Transformer
En transformer-modell är en typ av neuralt nätverk som är särskilt utformad för att hantera sekventiell data, såsom text, tal eller tidsseriedata. Till skillnad...
3 min läsning
Transformer
Neural Networks
+3
Transformatorer är banbrytande neurala nätverk som utnyttjar självuppmärksamhet för parallell databehandling och driver modeller som BERT och GPT inom NLP, bildanalys och mycket mer.
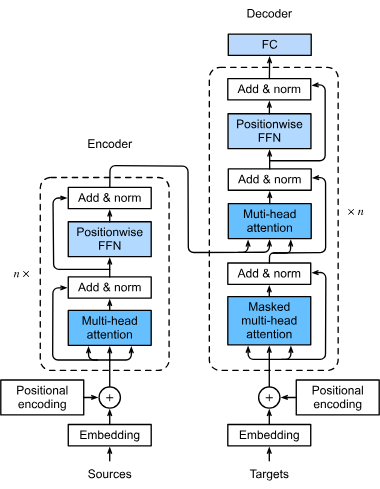
Det första steget i en transformator-modells processkedja innebär att konvertera ord eller tokens i en indatasekvens till numeriska vektorer, så kallade embeddingar. Dessa embeddingar fångar semantiska betydelser och är avgörande för att modellen ska kunna förstå relationerna mellan tokens. Denna transformation är avgörande eftersom den gör det möjligt för modellen att bearbeta textdata i matematisk form.
Transformatorer bearbetar inte data sekventiellt per automatik; därför används positionell kodning för att införa information om varje tokens position i sekvensen. Detta är viktigt för att bibehålla ordningen i sekvensen, vilket är avgörande för uppgifter som maskinöversättning där kontext kan bero på ordens ordningsföljd.
Multi-head attention-mekanismen är en sofistikerad komponent i transformatorer som gör det möjligt för modellen att fokusera på olika delar av indatasekvensen samtidigt. Genom att beräkna flera uppmärksamhetsvärden kan modellen fånga olika relationer och beroenden i datan, vilket ökar dess förmåga att förstå och generera komplexa datamönster.
Transformatorer följer vanligtvis en encoder-decoder-arkitektur:
Efter uppmärksamhetsmekanismen passerar datan genom feedforward-neurala nätverk, som applicerar icke-linjära transformationer på datan och hjälper modellen att lära sig komplexa mönster. Dessa nätverk bearbetar vidare datan för att förfina modellens utdata.
Dessa tekniker används för att stabilisera och snabba upp träningsprocessen. Lager-normalisering säkerställer att utdata hålls inom ett visst intervall, vilket underlättar effektiv träning av modellen. Residualkopplingar gör att gradienterna kan flöda genom nätverken utan att försvagas, vilket förbättrar träningen av djupa neurala nätverk.
Transformatorer arbetar på sekvenser av data, som kan vara ord i en mening eller annan sekventiell information. De tillämpar självuppmärksamhet för att avgöra relevansen av varje del av sekvensen i förhållande till andra, vilket gör att modellen kan fokusera på avgörande element som påverkar resultatet.
I självuppmärksamhet jämförs varje token i sekvensen med alla andra tokens för att beräkna uppmärksamhetsvärden. Dessa värden anger betydelsen av varje token i kontexten av de andra, så att modellen kan fokusera på de mest relevanta delarna av sekvensen. Detta är avgörande för att förstå kontext och betydelse i språkuppgifter.
Dessa är byggstenarna i en transformator-modell och består av självuppmärksamhets- och feedforward-lager. Flera block staplas för att bilda djupinlärningsmodeller som kan fånga invecklade mönster i data. Denna modulära design gör att transformatorer kan skalas effektivt med uppgiftens komplexitet.
Transformatorer är mer effektiva än RNN och CNN tack vare deras förmåga att bearbeta hela sekvenser på en gång. Denna effektivitet möjliggör uppskalning till mycket stora modeller, såsom GPT-3 med 175 miljarder parametrar. Transformatorernas skalbarhet gör att de kan hantera enorma datamängder effektivt.
Traditionella modeller har svårt med långväga beroenden på grund av sin sekventiella natur. Transformatorer övervinner denna begränsning genom självuppmärksamhet, som kan ta hänsyn till alla delar av sekvensen samtidigt. Detta gör dem särskilt effektiva för uppgifter som kräver förståelse för kontext över långa textsekvenser.
Även om de ursprungligen designades för NLP-uppgifter har transformatorer anpassats för olika tillämpningar, inklusive datorseende, proteinveckning och även tidsserieförutsägelser. Denna mångsidighet visar transformatorernas breda användningsområde över olika domäner.
Transformatorer har avsevärt förbättrat prestandan i NLP-uppgifter som översättning, sammanfattning och sentimentanalys. Modeller som BERT och GPT är framstående exempel som utnyttjar transformatorarkitektur för att förstå och generera text på ett mänskligt sätt, och sätter nya standarder inom NLP.
Vid maskinöversättning utmärker sig transformatorer genom att förstå ordens kontext i en mening, vilket möjliggör mer precisa översättningar jämfört med tidigare metoder. Deras förmåga att bearbeta hela meningar på en gång ger mer sammanhängande och kontextuellt korrekta översättningar.
Transformatorer kan modellera aminosyrors sekvenser i proteiner och bistå vid prediktion av proteinstrukturer, vilket är avgörande för läkemedelsutveckling och förståelse av biologiska processer. Denna tillämpning understryker potentialen hos transformatorer inom vetenskaplig forskning.
Genom att anpassa transformatorarkitekturen är det möjligt att förutsäga framtida värden i tidsseriedata, såsom prognoser för elförbrukning, genom att analysera tidigare sekvenser. Detta öppnar nya möjligheter för transformatorer inom områden som finans och resursplanering.
