Hugging Face Transformers
Hugging Face Transformers är ett ledande open source-bibliotek för Python som gör det enkelt att implementera Transformer-modeller för maskininlärningsuppgifter...
4 min läsning
AI
Machine Learning
+4
Hugging Face Transformers är ett ledande open source-bibliotek för Python som gör det enkelt att implementera Transformer-modeller för maskininlärningsuppgifter...
Hyperparametertuning är en grundläggande process inom maskininlärning för att optimera modellens prestanda genom att justera parametrar som inlärningshastighet ...
En inbäddningsvektor är en tät numerisk representation av data i ett flerdimensionellt rum, som fångar semantiska och kontextuella relationer. Lär dig hur inbäd...
Informationsåtervinning använder AI, NLP och maskininlärning för att effektivt och noggrant hämta data som uppfyller användarens krav. Grundläggande för webbsök...
En inlärningskurva inom artificiell intelligens är en grafisk representation som illustrerar sambandet mellan en modells inlärningsprestanda och variabler som d...
Upptäck vad en Insight Engine är—en avancerad, AI-driven plattform som förbättrar datasökning och analys genom att förstå kontext och avsikt. Lär dig hur Insigh...
Instruktionsanpassning är en teknik inom AI som finjusterar stora språkmodeller (LLM:er) på instruktion-svar-par, vilket förbättrar deras förmåga att följa mäns...
En intelligent agent är en autonom enhet utformad för att uppfatta sin omgivning via sensorer och agera på denna miljö med hjälp av ställdon, utrustad med artif...
Upptäck den viktiga rollen som AI-intentklassificering spelar för att förbättra användarinteraktioner med teknik, effektivisera kundsupport och förenkla affärsp...
Jupyter Notebook är en öppen källkodsbaserad webbapplikation som gör det möjligt för användare att skapa och dela dokument med levande kod, ekvationer, visualis...
Justerad R-kvadrat är ett statistiskt mått som används för att utvärdera hur väl en regressionsmodell passar data, där hänsyn tas till antalet prediktorer för a...
K-Means-klustring är en populär osuperviserad maskininlärningsalgoritm för att dela upp datamängder i ett fördefinierat antal distinkta, icke-överlappande klust...
K-närmsta grannar (KNN) är en icke-parametrisk, övervakad inlärningsalgoritm som används för klassificerings- och regressionsuppgifter inom maskininlärning. Den...
Kaggle är en onlinegemenskap och plattform för datavetare och maskininlärningsingenjörer att samarbeta, lära sig, tävla och dela insikter. Kaggle, som förvärvad...
Kausalinferens är en metodologisk ansats som används för att fastställa orsak-och-verkan-relationer mellan variabler, avgörande inom vetenskapen för att förstå ...
Keras är ett kraftfullt och användarvänligt öppen källkods-API på hög nivå för neurala nätverk, skrivet i Python och kan köras ovanpå TensorFlow, CNTK eller The...
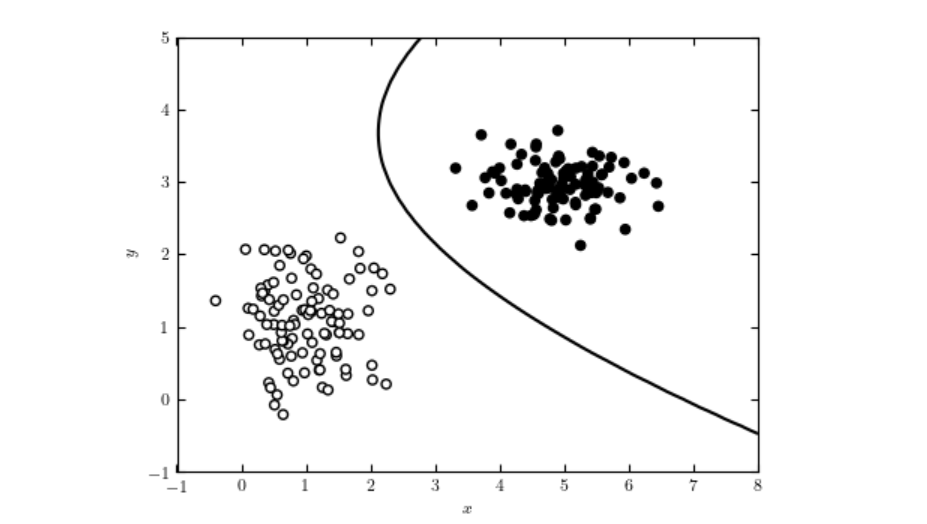
En AI-klassificerare är en maskininlärningsalgoritm som tilldelar klassetiketter till indata, och kategoriserar information i fördefinierade klasser baserat på ...
