Automatisk klassificering
Automatisk klassificering automatiserar innehållskategorisering genom att analysera egenskaper och tilldela taggar med teknologier som maskininlärning, NLP och ...
6 min läsning
AI
Auto-classification
+5
Textklassificering använder NLP och maskininlärning för att automatiskt tilldela kategorier till text, vilket driver applikationer som sentimentanalys, skräppostdetektion och dataorganisation.
Textklassificering, även kallad textkategorisering eller texttaggning, är en grundläggande uppgift inom Natural Language Processing (NLP) som innebär att man tilldelar fördefinierade kategorier till textdokument. Denna metod organiserar, strukturerar och kategoriserar ostrukturerad textdata, vilket underlättar dess analys och tolkning. Textklassificering används i olika applikationer, bland annat sentimentanalys, skräppostdetektion och ämneskategorisering.
Enligt AWS fungerar textklassificering som det första steget i att organisera, strukturera och kategorisera data för vidare analys. Det möjliggör automatisk dokumentmärkning och taggning, vilket gör det möjligt för företag att effektivt hantera och analysera stora mängder textdata. Denna förmåga att automatisera dokumentmärkning minskar manuellt arbete och förbättrar datadrivna beslutsprocesser.
Textklassificering drivs av maskininlärning, där AI-modeller tränas på märkta datamängder för att lära sig mönster och samband mellan textfunktioner och deras respektive kategorier. När de väl är tränade kan dessa modeller klassificera nya och tidigare osedda textdokument med hög precision och effektivitet. Som nämnts av Towards Data Science förenklar denna process organiseringen av innehåll, vilket gör det enklare för användare att söka och navigera på webbplatser eller i applikationer.
Textklassificeringsmodeller är algoritmer som automatiserar kategoriseringen av textdata. Dessa modeller lär sig från exempel i en träningsdatamängd och tillämpar sin inlärda kunskap för att klassificera nya textinmatningar. Populära modeller inkluderar:
Support Vector Machines (SVM): En övervakad inlärningsalgoritm som är effektiv för både binär och flerkategorisk klassificering. SVM identifierar det hyperplan som bäst separerar datapunkter i olika kategorier. Metoden lämpar sig väl för tillämpningar där beslutsgränsen behöver vara tydligt definierad.
Naive Bayes: En sannolikhetsbaserad klassificerare som använder Bayes sats och antar oberoende mellan funktioner. Den är särskilt effektiv för stora datamängder tack vare sin enkelhet och effektivitet. Naive Bayes används ofta för skräppostdetektion och textanalys där snabb beräkning krävs.
Djupinlärningsmodeller: Dessa inkluderar konvolutionella neurala nätverk (CNN) och rekurrenta neurala nätverk (RNN), som kan fånga komplexa mönster i textdata genom att använda flera lager av bearbetning. Djupinlärningsmodeller är fördelaktiga för storskaliga textklassificeringsuppgifter och når ofta hög precision inom sentimentanalys och språkinlärning.
Beslutsträd och Random Forests: Trädbaserade metoder som klassificerar text genom att lära sig beslutsregler utifrån datafunktioner. Dessa modeller är fördelaktiga för sin förklarbarhet och används i olika applikationer, såsom kategorisering av kundfeedback och dokumentklassificering.
Processen för textklassificering omfattar flera steg:
Datainsamling och förberedelse: Textdata samlas in och förbehandlas. Detta steg kan innebära tokenisering, stemming och borttagning av stopwords för att rensa datan. Enligt Levity AI är textdata en värdefull tillgång för att förstå konsumentbeteende, och korrekt förbehandling är avgörande för att få ut handlingsbara insikter.
Funktionsextraktion: Transformeringen av text till numeriska representationer som maskininlärningsalgoritmer kan bearbeta. Tekniker inkluderar:
Modellträning: Maskininlärningsmodellen tränas på den märkta datamängden. Modellen lär sig att associera funktioner med deras tillhörande kategorier.
Utvärdering av modellen: Modellens prestanda utvärderas med hjälp av mått som noggrannhet, precision, recall och F1-score. Korsvalidering används ofta för att säkerställa generalisering på osedd data. AWS betonar vikten av att utvärdera textklassificeringens prestanda för att säkerställa att modellen uppnår önskad noggrannhet och tillförlitlighet.
Prediktion och driftsättning: När modellen är validerad kan den användas för att klassificera ny textdata.
Textklassificering används brett inom olika områden:
Sentimentanalys: Upptäckande av känslor som uttrycks i text, ofta använt för kundfeedback och analys av sociala medier för att mäta allmänhetens åsikter. Levity AI lyfter fram textklassificeringens roll inom social lyssning, vilket hjälper företag att förstå kundernas känslor bakom kommentarer och feedback.
