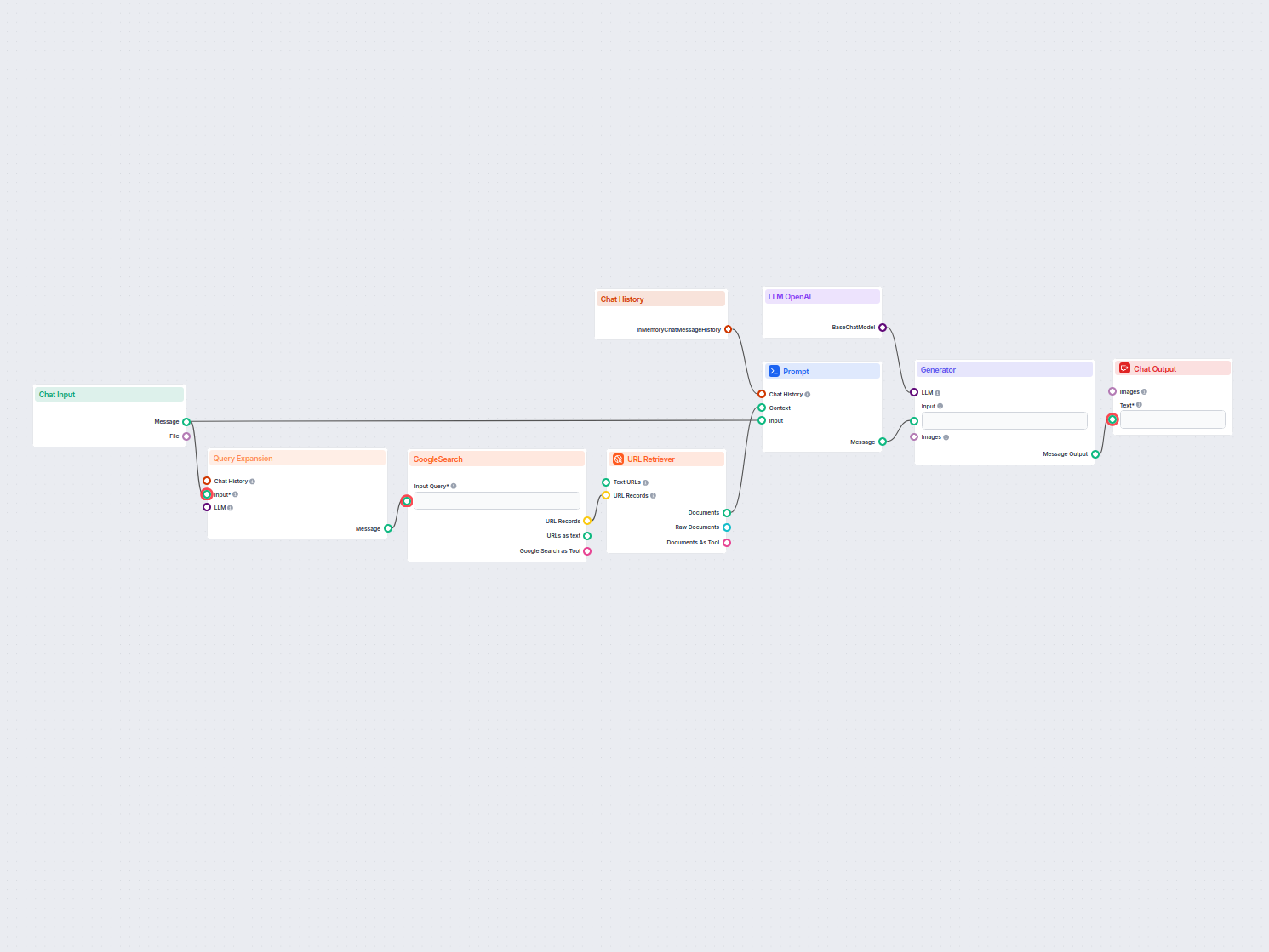
Realtids domänspecifik RAG-chattbot
En chattbot i realtid som använder Google Sök begränsat till din egen domän, hämtar relevant webbinnehåll och utnyttjar OpenAI LLM för att besvara användarfrågo...
4 min läsning
En hämtningspipeline gör det möjligt för chatbottar att hämta och bearbeta relevant extern kunskap för exakta, realtidsbaserade och kontextmedvetna svar med hjälp av RAG, embedding och vektordatabaser.
