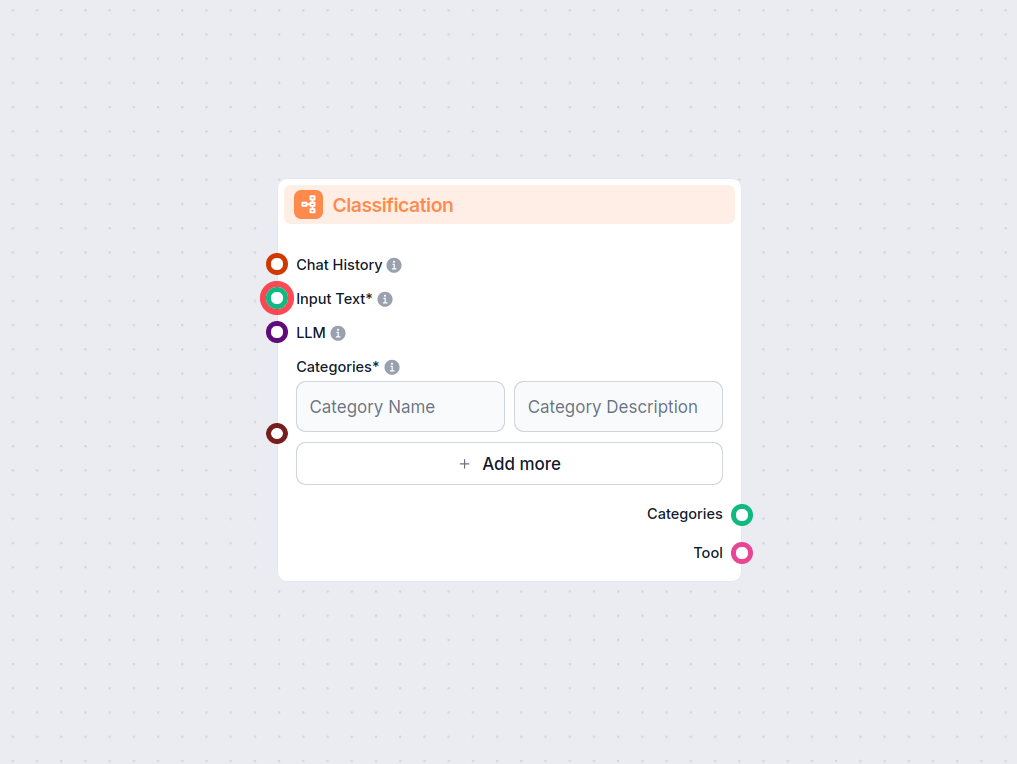
Textklassificering
Lås upp automatiserad textkategorisering i dina arbetsflöden med komponenten Textklassificering för FlowHunt. Klassificera enkelt inmatad text i användardefinie...
2 min läsning
AI
Classification
+3
Ordklassmärkning tilldelar grammatiska kategorier som substantiv och verb till ord i text, vilket gör det möjligt för maskiner att bättre tolka och bearbeta mänskligt språk för NLP-uppgifter.
Ordklassmärkning (POS-tagging) är en avgörande uppgift inom datorlingvistik och naturlig språkbehandling som överbryggar interaktionen mellan människa och dator. Upptäck dess nyckelaspekter, funktioner och tillämpningar idag! Det innebär att varje ord i en text tilldelas sin motsvarande ordklass, baserat på dess definition och kontext i en mening. Huvudmålet är att kategorisera ord i grammatiska kategorier som substantiv, verb, adjektiv, adverb etc., vilket gör det möjligt för maskiner att bearbeta och förstå mänskligt språk mer effektivt. Denna uppgift kallas även grammatisk märkning eller ordklassdisambiguering och utgör grunden för olika avancerade lingvistiska analyser.
Innan vi går djupare in på POS-tagging är det viktigt att förstå några grundläggande ordklasser på engelska:
POS-tagging är avgörande för att maskiner ska kunna tolka och interagera med mänskligt språk på ett korrekt sätt. Det fungerar som grunden för olika NLP-applikationer, inklusive:
Tänk på meningen:
“The quick brown fox jumps over the lazy dog.”
Efter att ha tillämpat POS-tagging märks varje ord enligt följande:
Denna märkning ger insikt i meningens grammatiska struktur och hjälper vidare NLP-uppgifter genom att synliggöra relationerna mellan orden.