BERT-modeller är utformade för att förstå kontexten av ett ord genom att titta på dess omgivande ord, vilket gör dem mycket effektiva för uppgifter som kräver förståelse av ordrelationer i en mening. Detta bidirektionella tillvägagångssätt gör att BERT kan fånga kontext mer effektivt än enkelriktade modeller.
GPT-modeller är autoregressiva och genererar text genom att förutsäga nästa ord i en sekvens baserat på de föregående orden. De används i stor utsträckning för tillämpningar som textkomplettering och dialoggenerering, och visar sin förmåga att producera text som liknar mänskligt språk.
Transformatorer, som ursprungligen utvecklades för NLP, har anpassats för datorseende-uppgifter. Vision transformers bearbetar bilddata som sekvenser och gör det möjligt att tillämpa transformator-tekniker på visuella indata. Denna anpassning har lett till framsteg inom bildigenkänning och bildbehandling.
Träning av stora transformator-modeller kräver betydande datorkraft, ofta med omfattande datamängder och kraftfull hårdvara som GPU:er. Detta innebär en utmaning vad gäller kostnad och tillgänglighet för många organisationer.
När transformatorer blir allt vanligare blir frågor som partiskhet i AI-modeller och etisk användning av AI-genererat innehåll allt viktigare. Forskare arbetar med metoder för att minska dessa problem och säkerställa ansvarsfull AI-utveckling, vilket understryker behovet av etiska ramverk inom AI-forskning.
Transformatorernas mångsidighet fortsätter att öppna nya möjligheter för forskning och tillämpning, från att förbättra AI-drivna chatbotar till att förbättra dataanalys inom områden som hälsa och finans. Transformatorernas framtid rymmer spännande möjligheter till innovation i olika branscher.
Sammanfattningsvis representerar transformatorer ett betydande framsteg inom AI-teknologi och erbjuder oöverträffade möjligheter för bearbetning av sekventiell data. Deras innovativa arkitektur och effektivitet har satt en ny standard i området och driver AI-tillämpningar till nya höjder. Oavsett om det gäller språkförståelse, vetenskaplig forskning eller visuell databehandling fortsätter transformatorer att omdefiniera vad som är möjligt inom artificiell intelligens.
Transformatorer har revolutionerat området artificiell intelligens, särskilt inom naturlig språkbehandling och förståelse. Artikeln “AI Thinking: A framework for rethinking artificial intelligence in practice” av Denis Newman-Griffis (publicerad 2024) utforskar ett nytt konceptuellt ramverk kallat AI Thinking. Detta ramverk modellerar viktiga beslut och överväganden i AI-användning ur tvärvetenskapliga perspektiv, och adresserar kompetenser i att motivera AI-användning, formulera AI-metoder och placera AI i sociotekniska sammanhang. Syftet är att överbrygga klyftor mellan akademiska discipliner och omforma framtiden för AI i praktiken. Läs mer.
En annan viktig insats är “Artificial intelligence and the transformation of higher education institutions” av Evangelos Katsamakas m.fl. (publicerad 2024), som använder ett komplexa system-perspektiv för att kartlägga de kausala återkopplingsmekanismerna för AI-transformation inom högre utbildningsinstitutioner (HEIs). Studien diskuterar de krafter som driver AI-transformation och dess påverkan på värdeskapande, och betonar behovet för HEIs att anpassa sig till AI-teknologiska framsteg samtidigt som akademisk integritet och anställningsförändringar hanteras. Läs mer.
Inom mjukvaruutveckling undersöker artikeln “Can Artificial Intelligence Transform DevOps?” av Mamdouh Alenezi och kollegor (publicerad 2022) sambandet mellan AI och DevOps. Studien lyfter fram hur AI kan förbättra DevOps-processernas funktionalitet och möjliggöra effektiv programvaruleverans. Den understryker de praktiska konsekvenserna för mjukvaruutvecklare och företag i att utnyttja AI för att transformera DevOps-praktiker. Läs mer
Transformatorer är en neurala nätverksarkitektur som introducerades 2017 och använder självuppmärksamhetsmekanismer för parallell bearbetning av sekventiell data. De har revolutionerat artificiell intelligens, särskilt inom naturlig språkbehandling och datorseende.
Till skillnad från RNN och CNN bearbetar transformatorer alla element i en sekvens samtidigt med hjälp av självuppmärksamhet, vilket möjliggör högre effektivitet, skalbarhet och förmåga att fånga långväga beroenden.
Transformatorer används i stor utsträckning i NLP-uppgifter som översättning, sammanfattning och sentimentanalys, samt inom datorseende, proteinstrukturprediktion och tidsserieförutsägelser.
Anmärkningsvärda transformator-modeller inkluderar BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformers) och Vision Transformers för bildbearbetning.
Transformatorer kräver betydande datorkraft för att träna och implementera. De väcker också etiska överväganden såsom potentiella fördomar i AI-modeller och ansvarsfull användning av genererat AI-innehåll.
Smarta chatbotar och AI-verktyg under samma tak. Koppla intuitiva block för att förvandla dina idéer till automatiserade Flows.
En transformer-modell är en typ av neuralt nätverk som är särskilt utformad för att hantera sekventiell data, såsom text, tal eller tidsseriedata. Till skillnad...
En Generativ Förtränad Transformator (GPT) är en AI-modell som använder djupinlärningstekniker för att producera text som nära efterliknar mänskligt skrivande. ...
Transfer Learning är en kraftfull AI/ML-teknik som anpassar förtränade modeller till nya uppgifter, förbättrar prestanda med begränsad data och ökar effektivite...