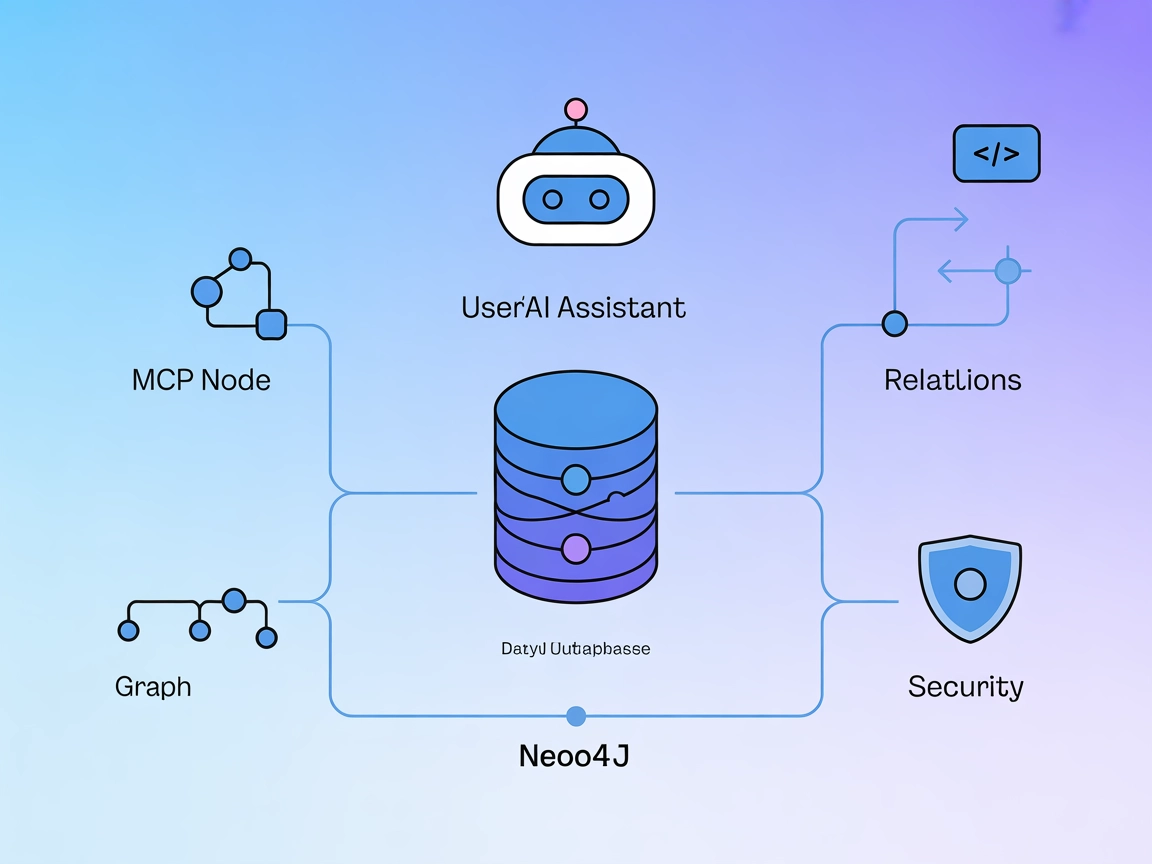
Neo4j MCP Server-integration
Neo4j MCP-servern fungerar som en bro mellan AI-assistenter och Neo4j grafdatabasen, vilket möjliggör säkra, naturliga språkbaserade grafoperationer, Cypher-frå...
4 min läsning
AI
Graph Database
+5
Neo4j MCP-servern fungerar som en bro mellan AI-assistenter och Neo4j grafdatabasen, vilket möjliggör säkra, naturliga språkbaserade grafoperationer, Cypher-frå...
NASA MCP Server tillhandahåller ett enhetligt gränssnitt för AI-modeller och utvecklare att komma åt över 20 NASA-datakällor. Den standardiserar hämtning, bearb...
Data Exploration MCP Server kopplar AI-assistenter till externa datamängder för interaktiv analys. Den ger användare möjlighet att utforska CSV- och Kaggle-data...