Klustring är en oövervakad maskininlärningsteknik som grupperar liknande datapunkter, vilket möjliggör utforskande dataanalys utan märkta data. Lär dig om typer...
KNIME (Konstanz Information Miner) är en kraftfull öppen källkodsplattform för dataanalys som erbjuder visuella arbetsflöden, sömlös dataintegration, avancerad ...
Kognitiv databehandling representerar en transformativ teknologimodell som simulerar mänskliga tankeprocesser i komplexa scenarier. Den integrerar AI och signal...
En konfusionsmatris är ett verktyg inom maskininlärning för att utvärdera prestandan hos klassificeringsmodeller. Den redovisar sanna/falska positiva och negati...
Konvergens inom AI avser den process genom vilken maskininlärnings- och djupinlärningsmodeller når ett stabilt tillstånd genom iterativ inlärning, vilket säkers...
Konversationell AI avser teknologier som möjliggör för datorer att simulera mänskliga samtal med hjälp av NLP, maskininlärning och andra språkteknologier. Det d...
En korpus (plural: korpora) inom AI avser en stor, strukturerad samling av texter eller ljuddata som används för att träna och utvärdera AI-modeller. Korpora är...
Korreferensupplösning är en grundläggande NLP-uppgift som identifierar och länkar uttryck i text som refererar till samma enhet, avgörande för maskinell förståe...
Korsentropi är ett centralt begrepp inom både informationsteori och maskininlärning, och fungerar som ett mått för att mäta avvikelsen mellan två sannolikhetsfö...
Korsvalidering är en statistisk metod som används för att utvärdera och jämföra maskininlärningsmodeller genom att dela upp data i tränings- och valideringsupps...
Upptäck kostnaderna som är förknippade med att träna och driftsätta stora språkmodeller (LLM) som GPT-3 och GPT-4, inklusive beräknings-, energi- och hårdvaruut...
Kubeflow är en öppen källkodsplattform för maskininlärning (ML) på Kubernetes, som förenklar implementering, hantering och skalning av ML-arbetsflöden. Den erbj...
LightGBM, eller Light Gradient Boosting Machine, är ett avancerat ramverk för gradientförstärkning utvecklat av Microsoft. Utformat för högpresterande maskininl...
Linjär regression är en grundläggande analytisk teknik inom statistik och maskininlärning, som modellerar sambandet mellan beroende och oberoende variabler. Kän...
Loggförlust, eller logaritmisk/korsentropiförlust, är ett nyckelmått för att utvärdera prestandan hos maskininlärningsmodeller—särskilt för binär klassificering...
Logistisk regression är en statistisk och maskininlärningsmetod som används för att förutsäga binära utfall från data. Den uppskattar sannolikheten för att en h...
Maskininlärning (ML) är en underkategori av artificiell intelligens (AI) som gör det möjligt för maskiner att lära sig av data, identifiera mönster, göra föruts...
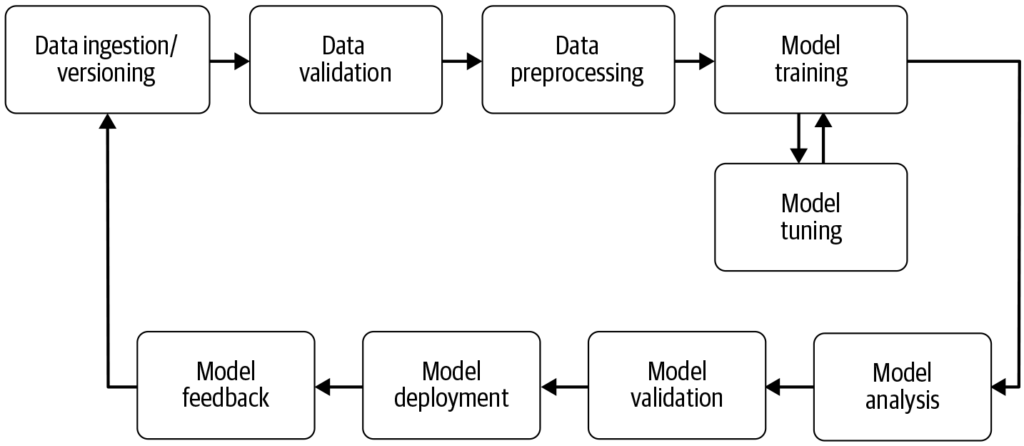
En maskininlärningspipeline är ett automatiserat arbetsflöde som effektiviserar och standardiserar utveckling, träning, utvärdering och driftsättning av maskini...
