Readability Evaluator
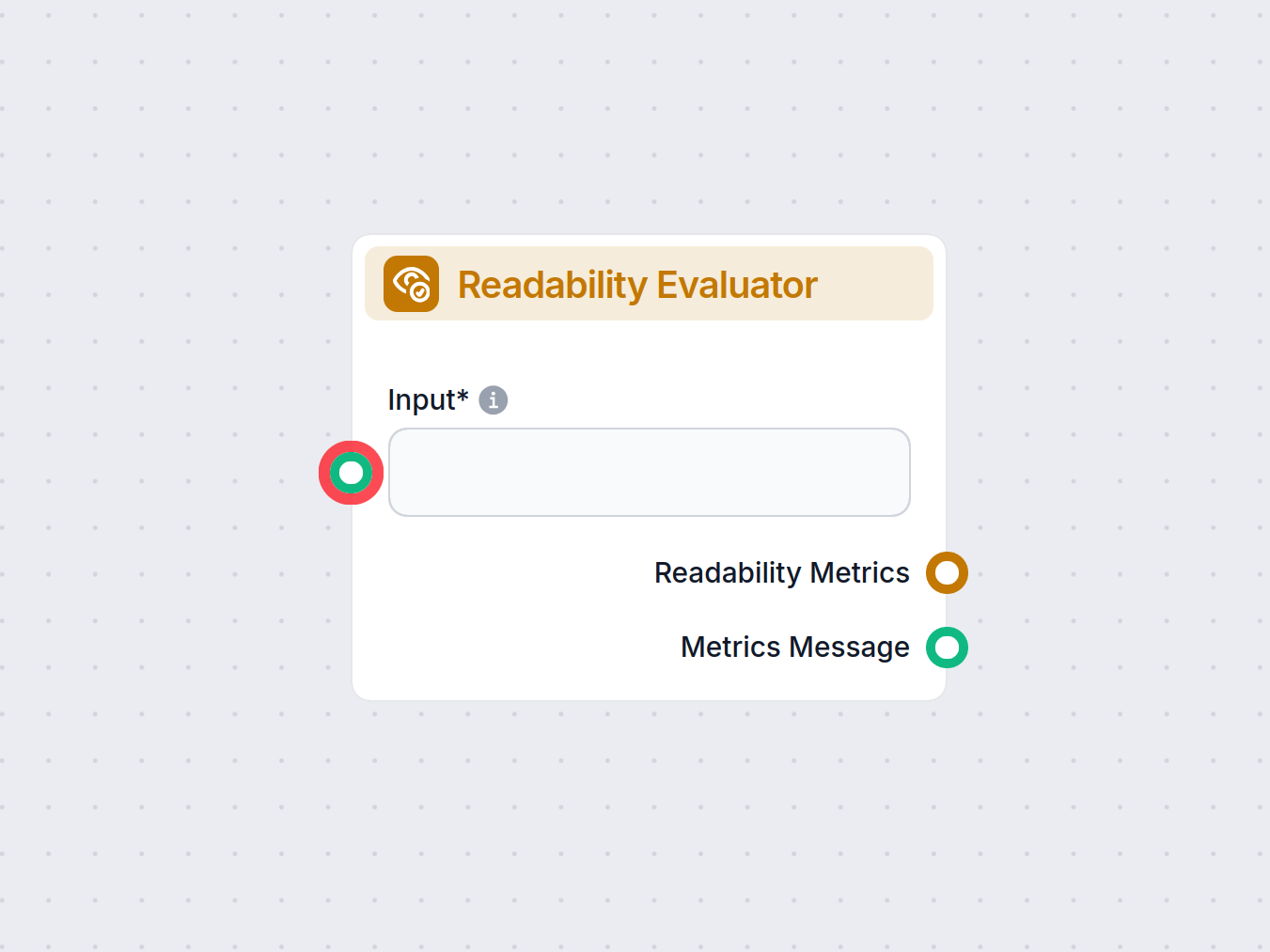
Assess the readability of any text in your workflow using the Readability Evaluator component. Instantly analyze input with established metrics like Flesch Kinc...