MCP Code Executor MCP Server möjliggör för FlowHunt och andra LLM-drivna verktyg att säkert köra Python-kod i isolerade miljöer, hantera beroenden och dynamiskt...
Reexpress MCP-server tillför statistisk verifiering till LLM-arbetsflöden. Med hjälp av Similarity-Distance-Magnitude (SDM)-estimatorn levererar den robusta til...
Databricks Genie MCP-server möjliggör för stora språkmodeller att interagera med Databricks-miljöer via Genie API, med stöd för konversationell datautforskning,...
JupyterMCP möjliggör sömlös integration av Jupyter Notebook (6.x) med AI-assistenter via Model Context Protocol. Automatisera kodkörning, hantera celler och häm...
En AI-dataanalytiker kombinerar traditionella dataanalysfärdigheter med artificiell intelligens (AI) och maskininlärning (ML) för att utvinna insikter, förutsäg...
Anaconda är en omfattande, öppen källkod-distribution av Python och R, utformad för att förenkla paketxadhantering och distribution för vetenskaplig beräkning, ...
Area Under the Curve (AUC) är en grundläggande mätvärde inom maskininlärning som används för att utvärdera prestandan hos binära klassificeringsmodeller. Det kv...
Ett beslutsträd är ett kraftfullt och intuitivt verktyg för beslutsfattande och prediktiv analys, som används både för klassificerings- och regressionsuppgifter...
BigML är en plattform för maskininlärning som är utformad för att förenkla skapandet och driftsättningen av prediktiva modeller. Grundad 2011, har dess uppdrag ...
Datastädning är den avgörande processen för att upptäcka och åtgärda fel eller inkonsekvenser i data för att förbättra dess kvalitet, vilket säkerställer noggra...
Datautvinning är en sofistikerad process för att analysera stora mängder rådata för att upptäcka mönster, relationer och insikter som kan informera affärsstrate...
Dimensionsreduktion är en avgörande teknik inom databehandling och maskininlärning, som minskar antalet inmatningsvariabler i en datamängd samtidigt som viktig ...
Utforska hur Feature Engineering och Extraktion förbättrar AI-modellers prestanda genom att omvandla rådata till värdefulla insikter. Upptäck viktiga tekniker s...
Google Colaboratory (Google Colab) är en molnbaserad Jupyter-notebookplattform från Google som gör det möjligt för användare att skriva och köra Python-kod i we...
Gradient Boosting är en kraftfull ensemblemetod inom maskininlärning för regression och klassificering. Den bygger modeller sekventiellt, vanligtvis med besluts...
Jupyter Notebook är en öppen källkodsbaserad webbapplikation som gör det möjligt för användare att skapa och dela dokument med levande kod, ekvationer, visualis...
Justerad R-kvadrat är ett statistiskt mått som används för att utvärdera hur väl en regressionsmodell passar data, där hänsyn tas till antalet prediktorer för a...
K-Means-klustring är en populär osuperviserad maskininlärningsalgoritm för att dela upp datamängder i ett fördefinierat antal distinkta, icke-överlappande klust...
K-närmsta grannar (KNN) är en icke-parametrisk, övervakad inlärningsalgoritm som används för klassificerings- och regressionsuppgifter inom maskininlärning. Den...
Kaggle är en onlinegemenskap och plattform för datavetare och maskininlärningsingenjörer att samarbeta, lära sig, tävla och dela insikter. Kaggle, som förvärvad...
Kausalinferens är en metodologisk ansats som används för att fastställa orsak-och-verkan-relationer mellan variabler, avgörande inom vetenskapen för att förstå ...
En AI-klassificerare är en maskininlärningsalgoritm som tilldelar klassetiketter till indata, och kategoriserar information i fördefinierade klasser baserat på ...
Linjär regression är en grundläggande analytisk teknik inom statistik och maskininlärning, som modellerar sambandet mellan beroende och oberoende variabler. Kän...
