
Skapa din egen AI-drivna Schema.org-generator på några minuter
Generera direkt schema.org i JSON-format. Lär dig hur du skapar din egen AI Schema.org-generator i FlowHunt.
2 min läsning
AI
Schema.org
+4
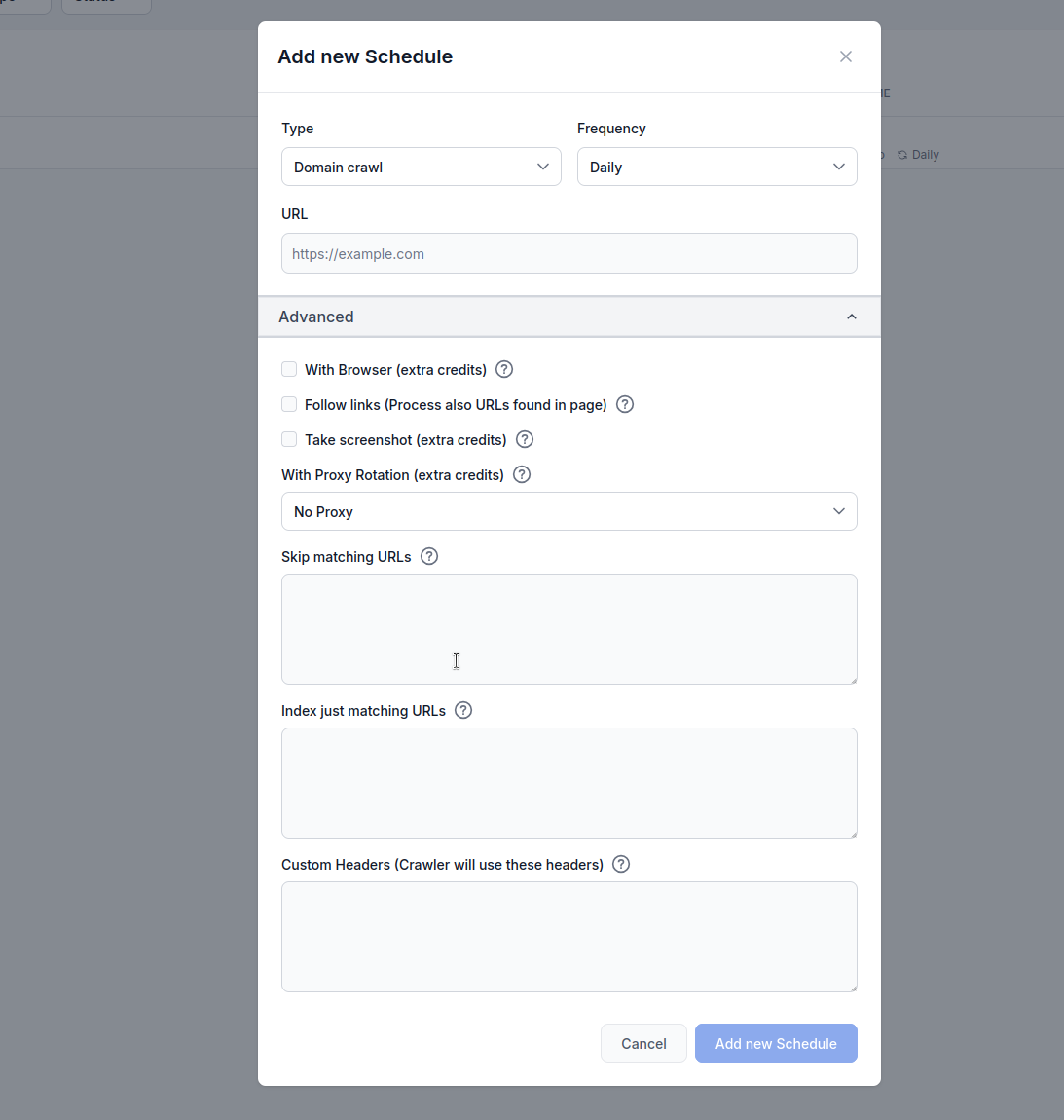
Lär dig att ställa in automatiserade scheman för att genomsöka webbplatser, sitemaps, domäner och YouTube-kanaler så att din AI Agent kunskapsbas alltid är uppdaterad.
FlowHunts schemaläggningsfunktion gör det möjligt att automatisera genomsökning och indexering av webbplatser, sitemaps, domäner och YouTube-kanaler. Det säkerställer att din AI Agents kunskapsbas hålls aktuell med nytt innehåll utan manuell insats.
Automatiserad genomsökning:
Ställ in återkommande genomsökningar som körs dagligen, veckovis, månadsvis eller årligen för att hålla din kunskapsbas uppdaterad.
Flera genomsökningstyper:
Välj mellan Domängenomsökning, Sitemap-genomsökning, URL-genomsökning eller YouTube-kanalsgenomsökning beroende på din innehållskälla.
Avancerade alternativ:
Konfigurera webbläsarrendering, länkföljning, skärmdumpar, proxy-rotation och URL-filtrering för optimala resultat.
