Neo4j MCP Server Integration
The Neo4j MCP Server bridges AI assistants with the Neo4j graph database, enabling secure, natural language-driven graph operations, Cypher queries, and automat...
4 min read
AI
Graph Database
+5
The Neo4j MCP Server bridges AI assistants with the Neo4j graph database, enabling secure, natural language-driven graph operations, Cypher queries, and automat...
The NASA MCP Server provides a unified interface for AI models and developers to access over 20 NASA data sources. It standardizes retrieval, processing, and ma...
The Data Exploration MCP Server connects AI assistants with external datasets for interactive analysis. It empowers users to explore CSV and Kaggle datasets, ge...
The MCP Code Executor MCP Server enables FlowHunt and other LLM-driven tools to securely execute Python code in isolated environments, manage dependencies, and ...
Reexpress MCP Server brings statistical verification to LLM workflows. Using the Similarity-Distance-Magnitude (SDM) estimator, it delivers robust confidence es...
The Databricks Genie MCP Server enables large language models to interact with Databricks environments through the Genie API, supporting conversational data exp...
JupyterMCP enables seamless integration of Jupyter Notebook (6.x) with AI assistants through the Model Context Protocol. Automate code execution, manage cells, ...
Adjusted R-squared is a statistical measure used to evaluate the goodness of fit of a regression model, accounting for the number of predictors to avoid overfit...
An AI Data Analyst synergizes traditional data analysis skills with artificial intelligence (AI) and machine learning (ML) to extract insights, predict trends, ...
Anaconda is a comprehensive, open-source distribution of Python and R, designed to simplify package management and deployment for scientific computing, data sci...
The Area Under the Curve (AUC) is a fundamental metric in machine learning used to evaluate the performance of binary classification models. It quantifies the o...
Explore bias in AI: understand its sources, impact on machine learning, real-world examples, and strategies for mitigation to build fair and reliable AI systems...
BigML is a machine learning platform designed to simplify the creation and deployment of predictive models. Founded in 2011, its mission is to make machine lear...
Causal inference is a methodological approach used to determine the cause-and-effect relationships between variables, crucial in sciences for understanding caus...
An AI classifier is a machine learning algorithm that assigns class labels to input data, categorizing information into predefined classes based on learned patt...
Data cleaning is the crucial process of detecting and fixing errors or inconsistencies in data to enhance its quality, ensuring accuracy, consistency, and relia...
Data mining is a sophisticated process of analyzing vast sets of raw data to uncover patterns, relationships, and insights that can inform business strategies a...
A decision tree is a powerful and intuitive tool for decision-making and predictive analysis, used in both classification and regression tasks. Its tree-like st...
Dimensionality reduction is a pivotal technique in data processing and machine learning, reducing the number of input variables in a dataset while preserving es...
Explore how Feature Engineering and Extraction enhance AI model performance by transforming raw data into valuable insights. Discover key techniques like featur...
Google Colaboratory (Google Colab) is a cloud-based Jupyter notebook platform by Google, enabling users to write and execute Python code in the browser with fre...
Gradient Boosting is a powerful machine learning ensemble technique for regression and classification. It builds models sequentially, typically with decision tr...
Jupyter Notebook is an open-source web application enabling users to create and share documents with live code, equations, visualizations, and narrative text. W...
K-Means Clustering is a popular unsupervised machine learning algorithm for partitioning datasets into a predefined number of distinct, non-overlapping clusters...
The k-nearest neighbors (KNN) algorithm is a non-parametric, supervised learning algorithm used for classification and regression tasks in machine learning. It ...
Kaggle is an online community and platform for data scientists and machine learning engineers to collaborate, learn, compete, and share insights. Acquired by Go...
Linear regression is a cornerstone analytical technique in statistics and machine learning, modeling the relationship between dependent and independent variable...