Medelfel (MAE) är ett grundläggande mått inom maskininlärning för att utvärdera regressionsmodeller. Det mäter den genomsnittliga storleken på felen i förutsäge...
Upptäck hur 'Menade du' (DYM) inom NLP identifierar och korrigerar fel i användarinmatningar, såsom stavfel eller felskrivningar, och föreslår alternativ för at...
MLflow är en öppen plattform utformad för att effektivisera och hantera hela maskininlärningslivscykeln. Den erbjuder verktyg för experimentuppföljning, kodpake...
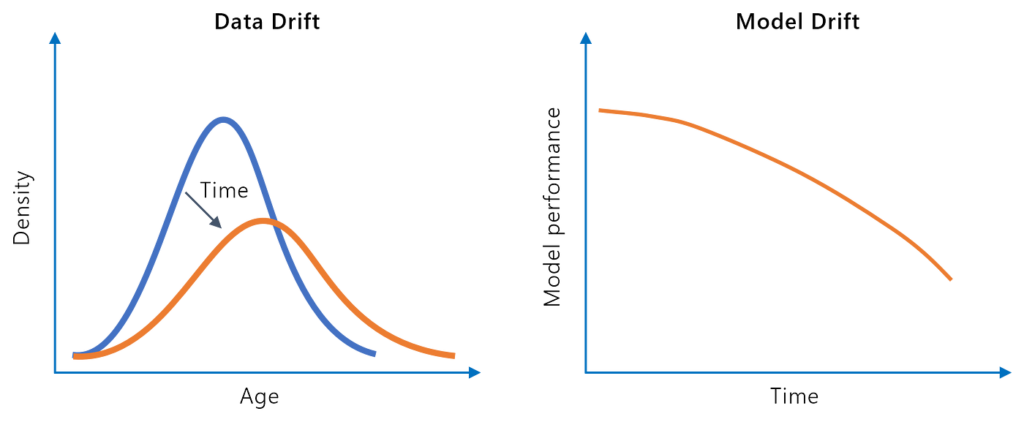
Modellförändring, eller modelldegeneration, syftar på den nedgång i en maskininlärningsmodells prediktiva prestanda över tid på grund av förändringar i den verk...
Modellkedjning är en maskininlärningsteknik där flera modeller länkas sekventiellt, där varje modells utdata fungerar som nästa modells indata. Denna metod ökar...
Modellkollaps är ett fenomen inom artificiell intelligens där en tränad modell försämras över tid, särskilt när den förlitar sig på syntetisk eller AI-genererad...
Modellrobusthet avser förmågan hos en maskininlärningsmodell (ML) att bibehålla konsekvent och noggrann prestanda trots variationer och osäkerheter i indata. Ro...
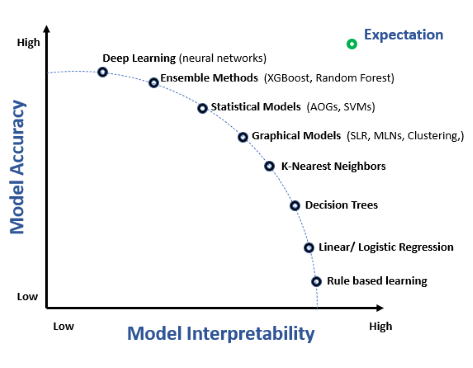
Modelltolkning avser förmågan att förstå, förklara och lita på de förutsägelser och beslut som fattas av maskininlärningsmodeller. Det är avgörande inom AI, sär...