Skräppostdetektion: Filtrering av oönskade och potentiellt skadliga e-postmeddelanden genom att klassificera dem som skräppost eller legitima. Automatiserad filtrering och märkning, som den som används i Gmail, är klassiska exempel på skräppostdetektion med textklassificering.
Ämneskategorisering: Organisering av innehåll i fördefinierade ämnen, användbart för nyhetsartiklar, bloggar och forskningsrapporter. Denna tillämpning förenklar innehållshantering och återhämtning, vilket förbättrar användarupplevelsen.
Kategorisering av kundsupportärenden: Automatisk vidarebefordran av supportärenden till rätt avdelning baserat på deras innehåll. Denna automation förbättrar effektiviteten i hanteringen av kundförfrågningar och minskar arbetsbördan för supportteam.
Språkdetektion: Identifiering av språket i ett textdokument för flerspråkiga applikationer. Denna kapacitet är avgörande för globala företag som verkar på olika språk och marknader.
Textklassificering medför flera utmaningar:
Datakvalitet och kvantitet: Prestandan hos textklassificeringsmodeller beror till stor del på kvaliteten och kvantiteten av träningsdatan. Otillräcklig eller brusig data kan leda till dålig modellprestanda. AWS noterar att organisationer måste säkerställa högkvalitativ datainsamling och märkning för att uppnå noggranna klassificeringsresultat.
Val av funktioner: Att välja rätt funktioner är avgörande för modellens precision. Överanpassning kan uppstå om modellen tränas på irrelevanta funktioner.
Modellens förklarbarhet: Djupinlärningsmodeller, även om de är kraftfulla, fungerar ofta som svarta lådor, vilket gör det svårt att förstå hur besluten fattas. Denna brist på transparens kan vara ett hinder för adoption inom vissa branscher där förklarbarhet är kritisk.
Skalbarhet: När mängden textdata ökar måste modeller effektivt kunna skalas för att hantera stora datamängder. Effektiva bearbetningstekniker och skalbar infrastruktur krävs för att hantera den ökande datalasten.
Textklassificering är en integrerad del av AI-driven automation](https://www.flowhunt.io#:~:text=automation “Build AI tools and chatbots with FlowHunt’s no-code platform. Explore templates, components, and seamless automation. Book a demo today!”) och [chattbottar. Genom att automatiskt kategorisera och tolka textinmatningar kan chattbottar ge relevanta svar, förbättra kundinteraktioner och effektivisera affärsprocesser. Inom AI-automation möjliggör textklassificering att system kan bearbeta och analysera stora mängder data med minimal mänsklig inblandning, vilket förbättrar effektiviteten och beslutsfattandet.
Vidare har framsteg inom NLP och djupinlärning gett chattbottar sofistikerade textklassificeringsmöjligheter, vilket gör att de kan förstå kontext, känsla och avsikt, och därmed erbjuda mer personliga och precisa interaktioner med användare. AWS menar att integration av textklassificering i AI-applikationer kan förbättra användarupplevelsen markant genom att tillhandahålla snabb och relevant information.
Forskning om textklassificering
Textklassificering är en kritisk uppgift inom naturlig språkbehandling som innebär att automatiskt kategorisera text i fördefinierade etiketter. Nedan följer sammanfattningar av aktuella vetenskapliga artiklar som ger insikter i olika metoder och utmaningar kopplade till textklassificering:
Model and Evaluation: Towards Fairness in Multilingual Text Classification
Författare: Nankai Lin, Junheng He, Zhenghang Tang, Dong Zhou, Aimin Yang
Publicerad: 2023-03-28
Denna artikel tar upp utmaningen med partiskhet i flerspråkiga textklassificeringsmodeller. Den föreslår ett avpartiskningsramverk med kontrastiv inlärning som inte är beroende av externa språkresurser. Ramverket inkluderar moduler för flerspråkig textrepresentation, språkfusion, textavpartiskning och klassificering. Ett nytt flerdimensionellt rättvisautvärderingsramverk introduceras också, med syfte att förbättra rättvisan mellan olika språk. Detta arbete är viktigt för att förbättra rättvisa och precision i flerspråkiga textklassificeringsmodeller. Läs mer
Text Classification using Association Rule with a Hybrid Concept of Naive Bayes Classifier and Genetic Algorithm
Författare: S. M. Kamruzzaman, Farhana Haider, Ahmed Ryadh Hasan
Publicerad: 2010-09-25
Denna forskning presenterar ett innovativt tillvägagångssätt för textklassificering med hjälp av associationsregler kombinerat med Naive Bayes och genetiska algoritmer. Metoden härleder funktioner från förklassificerade dokument med hjälp av ordrelationer snarare än enskilda ord. Integrationen av genetiska algoritmer förbättrar den slutliga klassificeringsprestandan. Resultaten visar effektiviteten i detta hybrida angreppssätt för att uppnå framgångsrik textklassificering. Läs mer
Text Classification: A Perspective of Deep Learning Methods
Författare: Zhongwei Wan
Publicerad: 2023-09-24
Med den exponentiella tillväxten av internetdata belyser denna artikel vikten av djupinlärningsmetoder för textklassificering. Den diskuterar olika djupinlärningstekniker som förbättrar precisionen och effektiviteten vid kategorisering av komplexa texter. Studien betonar den föränderliga rollen för djupinlärning i hantering av stora datamängder och leverans av exakta klassificeringsresultat. Läs mer
Textklassificering är en Natural Language Processing (NLP)-uppgift där fördefinierade kategorier tilldelas textdokument, vilket möjliggör automatiserad organisering, analys och tolkning av ostrukturerad data.