En hämtningspipeline för chatbottar syftar på den tekniska arkitektur och process som gör det möjligt för chatbottar att hämta, bearbeta och återfinna relevant information som svar på användarfrågor. Till skillnad från enkla fråge-svar-system som enbart förlitar sig på förtränade språkmodeller, integrerar hämtningspipelines externa kunskapsbaser eller datakällor. Detta gör att chatbotten kan ge exakta, kontextuellt relevanta och uppdaterade svar även när datan inte är inneboende i själva språkmodellen.
Hämtningspipeline består vanligtvis av flera komponenter, inklusive dataingest, skapande av embedding, vektorlagring, kontexthämtning och svarsgenerering. Implementeringen bygger ofta på Retrieval-Augmented Generation (RAG), som kombinerar styrkorna hos datahämtningssystem och stora språkmodeller (LLMs) för svarsgenerering.
En hämtningspipeline används för att förstärka chattbottens kapacitet genom att den kan:
Dokumentingest
Insamling och förbehandling av rådata, som kan inkludera PDF:er, textfiler, databaser eller API:er. Verktyg som LangChain eller LlamaIndex används ofta för smidig dataingest.
Exempel: Ladda in kundservice-FAQ:er eller produktspecifikationer i systemet.
Dokumentförbehandling
Långa dokument delas upp i mindre, semantiskt meningsfulla delar. Detta är nödvändigt för att få texten att passa i embeddingmodeller som vanligtvis har tokenbegränsningar (t.ex. 512 tokens).
Exempel på kodsnutt:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(document_list)
Embeddinggenerering
Textdata omvandlas till högdimensionella vektorrepresentationer med hjälp av embeddingmodeller. Dessa embeddingar kodar semantisk betydelse av datan numeriskt.
Exempel på embeddingmodell: OpenAI:s text-embedding-ada-002 eller Hugging Face:s e5-large-v2.
Vektorlager
Embeddingar lagras i vektordatabaser optimerade för likhetsökningar. Verktyg som Milvus, Chroma eller PGVector används ofta.
Exempel: Lagra produktbeskrivningar och deras embeddingar för effektiv hämtning.
Frågebehandling
När en användarfråga tas emot omvandlas den till en frågevektor med samma embeddingmodell. Detta möjliggör semantisk likhetsmatchning mot lagrade embeddingar.
Exempel på kodsnutt:
query_vector = embedding_model.encode("What are the specifications of Product X?")
retrieved_docs = vector_db.similarity_search(query_vector, k=5)
Datahämtning
Systemet hämtar de mest relevanta datadelarna baserat på likhetspoäng (t.ex. cosinuslikhet). Multimodala hämtningssystem kan kombinera SQL-databaser, kunskapsgrafer och vektorsökningar för robustare resultat.
Svarsgenerering
Den hämtade datan kombineras med användarfrågan och skickas till en stor språkmodell (LLM) för att skapa ett slutgiltigt, naturligt språkbaserat svar. Detta steg kallas ofta augmented generation.
Exempel på promptmall:
prompt_template = """
Context: {context}
Question: {question}
Please provide a detailed response using the context above.
"""
Efterbearbetning och validering
Avancerade hämtningspipelines inkluderar hallucinationsdetektion, relevanskontroller eller svarsbetyg för att säkerställa att resultatet är faktabaserat och relevant.
Kundsupport
Chatbottar kan hämta produktmanualer, felsökningsguider eller FAQ:er för att ge omedelbara svar på kundfrågor.
Exempel: En chattbot som hjälper en kund att återställa en router genom att hämta relevant avsnitt ur användarhandboken.
Företagskunskapshantering
Interna företagschatbottar kan få tillgång till företagsspecifik data som HR-policyer, IT-supportdokumentation eller efterlevnadsguider.
Exempel: Anställda som frågar en intern chattbot om sjukfrånvaropolicyer.
E-handel
Chatbottar hjälper användare genom att hämta produktdetaljer, recensioner eller lagertillgänglighet.
Exempel: “Vilka är de bästa funktionerna hos Produkt Y?”
Hälsovård
Chatbottar hämtar medicinsk litteratur, riktlinjer eller patientdata för att hjälpa vårdpersonal eller patienter.
Exempel: En chattbot som hämtar varningar om läkemedelsinteraktioner från en läkemedelsdatabas.