Apache MXNet är ett open source-ramverk för djupinlärning utformat för effektiv och flexibel träning och distribution av djupa neurala nätverk. Känt för sin ska...
Human-in-the-Loop (HITL) är en AI- och maskininlärningsmetod som integrerar mänsklig expertis i träning, justering och tillämpning av AI-system, vilket ökar nog...
Mönsterigenkänning är en beräkningsprocess för att identifiera mönster och regelbundenheter i data, avgörande inom områden som AI, datavetenskap, psykologi och ...
Naiv Bayes är en familj av klassificeringsalgoritmer baserade på Bayes sats, som tillämpar villkorlig sannolikhet med den förenklande antagandet att funktionern...
Namngiven enhetsigenkänning (NER) är ett centralt delområde inom Natural Language Processing (NLP) i AI, med fokus på att identifiera och klassificera enheter i...
Naturlig språkbearbetning (NLP) är ett delområde inom artificiell intelligens (AI) som gör det möjligt för datorer att förstå, tolka och generera mänskligt språ...
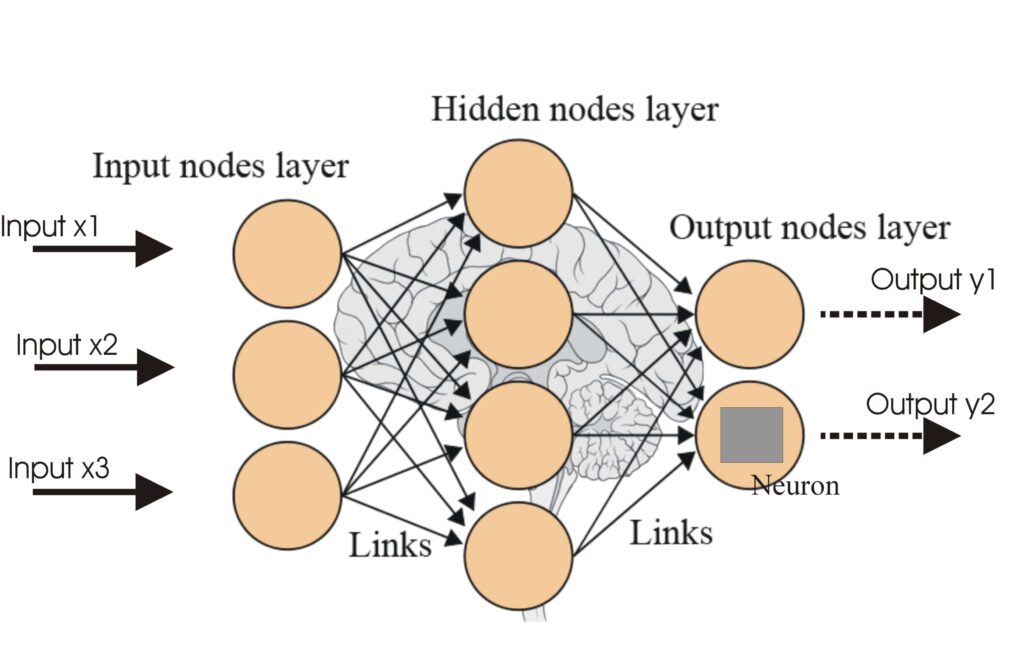
Ett neuralt nätverk, eller artificiellt neuralt nätverk (ANN), är en beräkningsmodell inspirerad av den mänskliga hjärnan, avgörande inom AI och maskininlärning...
Natural Language Toolkit (NLTK) är en omfattande svit av Python-bibliotek och program för symbolisk och statistisk språkteknologi (NLP). Verktyget används fliti...
No-Code AI-plattformar gör det möjligt för användare att bygga, implementera och hantera AI- och maskininlärningsmodeller utan att skriva kod. Dessa plattformar...
Upptäck vikten av AI-modellernas noggrannhet och stabilitet inom maskininlärning. Lär dig hur dessa mätvärden påverkar applikationer som bedrägeridetektion, med...
NumPy är ett open source-bibliotek för Python som är avgörande för numeriska beräkningar och erbjuder effektiva arrayoperationer och matematiska funktioner. Det...
