklisk graf (DAG). Bayesi...
En AI-klassificerare är en maskininlärningsalgoritm som tilldelar klassetiketter till indata, och kategoriserar information i fördefinierade klasser baserat på ...
Upptäck den viktiga rollen som AI-intentklassificering spelar för att förbättra användarinteraktioner med teknik, effektivisera kundsupport och förenkla affärsp...
