Activation Functions
Activation functions are fundamental to artificial neural networks, introducing non-linearity and enabling learning of complex patterns. This article explores t...
3 min read
Activation Functions
Neural Networks
+3
Activation functions are fundamental to artificial neural networks, introducing non-linearity and enabling learning of complex patterns. This article explores t...
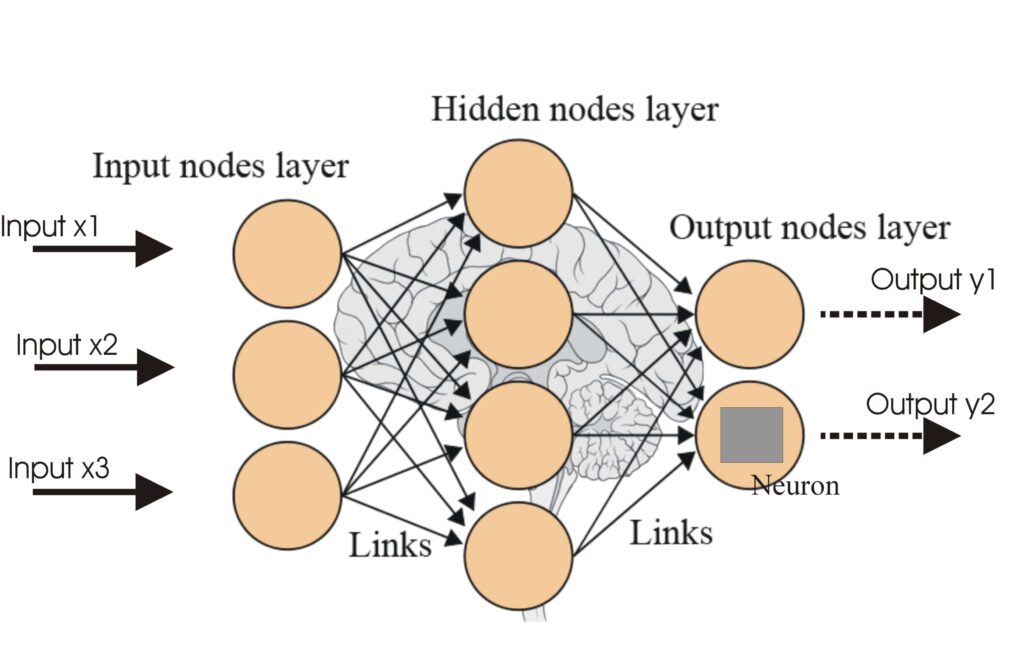
Artificial Neural Networks (ANNs) are a subset of machine learning algorithms modeled after the human brain. These computational models consist of interconnecte...
Associative memory in artificial intelligence (AI) enables systems to recall information based on patterns and associations, mimicking human memory. This memory...
Backpropagation is an algorithm for training artificial neural networks by adjusting weights to minimize prediction error. Learn how it works, its steps, and it...
Batch normalization is a transformative technique in deep learning that significantly enhances the training process of neural networks by addressing internal co...
Bidirectional Long Short-Term Memory (BiLSTM) is an advanced type of Recurrent Neural Network (RNN) architecture that processes sequential data in both forward ...
Chainer is an open-source deep learning framework offering a flexible, intuitive, and high-performance platform for neural networks, featuring dynamic define-by...
A Deep Belief Network (DBN) is a sophisticated generative model utilizing deep architectures and Restricted Boltzmann Machines (RBMs) to learn hierarchical data...
Deep Learning is a subset of machine learning in artificial intelligence (AI) that mimics the workings of the human brain in processing data and creating patter...
Dropout is a regularization technique in AI, especially neural networks, that combats overfitting by randomly disabling neurons during training, promoting robus...
A Generative Adversarial Network (GAN) is a machine learning framework with two neural networks—a generator and a discriminator—that compete to generate data in...
Gradient Descent is a fundamental optimization algorithm widely employed in machine learning and deep learning to minimize cost or loss functions by iteratively...
Discover FlowHunt's AI-powered Image Caption Generator. Instantly create engaging, relevant captions for your images with customizable themes and tones—perfect ...
Explore the advanced capabilities of the Claude 3 AI Agent. This in-depth analysis reveals how Claude 3 goes beyond text generation, showcasing its reasoning, p...
Keras is a powerful and user-friendly open-source high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano...
Long Short-Term Memory (LSTM) is a specialized type of Recurrent Neural Network (RNN) architecture designed to learn long-term dependencies in sequential data. ...
Apache MXNet is an open-source deep learning framework designed for efficient and flexible training and deployment of deep neural networks. Known for its scalab...
A neural network, or artificial neural network (ANN), is a computational model inspired by the human brain, essential in AI and machine learning for tasks like ...
Explore how NVIDIA's Blackwell system ushers in a new era of accelerated computing, revolutionizing industries through advanced GPU technology, AI, and machine ...
Pattern recognition is a computational process for identifying patterns and regularities in data, crucial in fields like AI, computer science, psychology, and d...
Recurrent Neural Networks (RNNs) are a sophisticated class of artificial neural networks designed to process sequential data by utilizing memory of previous inp...
Regularization in artificial intelligence (AI) refers to a set of techniques used to prevent overfitting in machine learning models by introducing constraints d...
Torch is an open-source machine learning library and scientific computing framework based on Lua, optimized for deep learning and AI tasks. It provides tools fo...
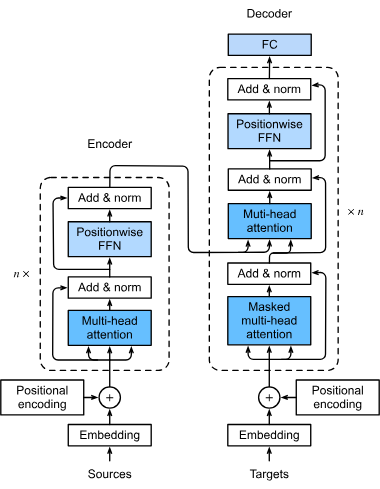
A transformer model is a type of neural network specifically designed to handle sequential data, such as text, speech, or time-series data. Unlike traditional m...
Transformers are a revolutionary neural network architecture that has transformed artificial intelligence, especially in natural language processing. Introduced...
Explore the basics of AI reasoning, including its types, importance, and real-world applications. Learn how AI mimics human thought, enhances decision-making, a...