Audio Transcription
Audio transcription is the process of converting spoken language from audio recordings into written text, making speeches, interviews, lectures, and other audio...
9 min read
Audio Transcription
AI
+4
Audio transcription is the process of converting spoken language from audio recordings into written text, making speeches, interviews, lectures, and other audio...
A Corpus (plural: corpora) in AI refers to a large, structured set of texts or audio data used for training and evaluating AI models. Corpora are essential for ...
What is a Heteronym? A heteronym is a unique linguistic phenomenon where two or more words share the same spelling but have different pronunciations and meaning...
Hidden Markov Models (HMMs) are sophisticated statistical models for systems where underlying states are unobservable. Widely used in speech recognition, bioinf...
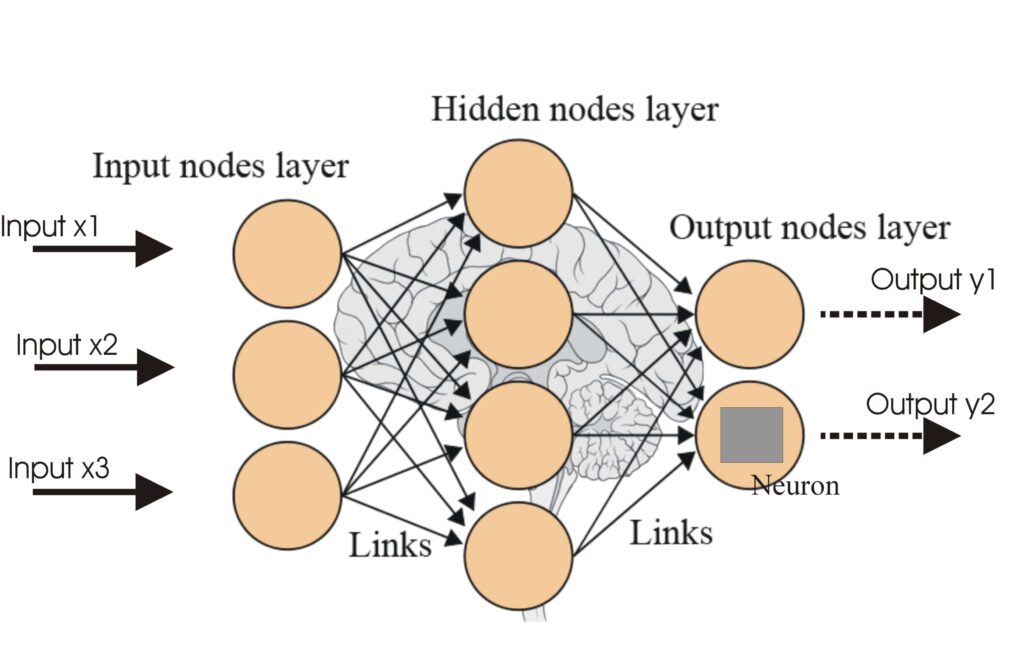
A neural network, or artificial neural network (ANN), is a computational model inspired by the human brain, essential in AI and machine learning for tasks like ...
Pattern recognition is a computational process for identifying patterns and regularities in data, crucial in fields like AI, computer science, psychology, and d...
Recurrent Neural Networks (RNNs) are a sophisticated class of artificial neural networks designed to process sequential data by utilizing memory of previous inp...
Speech recognition, also known as automatic speech recognition (ASR) or speech-to-text, enables computers to interpret and convert spoken language into written ...
Speech recognition, also known as automatic speech recognition (ASR) or speech-to-text, is a technology that enables machines and programs to interpret and tran...
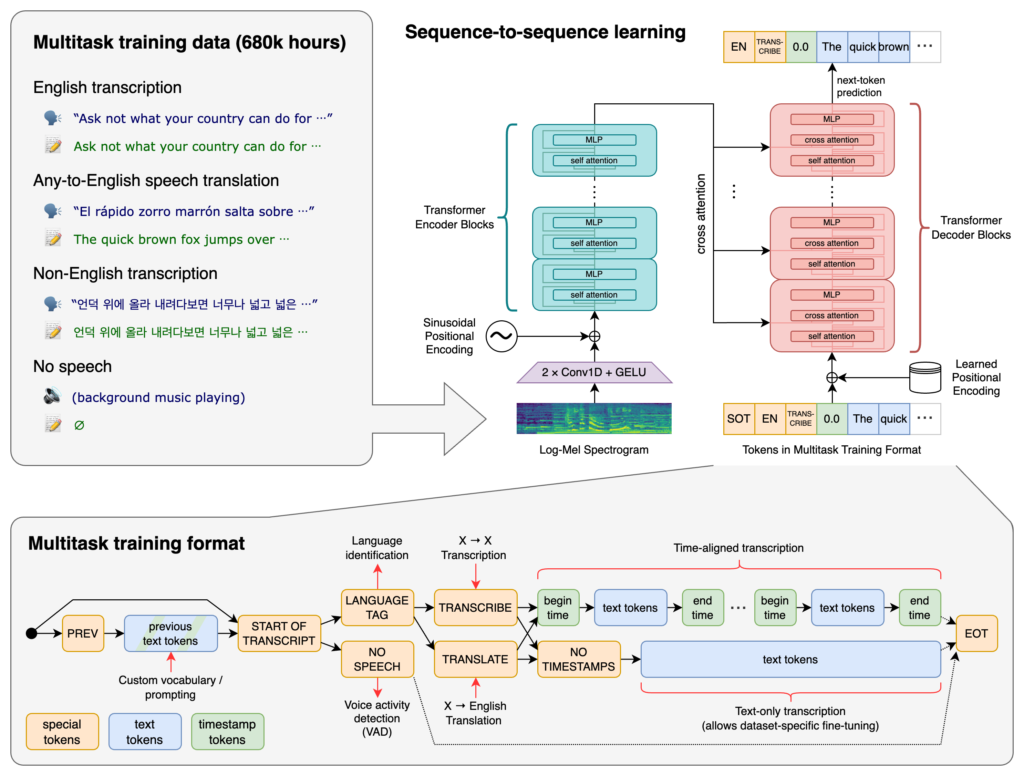
OpenAI Whisper is an advanced automatic speech recognition (ASR) system that transcribes spoken language into text, supporting 99 languages, robust to accents a...