Utforska hur NVIDIAs Blackwell-system markerar en ny era för accelererad datoranvändning och revolutionerar branscher med avancerad GPU-teknik, AI och maskininl...
Open Neural Network Exchange (ONNX) är ett öppen källkodsformat för smidig utbyte av maskininlärningsmodeller mellan olika ramverk, vilket ökar flexibiliteten v...
OpenAI är en ledande forskningsorganisation inom artificiell intelligens, känd för att ha utvecklat GPT, DALL-E och ChatGPT, och strävar efter att skapa säker o...
OpenCV är ett avancerat open source-bibliotek för datorseende och maskininlärning, med över 2500 algoritmer för bildbehandling, objektigenkänning och realtidsap...
Optisk teckenigenkänning (OCR) är en omvälvande teknik som omvandlar dokument såsom inskannade papper, PDF-filer eller bilder till redigerbar och sökbar data. L...
Ord-inbäddningar är sofistikerade representationer av ord i ett kontinuerligt vektorrum som fångar semantiska och syntaktiska relationer för avancerade NLP-uppg...
Ta reda på vad ostrukturerad data är och hur den jämförs med strukturerad data. Lär dig om utmaningar och verktyg som används för ostrukturerad data.
Oövervakad inlärning är en gren av maskininlärning som fokuserar på att hitta mönster, strukturer och samband i oetiketterad data, vilket möjliggör uppgifter so...
Oövervakad inlärning är en maskininlärningsteknik som tränar algoritmer på oetiketterad data för att upptäcka dolda mönster, strukturer och samband. Vanliga met...
Pandas är ett öppen källkod-bibliotek för datamanipulering och analys i Python, känt för sin mångsidighet, robusta datastrukturer och användarvänlighet vid hant...
Parameter-Effektiv Finjustering (PEFT) är ett innovativt tillvägagångssätt inom AI och NLP som möjliggör anpassning av stora förtränade modeller till specifika ...
Utforska partiskhet inom AI: förstå dess källor, påverkan på maskininlärning, verkliga exempel och strategier för att minska partiskhet för att bygga rättvisa o...
Pathways Language Model (PaLM) är Googles avancerade familj av stora språkmodeller, utformade för mångsidiga tillämpningar som textgenerering, resonemang, kodan...
Perplexity AI är en avancerad AI-driven sökmotor och konversationstjänst som använder NLP och maskininlärning för att leverera precisa, kontextuella svar med kä...
Personlig marknadsföring med AI utnyttjar artificiell intelligens för att anpassa marknadsföringsstrategier och kommunikation till individuella kunder baserat p...
Posestimering är en datorseendeteknik som förutspår position och orientering av en person eller ett objekt i bilder eller videor genom att identifiera och spåra...
Lär dig mer om prediktiv analysteknologi inom AI, hur processen fungerar och hur den gynnar olika branscher.
Prediktiv modellering är en avancerad process inom data science och statistik som förutspår framtida utfall genom att analysera historiska datamönster. Den anvä...
PyTorch är ett öppen källkod maskininlärningsramverk utvecklat av Meta AI, känt för sin flexibilitet, dynamiska beräkningsgrafer, GPU-acceleration och sömlös in...
Q-inlärning är ett grundläggande koncept inom artificiell intelligens (AI) och maskininlärning, särskilt inom förstärkningsinlärning. Det möjliggör för agenter ...
Random Forest-regression är en kraftfull maskininlärningsalgoritm som används för prediktiv analys. Den konstruerar flera beslutsxadträd och medelvärdesxadberäk...
Utforska recall inom maskininlärning: en avgörande metrisk för att utvärdera modellprestanda, särskilt i klassificeringsuppgifter där det är viktigt att korrekt...
Regularisering inom artificiell intelligens (AI) avser en uppsättning tekniker som används för att förhindra överanpassning i maskininlärningsmodeller genom att...
Resonemang är den kognitiva processen att dra slutsatser, göra inferenser eller lösa problem baserat på information, fakta och logik. Utforska dess betydelse in...
Upptäck de viktigaste skillnaderna mellan Retrieval-Augmented Generation (RAG) och Cache-Augmented Generation (CAG) inom AI. Lär dig hur RAG dynamiskt hämtar re...