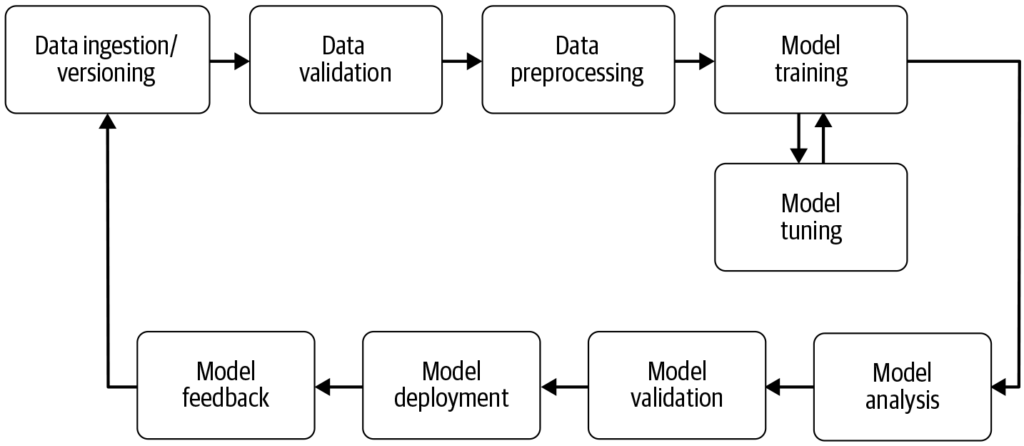
A machine learning pipeline is an automated workflow that streamlines and standardizes the development, training, evaluation, and deployment of machine learning...
Model Chaining is a machine learning technique where multiple models are linked sequentially, with each model’s output serving as the next model’s input. This a...
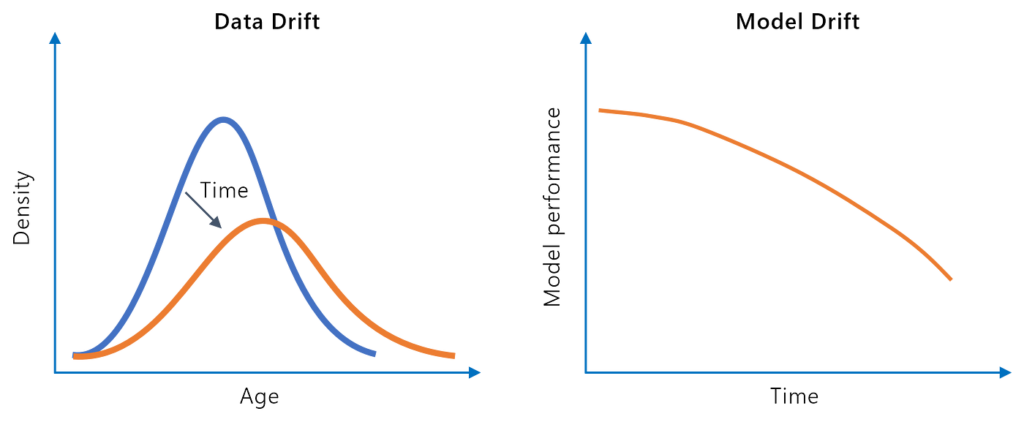
Model drift, or model decay, refers to the decline in a machine learning model’s predictive performance over time due to changes in the real-world environment. ...
NumPy is an open-source Python library crucial for numerical computing, providing efficient array operations and mathematical functions. It underpins scientific...
Pandas is an open-source data manipulation and analysis library for Python, renowned for its versatility, robust data structures, and ease of use in handling co...
Predictive modeling is a sophisticated process in data science and statistics that forecasts future outcomes by analyzing historical data patterns. It uses stat...
Scikit-learn is a powerful open-source machine learning library for Python, providing simple and efficient tools for predictive data analysis. Widely used by da...
Semi-supervised learning (SSL) is a machine learning technique that leverages both labeled and unlabeled data to train models, making it ideal when labeling all...