Text Classification
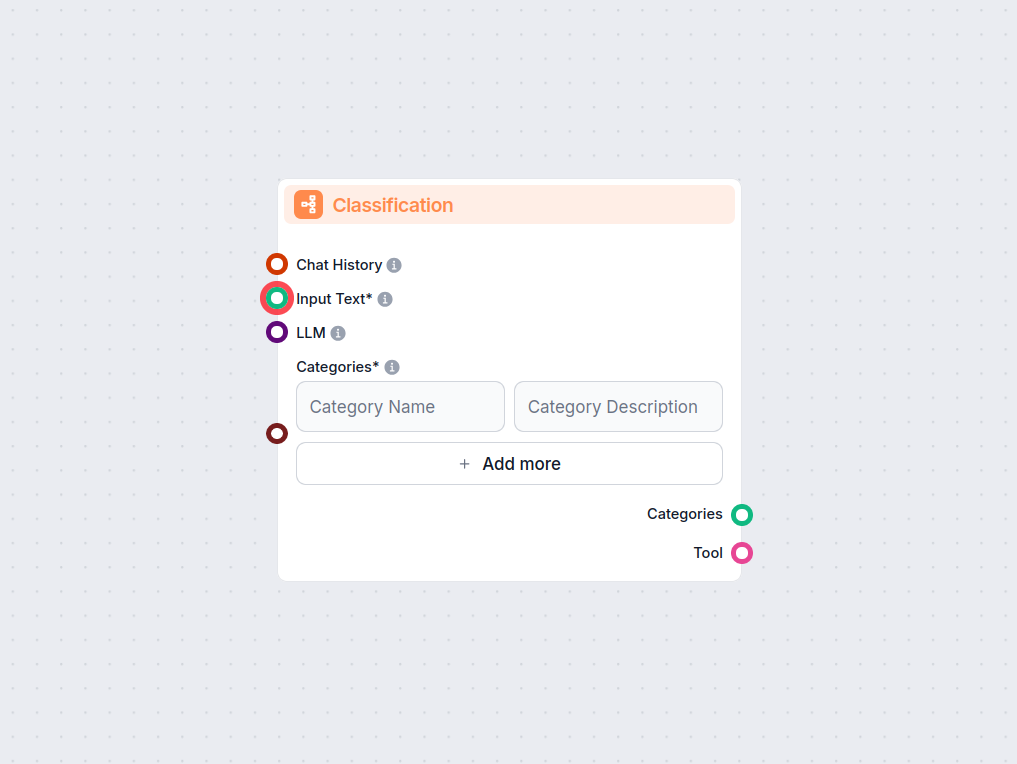
Unlock automated text categorization in your workflows with the Text Classification component for FlowHunt. Effortlessly classify input text into user-defined c...
3 min read
AI
Classification
+3
Unlock automated text categorization in your workflows with the Text Classification component for FlowHunt. Effortlessly classify input text into user-defined c...
The Area Under the Curve (AUC) is a fundamental metric in machine learning used to evaluate the performance of binary classification models. It quantifies the o...
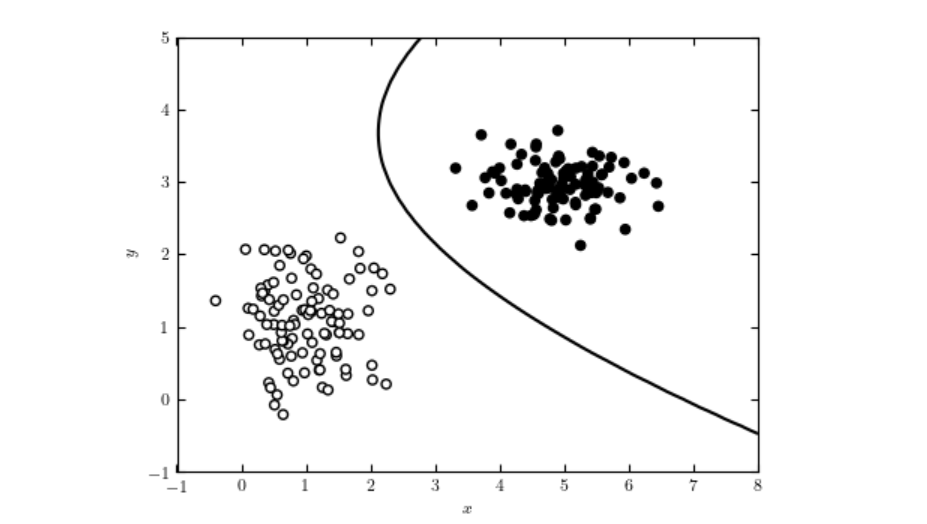
An AI classifier is a machine learning algorithm that assigns class labels to input data, categorizing information into predefined classes based on learned patt...
A confusion matrix is a machine learning tool for evaluating the performance of classification models, detailing true/false positives and negatives to provide i...
Cross-entropy is a pivotal concept in both information theory and machine learning, serving as a metric to measure the divergence between two probability distri...
A decision tree is a powerful and intuitive tool for decision-making and predictive analysis, used in both classification and regression tasks. Its tree-like st...
Learn about Discriminative AI Models—machine learning models focused on classification and regression by modeling decision boundaries between classes. Understan...
Gradient Boosting is a powerful machine learning ensemble technique for regression and classification. It builds models sequentially, typically with decision tr...
The k-nearest neighbors (KNN) algorithm is a non-parametric, supervised learning algorithm used for classification and regression tasks in machine learning. It ...
LightGBM, or Light Gradient Boosting Machine, is an advanced gradient boosting framework developed by Microsoft. Designed for high-performance machine learning ...
Log loss, or logarithmic/cross-entropy loss, is a key metric to evaluate machine learning model performance—especially for binary classification—by measuring th...
Naive Bayes is a family of classification algorithms based on Bayes’ Theorem, applying conditional probability with the simplifying assumption that features are...
Explore recall in machine learning: a crucial metric for evaluating model performance, especially in classification tasks where correctly identifying positive i...
Supervised learning is a fundamental approach in machine learning and artificial intelligence where algorithms learn from labeled datasets to make predictions o...
Supervised learning is a fundamental AI and machine learning concept where algorithms are trained on labeled data to make accurate predictions or classification...
Top-k accuracy is a machine learning evaluation metric that assesses if the true class is among the top k predicted classes, offering a comprehensive and forgiv...