En Receiver Operating Characteristic (ROC) kurva är en grafisk representation som används för att utvärdera prestandan hos ett binärt klassificeringssystem när ...
Scikit-learn är ett kraftfullt, öppet källkodsramverk för maskininlärning i Python som erbjuder enkla och effektiva verktyg för prediktiv dataanalys. Brett anvä...
SciPy är ett robust open source-bibliotek för vetenskapliga och tekniska beräkningar. Det bygger på NumPy och erbjuder avancerade matematiska algoritmer, optime...
Utforska de viktigaste skillnaderna mellan scriptade och AI-chattbottar, deras praktiska användningsområden och hur de förändrar kundinteraktioner inom olika br...
Semantisk analys är en avgörande teknik inom Natural Language Processing (NLP) som tolkar och härleder betydelse från text, vilket gör det möjligt för maskiner ...
Semisupervised inlärning (SSL) är en maskininlärningsteknik som utnyttjar både märkta och omärkta data för att träna modeller, vilket gör det idealiskt när det ...
Sentimentanalys, även kallad opinionsutvinning, är en avgörande AI- och NLP-uppgift för att klassificera och tolka den känslomässiga tonen i text som positiv, n...
Garbage In, Garbage Out (GIGO) belyser hur kvaliteten på utdata från AI och andra system är direkt beroende av ingångsdatans kvalitet. Lär dig om dess implikati...
spaCy är ett robust, öppet Python-bibliotek för avancerad Natural Language Processing (NLP), känt för sin snabbhet, effektivitet och produktionsklara funktioner...
Stable Diffusion är en avancerad text-till-bild-genereringsmodell som använder djupinlärning för att skapa högkvalitativa, fotorealistiska bilder utifrån textbe...
Ett kunskapsstoppdatum är den specifika tidpunkt efter vilken en AI-modell inte längre har uppdaterad information. Lär dig varför dessa datum är viktiga, hur de...
Syntetisk data avser artificiellt genererad information som efterliknar verklig data. Den skapas med hjälp av algoritmer och datorsimuleringar för att fungera s...
Talsyntes, även känd som automatisk taligenkänning (ASR) eller tal-till-text, gör det möjligt för datorer att tolka och omvandla talat språk till skriven text, ...
TensorFlow är ett open-source-bibliotek utvecklat av Google Brain-teamet, utformat för numerisk beräkning och storskalig maskininlärning. Det stöder djupinlärni...
Textklassificering, även känt som textkategorisering eller texttaggning, är en central NLP-uppgift som tilldelar fördefinierade kategorier till textdokument. De...
Top-k noggrannhet är ett utvärderingsmått inom maskininlärning som bedömer om den sanna klassen finns bland de k högst predicerade klasserna, vilket ger ett mer...
Torch är ett öppen källkod maskininlärningsbibliotek och vetenskapligt beräkningsramverk baserat på Lua, optimerat för djupinlärning och AI-uppgifter. Det erbju...
Transfer Learning är en kraftfull AI/ML-teknik som anpassar förtränade modeller till nya uppgifter, förbättrar prestanda med begränsad data och ökar effektivite...
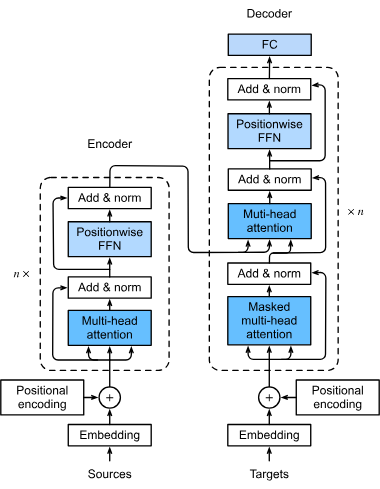
Transformatorer är en banbrytande neurala nätverksarkitektur som har förändrat artificiell intelligens, särskilt inom naturlig språkbehandling. Introducerad i 2...
Träningsdata avser den datamängd som används för att instruera AI-algoritmer, vilket gör det möjligt för dem att känna igen mönster, fatta beslut och förutsäga ...
Träningsfel inom AI och maskininlärning är skillnaden mellan en modells förutsagda och faktiska utdata under träningen. Det är en nyckelmetrik för att utvärdera...
Visar 101 till 200 av 211 resultat