
Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) är en avancerad AI-ram som kombinerar traditionella informationssökningssystem med generativa stora språkmodeller (LLMs), v...
4 min läsning
RAG
AI
+4

Frågebesvarande system med RAG förbättrar LLMs genom att integrera realtidsdataxadsökning och naturlig språkxadgenerering för exakta, kontextuellt relevanta svar.
Frågebesvarande system med Retrieval-Augmented Generation (RAG) förbättrar språkmodeller genom att integrera realtidsdata från externa källor för exakta och relevanta svar. Det optimerar prestandan inom dynamiska områden och erbjuder ökad noggrannhet, dynamiskt innehåll och förbättrad relevans.
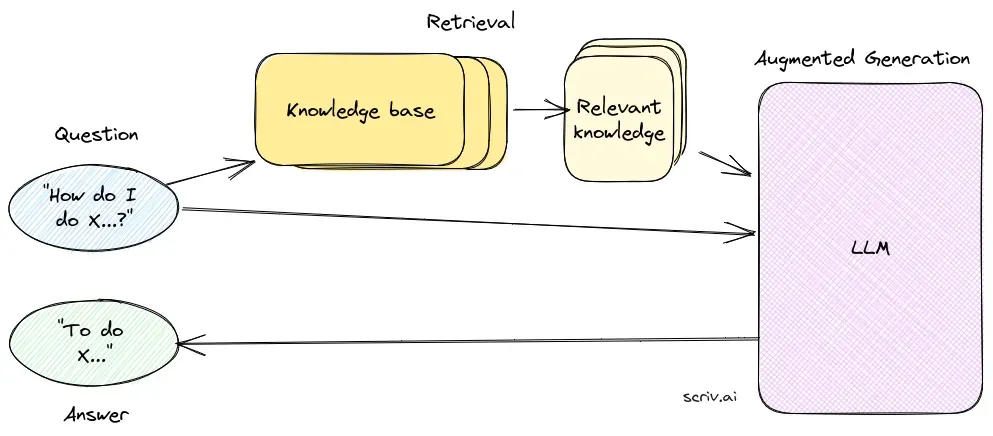
Frågebesvarande system med Retrieval-Augmented Generation (RAG) är en innovativ metod som kombinerar styrkorna från informationssökning och naturlig språkgenerering för att skapa människoliknande text från data, vilket stärker AI, chatbots, rapporter och personaliserar upplevelser. Detta hybrida tillvägagångssätt förstärker stora språkmodeller (LLMs) genom att komplettera deras svar med relevant, aktuell information hämtad från externa datakällor. Till skillnad från traditionella metoder som enbart förlitar sig på förtränade modeller, integrerar RAG dynamiskt extern data, vilket gör det möjligt för systemen att ge mer exakta och kontextuellt relevanta svar, särskilt inom områden som kräver den senaste informationen eller specialiserad kunskap.
RAG optimerar prestandan hos LLMs genom att säkerställa att svar inte enbart genereras utifrån en intern databas utan även baseras på realtidsdata från auktoritativa källor. Detta tillvägagångssätt är avgörande för frågebesvarande uppgifter inom dynamiska områden där informationen ständigt förändras.
Sökkomponenten ansvarar för att hämta relevant information från stora dataset, vanligtvis lagrade i en vektordatabas. Denna komponent använder semantisk sökning för att identifiera och extrahera textsegment eller dokument som är mycket relevanta för användarens fråga.
Genereringskomponenten, vanligtvis en LLM som GPT-3 eller BERT, sammanställer ett svar genom att kombinera användarens ursprungliga fråga med det hämtade sammanhanget. Denna komponent är avgörande för att skapa sammanhängande och kontextuellt lämpliga svar.
Att implementera ett RAG-system innebär flera tekniska steg:
Forskning om frågebesvarande med Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) är en metod som förbättrar frågebesvarande system genom att kombinera sökmekanismer med generativa modeller. Ny forskning har undersökt effektivitet och optimering av RAG i olika sammanhang.
RAG är en metod som kombinerar informationsxadsökning och naturlig språkxadgenerering för att ge korrekta, aktuella svar genom att integrera externa datakällor i stora språkmodeller.
Ett RAG-system består av en sökkomponent, som hämtar relevant information från vektordataxadbaser med semantisk sökning, samt en genereringsxadkomponent, vanligtvis en LLM, som sammanställer svar med både användarens fråga och det hämtade sammanhanget.
RAG förbättrar noggrannheten genom att hämta kontextuellt relevant information, stödjer dynamiska uppdateringar från externa kunskapsxadbaser och ökar relevansen och kvaliteten på genererade svar.
Vanliga användningsområden är AI-chatbots, kundsupport, automatiserad innehållsgenerering och utbildningsverktyg som kräver korrekta, kontextmedvetna och aktuella svar.
RAG-system kan vara resurskrävande, kräver noggrann integration för optimal prestanda och måste säkerställa faktamässig korrekthet i hämtad information för att undvika vilseledande eller föråldrade svar.
Upptäck hur Retrieval-Augmented Generation kan stärka din chatbot och supportlösning med snabba, korrekta svar i realtid.
Retrieval Augmented Generation (RAG) är en avancerad AI-ram som kombinerar traditionella informationssökningssystem med generativa stora språkmodeller (LLMs), v...
Upptäck de viktigaste skillnaderna mellan Retrieval-Augmented Generation (RAG) och Cache-Augmented Generation (CAG) inom AI. Lär dig hur RAG dynamiskt hämtar re...
Frågeexpansion är processen att förbättra en användares ursprungliga fråga genom att lägga till termer eller kontext, vilket förbättrar dokumentåtervinningen fö...