Utbildning och forskning
Akademiska chatbottar använder RAG-pipelines för att hämta vetenskapliga artiklar, besvara frågor eller sammanfatta forskningsresultat.
Exempel: “Kan du sammanfatta resultaten från denna studie om klimatförändringar 2023?”
Juridik och efterlevnad
Chatbottar hämtar juridiska dokument, rättspraxis eller efterlevnadskrav för att assistera jurister.
Exempel: “Vad är den senaste uppdateringen om GDPR-regleringen?”
En chattbot byggd för att besvara frågor från företagets årliga finansiella rapport i PDF-format.
En chattbot som kombinerar SQL, vektorsökning och kunskapsgrafer för att besvara en anställds fråga.
Genom att använda hämtningspipelines är chatbottar inte längre begränsade av statisk träningsdata, utan kan leverera dynamiska, precisa och kontextuella interaktioner.
Hämtningspipelines spelar en avgörande roll i moderna chattbotsystem och möjliggör intelligenta och kontextmedvetna interaktioner.
“Lingke: A Fine-grained Multi-turn Chatbot for Customer Service” av Pengfei Zhu et al. (2018)
Introducerar Lingke, en chattbot som integrerar informationshämtning för att hantera flervändningskonversationer. Den använder finfördelad pipelinebehandling för att destillera svar från ostrukturerade dokument och använder uppmärksam kontext-svarsmatchning för sekventiella interaktioner, vilket avsevärt förbättrar chattbottens förmåga att hantera komplexa användarfrågor.
Läs artikeln här.
“FACTS About Building Retrieval Augmented Generation-based Chatbots” av Rama Akkiraju et al. (2024)
Utforskar utmaningar och metoder vid utveckling av företagsklassade chatbottar med Retrieval Augmented Generation (RAG)-pipelines och stora språkmodeller (LLMs). Författarna föreslår FACTS-ramverket, med fokus på Freshness, Architectures, Cost, Testing och Security i RAG-pipelineutveckling. Deras empiriska resultat belyser avvägningar mellan noggrannhet och latens vid skalning av LLM:er, och ger värdefulla insikter för att bygga säkra och högpresterande chatbottar. Läs artikeln här.
“From Questions to Insightful Answers: Building an Informed Chatbot for University Resources” av Subash Neupane et al. (2024)
Presenterar BARKPLUG V.2, ett chattbotsystem utformat för universitetsmiljöer. Med hjälp av RAG-pipelines ger systemet exakta och domänspecifika svar om campusresurser och förbättrar tillgången till information. Studien utvärderar chattbottens effektivitet med ramverk som RAG Assessment (RAGAS) och visar dess användbarhet i akademiska miljöer. Läs artikeln här.
En hämtningspipeline är en teknisk arkitektur som gör det möjligt för chatbottar att hämta, bearbeta och återfinna relevant information från externa källor som svar på användarfrågor. Den kombinerar dataingest, embedding, vektorlagring och LLM-svarsgenerering för dynamiska, kontextmedvetna svar.
RAG kombinerar styrkorna hos datahämtningssystem och stora språkmodeller (LLMs), vilket gör att chatbottar kan grunda sina svar på faktabaserad, aktuell extern data, vilket minskar hallucinationer och ökar noggrannheten.
Viktiga komponenter inkluderar dokumentingest, förbehandling, embeddinggenerering, vektorlagring, frågebehandling, datahämtning, svarsgenerering och validering efter bearbetning.
Användningsområden inkluderar kundsupport, företagskunskapshantering, e-handelsproduktinformation, vårdrådgivning, utbildning och forskning samt juridisk efterlevnadsassistans.
Utmaningar inkluderar latens vid realtidsåterhämtning, driftkostnader, datasekretess och krav på skalbarhet för att hantera stora datamängder.
Lås upp kraften i Retrieval-Augmented Generation (RAG) och extern dataintegration för att leverera intelligenta, exakta chatbottsvar. Prova FlowHunts plattform utan kod idag.
En chattbot i realtid som använder Google Sök begränsat till din egen domän, hämtar relevant webbinnehåll och utnyttjar OpenAI LLM för att besvara användarfrågo...
Chattbotar är digitala verktyg som simulerar mänsklig konversation med hjälp av AI och NLP, och erbjuder support dygnet runt, skalbarhet och kostnadseffektivite...
Frågebesvarande system med Retrieval-Augmented Generation (RAG) kombinerar informationssökning och naturlig språkxadgenerering för att förbättra stora språkmode...