Typ: Välj din genomsökningsmetod:
Frekvens: Ställ in hur ofta genomsökningen ska köras:
URL: Ange mål-URL, domän eller YouTube-kanal att genomsöka
Med webbläsare (extra krediter): Aktivera när du genomsöker JavaScript-tunga webbplatser som kräver fullständig webbläsarrendering. Detta alternativ är långsammare och dyrare men nödvändigt för sidor som laddar innehåll dynamiskt.
Följ länkar (extra krediter): Bearbeta ytterligare URL:er som hittas inom sidor. Användbart när sitemaps inte innehåller alla URL:er, men kan förbruka mycket krediter då även upptäckta länkar genomsöks.
Ta skärmdump (extra krediter): Ta visuella skärmdumpar under genomsökningen. Hjälpsamt för webbplatser utan og:images eller de som kräver visuell kontext för AI-bearbetning.
Med proxy-rotation (extra krediter): Rotera IP-adresser för varje förfrågan för att undvika upptäckt av webbapplikationsbrandväggar (WAF) eller antibot-system.
Hoppa över matchande URL:er: Ange strängar (en per rad) för att exkludera URL:er som innehåller dessa mönster från genomsökningen. Exempel:
/admin/
/login
.pdf
Detta exempel förklarar vad som händer när du använder FlowHunts schemaläggningsfunktion för att genomsöka domänen flowhunt.io medan du anger /blog som en matchande URL att hoppa över i inställningarna för URL-filtrering.
Konfigurationsinställningar
flowhunt.io/blogVad händer
Genomsökningsstart:
flowhunt.io och riktar sig mot alla tillgängliga sidor på domänen (t.ex. flowhunt.io, flowhunt.io/features, flowhunt.io/pricing osv.).URL-filtrering tillämpas:
/blog./blog (t.ex. flowhunt.io/blog, flowhunt.io/blog/post1, flowhunt.io/blog/category) utesluts från genomsökningen.flowhunt.io/about, flowhunt.io/contact eller flowhunt.io/docs, genomsöks eftersom de inte matchar /blog.Genomsökningskörning:
flowhunt.io och indexerar deras innehåll till din AI Agents kunskapsbas.Resultat:
flowhunt.io, exklusive allt under sökvägen /blog./blog) utan manuell insats.Indexera endast matchande URL:er: Ange strängar (en per rad) för att endast genomsöka URL:er som innehåller dessa mönster. Exempel:
/blog/
/articles/
/knowledge/
Konfigurationsinställningar
flowhunt.io/blog/
/articles/
/knowledge/
Genomsökningsstart:
flowhunt.io och riktar sig mot alla tillgängliga sidor på domänen (t.ex. flowhunt.io, flowhunt.io/blog, flowhunt.io/articles osv.).URL-filtrering tillämpas:
/blog/, /articles/ och /knowledge/.flowhunt.io/blog/post1, flowhunt.io/articles/news, flowhunt.io/knowledge/guide) inkluderas i genomsökningen.flowhunt.io/about, flowhunt.io/pricing eller flowhunt.io/contact, utesluts eftersom de inte matchar angivna mönster.Genomsökningskörning:
/blog/, /articles/ eller /knowledge/ och indexerar deras innehåll till din AI Agents kunskapsbas.Resultat:
flowhunt.io-sidor under sökvägarna /blog/, /articles/ och /knowledge/.Anpassade headers:
Lägg till anpassade HTTP headers för genomsökningsförfrågningar. Formatera som HEADER=Värde (en per rad):
Den här funktionen är mycket användbar för att anpassa genomsökningar till specifika webbplatskrav. Genom att aktivera anpassade headers kan användare autentisera förfrågningar för att få tillgång till skyddat innehåll, imitera specifika webbläsarbeteenden eller uppfylla en webbplats API eller åtkomstpolicies. Till exempel kan en Authorization-header ge tillgång till skyddade sidor, medan en anpassad User-Agent kan hjälpa till att undvika bot-detektering eller säkerställa kompatibilitet med sidor som begränsar vissa genomsökare. Denna flexibilitet ger mer exakt och omfattande datainsamling, vilket gör det enklare att indexera relevant innehåll till en AI Agents kunskapsbas samtidigt som webbplatsens säkerhets- eller åtkomstprotokoll respekteras.
MYHEADER=Valfritt värde
Authorization=Bearer token123
User-Agent=Custom crawler
Navigera till Scheman i din FlowHunt-instrumentpanel
Klicka på “Lägg till nytt schema”
Konfigurera grundinställningar:
Expandera avancerade alternativ vid behov:
Klicka på “Lägg till nytt schema” för att aktivera
För de flesta webbplatser:
För JavaScript-tunga sidor:
För stora webbplatser:
För e-handel eller dynamiskt innehåll:
Avancerade funktioner förbrukar extra krediter:
Övervaka din kreditförbrukning och justera scheman utifrån dina behov och din budget.
Genomsökningsfel:
För många/för få sidor:
Saknat innehåll:
Generera direkt schema.org i JSON-format. Lär dig hur du skapar din egen AI Schema.org-generator i FlowHunt.
Scheman-funktionen i FlowHunt låter dig regelbundet genomsöka domäner och YouTube-kanaler, så att dina chatbottar och flöden hålls uppdaterade med den senaste i...

Lär dig hur du automatiskt genererar omfattande, SEO-optimerade ordlistesidor med hjälp av AI-agenter och arbetsflödesautomation i FlowHunt. Upptäck hela proces...