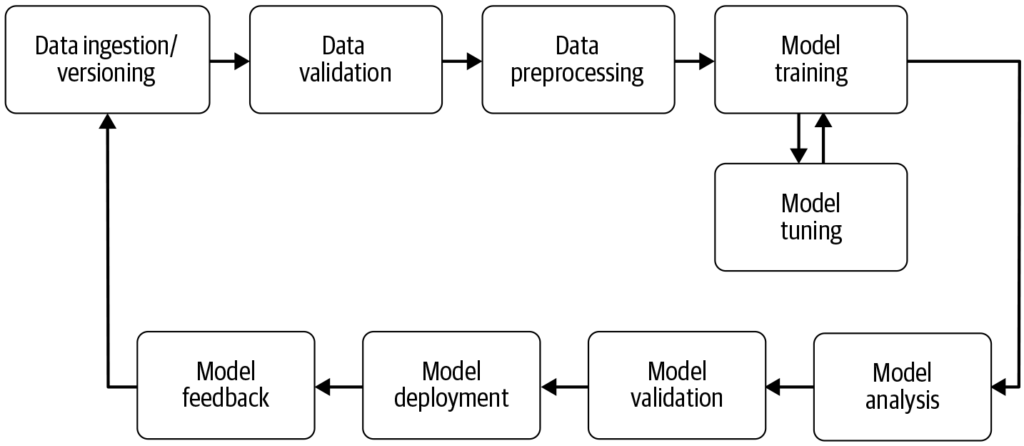
En maskininlärningspipeline är ett automatiserat arbetsflöde som effektiviserar och standardiserar utveckling, träning, utvärdering och driftsättning av maskini...
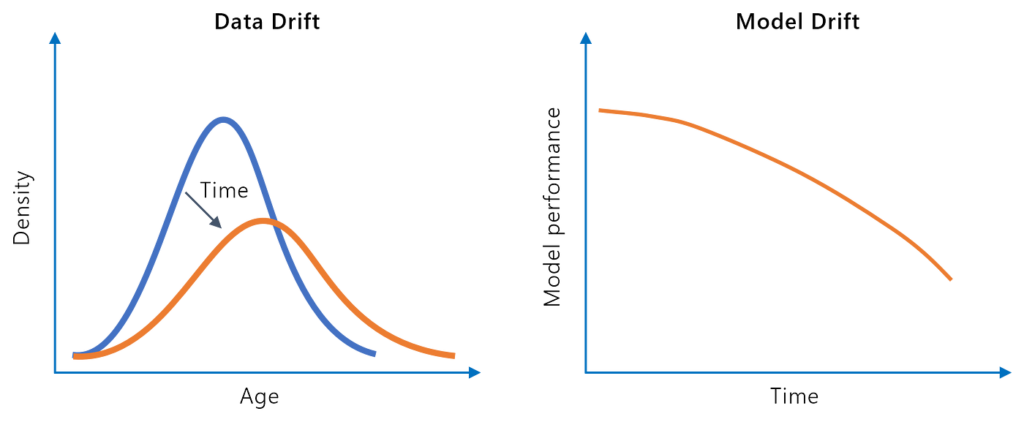
Modellförändring, eller modelldegeneration, syftar på den nedgång i en maskininlärningsmodells prediktiva prestanda över tid på grund av förändringar i den verk...
Modellkedjning är en maskininlärningsteknik där flera modeller länkas sekventiellt, där varje modells utdata fungerar som nästa modells indata. Denna metod ökar...
NumPy är ett open source-bibliotek för Python som är avgörande för numeriska beräkningar och erbjuder effektiva arrayoperationer och matematiska funktioner. Det...
Pandas är ett öppen källkod-bibliotek för datamanipulering och analys i Python, känt för sin mångsidighet, robusta datastrukturer och användarvänlighet vid hant...
Utforska partiskhet inom AI: förstå dess källor, påverkan på maskininlärning, verkliga exempel och strategier för att minska partiskhet för att bygga rättvisa o...
Prediktiv modellering är en avancerad process inom data science och statistik som förutspår framtida utfall genom att analysera historiska datamönster. Den anvä...
Scikit-learn är ett kraftfullt, öppet källkodsramverk för maskininlärning i Python som erbjuder enkla och effektiva verktyg för prediktiv dataanalys. Brett anvä...
Semisupervised inlärning (SSL) är en maskininlärningsteknik som utnyttjar både märkta och omärkta data för att träna modeller, vilket gör det idealiskt när det ...