Det finns flera metoder för ordklassmärkning, var och en med sina egna fördelar och utmaningar:
Regelbaserad märkning:
Statistisk märkning:
Transformeringsbaserad märkning:
Maskininlärningsbaserad märkning:
Hybrida metoder:
POS-tagging spelar en central roll i utvecklingen av AI-system som interagerar med mänskligt språk, såsom chattbottar och virtuella assistenter. Genom att förstå grammatisk struktur i användarens inmatning kan AI-system ge mer korrekta svar och förbättra användarupplevelsen. Inom AI-automation hjälper POS-tagging till med uppgifter som dokumentklassificering, sentimentanalys och innehållsmoderering genom att ge syntaktisk och semantisk insikt i texten.
Ordklassmärkning (POS-tagging) är en grundläggande process inom naturlig språkbehandling (NLP) som innebär att varje ord i en text märks med dess motsvarande ordklass, såsom substantiv, verb, adjektiv etc. Denna process hjälper till att förstå satsers syntaktiska struktur, vilket är avgörande för olika NLP-applikationer som textanalys, sentimentanalys och maskinöversättning.
Viktiga forskningsartiklar:
Method for Customizable Automated Tagging
Denna artikel av Maharshi R. Pandya och kollegor tar upp utmaningarna med över- och undermärkning i textdokument. Författarna föreslår en märkningsmetod med IBM Watsons NLU-tjänst för att skapa en universell uppsättning taggar tillämpliga på stora dokumentkorpusar. De visar metodens effektivitet genom att tillämpa den på 87 397 dokument och uppnår hög märkningsnoggrannhet. Forskningen belyser vikten av effektiva märkningssystem för hantering av stora textmängder.
Läs mer
A Joint Named-Entity Recognizer for Heterogeneous Tag-sets Using a Tag Hierarchy
Genady Beryozkin och hans team undersöker domänanpassning inom namngiven entitetsigenkänning med flera heterogent märkta träningsuppsättningar. De föreslår att använda en tagghierarki för att träna ett neuralt nätverk som kan hantera olika märkningsuppsättningar. Deras experiment visar förbättrad prestanda vid konsolidering av taggsystem, vilket belyser fördelarna med ett hierarkiskt tillvägagångssätt.
Läs mer
Who Ordered This?: Exploiting Implicit User Tag Order Preferences for Personalized Image Tagging
Amandianeze O. Nwana och Tsuhan Chen undersöker rollen av taggningsordning i bildmärkning. De föreslår en ny objektiv funktion som tar hänsyn till användarnas föredragna taggordningar för att förbättra automatiserad bildmärkning. Deras metod visar förbättrad prestanda vid personaliserad märkning och betonar användarbeteendets påverkan på märkningssystem.
Läs mer
Ordklassmärkning (POS-tagging) är processen att tilldela varje ord i en text dess grammatiska kategori, såsom substantiv, verb, adjektiv eller adverb, baserat på dess definition och kontext. Det är grundläggande för NLP-uppgifter som maskinöversättning och namngiven entitetsigenkänning.
POS-tagging gör det möjligt för maskiner att tolka och bearbeta mänskligt språk korrekt. Det ligger till grund för applikationer som maskinöversättning, informationsutvinning, text-till-tal-omvandling och chatbot-interaktioner genom att klargöra meningsbyggnadens grammatiska struktur.
De primära metoderna inkluderar regelbaserad märkning, statistisk märkning med sannolikhetsmodeller, transformeringsbaserad märkning, maskininlärningsbaserade metoder och hybridsystem som kombinerar dessa tekniker för högre noggrannhet.
Utmaningar inkluderar hantering av tvetydiga ord som kan tillhöra flera kategorier, idiomatiska uttryck, ord utanför ordförrådet och anpassning av modeller till olika domäner eller texttyper.
Börja bygga smartare AI-lösningar med avancerade NLP-tekniker som ordklassmärkning. Automatisera språkförståelse med FlowHunt.
Lås upp automatiserad textkategorisering i dina arbetsflöden med komponenten Textklassificering för FlowHunt. Klassificera enkelt inmatad text i användardefinie...
Textklassificering, även känt som textkategorisering eller texttaggning, är en central NLP-uppgift som tilldelar fördefinierade kategorier till textdokument. De...
En AI-klassificerare är en maskininlärningsalgoritm som tilldelar klassetiketter till indata, och kategoriserar information i fördefinierade klasser baserat på ...