Vanliga modeller inkluderar Support Vector Machines (SVM), Naive Bayes, djupinlärningsmodeller som CNN och RNN, samt träd-baserade metoder såsom beslutsträd och Random Forests.
Textklassificering används ofta inom sentimentanalys, skräppostdetektion, ämneskategorisering, automatiserad ärendehantering för kundsupport och språkdetektion.
Utmaningar inkluderar att säkerställa datakvalitet och kvantitet, korrekt val av funktioner, modellernas förklarbarhet och skalbarhet för att hantera stora mängder data.
Textklassificering gör det möjligt för AI-driven automation och chattbottar att tolka, kategorisera och svara på användarinmatningar effektivt, vilket förbättrar kundinteraktioner och affärsprocesser.
Börja bygga smarta chattbottar och AI-verktyg som utnyttjar automatiserad textklassificering för att öka effektiviteten och insikten.
Automatisk klassificering automatiserar innehållskategorisering genom att analysera egenskaper och tilldela taggar med teknologier som maskininlärning, NLP och ...
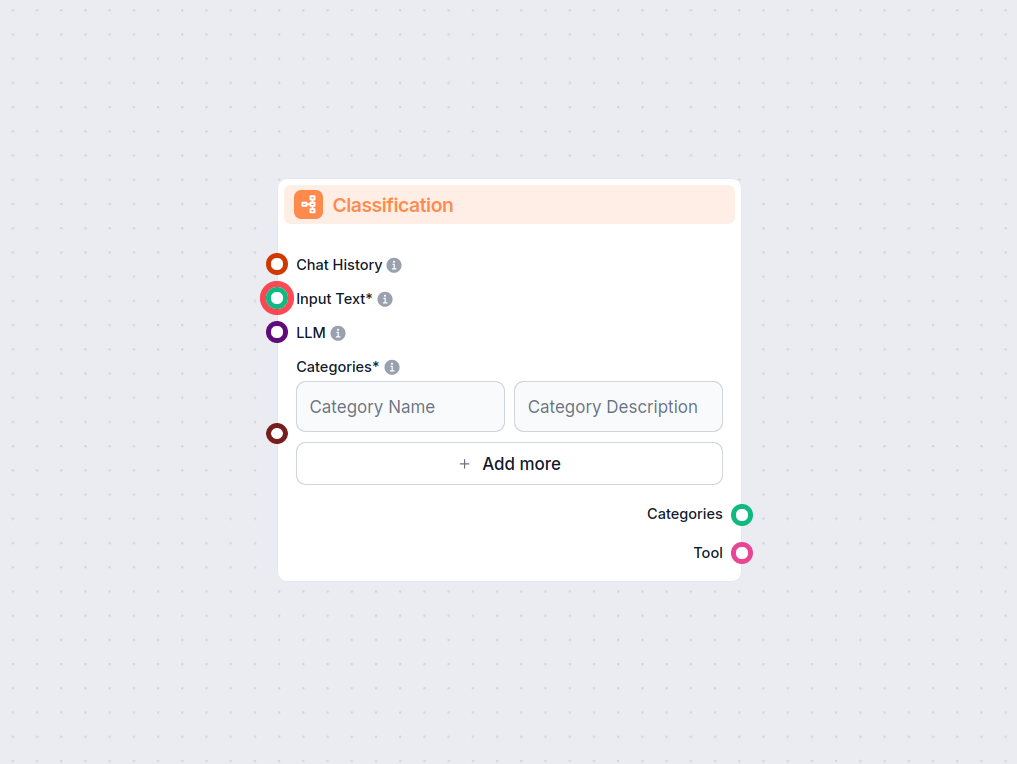
Lås upp automatiserad textkategorisering i dina arbetsflöden med komponenten Textklassificering för FlowHunt. Klassificera enkelt inmatad text i användardefinie...
Upptäck den viktiga rollen som AI-intentklassificering spelar för att förbättra användarinteraktioner med teknik, effektivisera kundsupport och förenkla affärsp...