3 min read
AI
Automation
+4
Assess the readability of any text in your workflow using the Readability Evaluator component. Instantly analyze input with established metrics like Flesch Kinc...
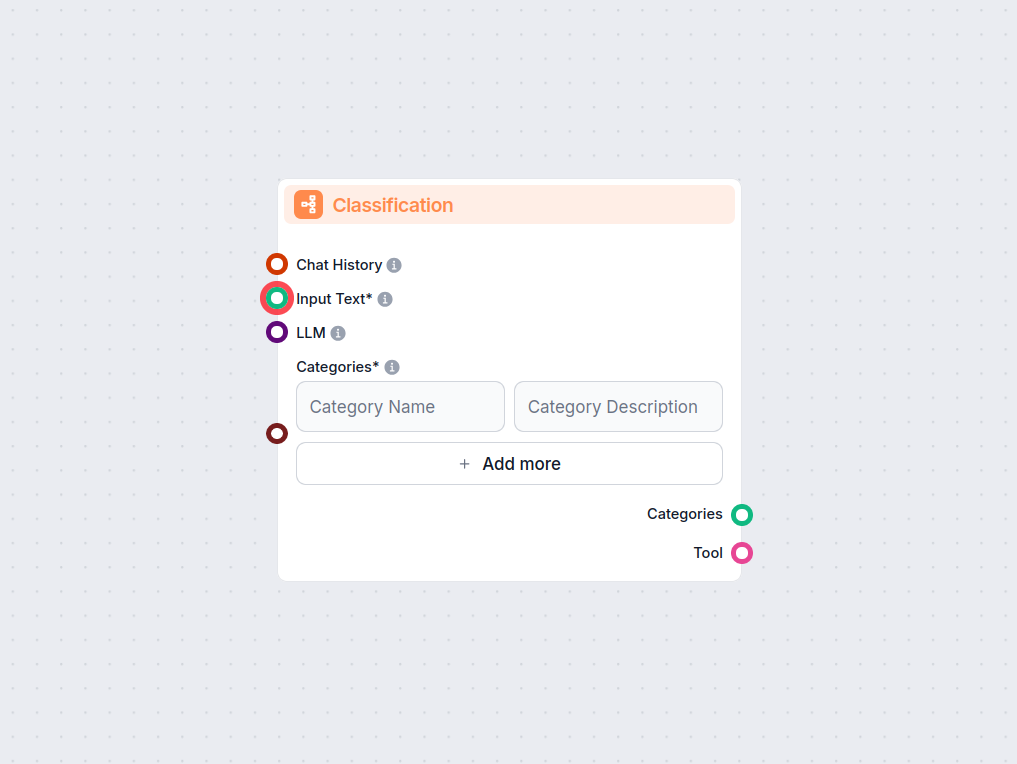
Unlock automated text categorization in your workflows with the Text Classification component for FlowHunt. Effortlessly classify input text into user-defined c...
Check all the industry-standard readability metrics. Try our free Readability Evaluator tool and learn to build your own!
Try our Dale Chall Readability Tools. Analyze plain text, check readability from a URL, or generate new, easier-to-understand text with AI-powered rewriting. Fr...
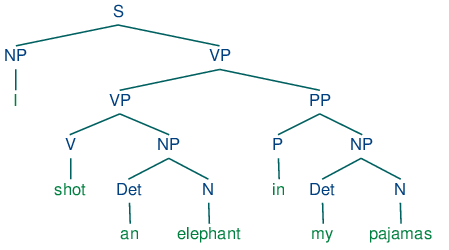
Dependency Parsing is a syntactic analysis method in NLP that identifies grammatical relationships between words, forming tree-like structures essential for app...
Named Entity Recognition (NER) is a key subfield of Natural Language Processing (NLP) in AI, focusing on identifying and classifying entities in text into prede...
Natural Language Processing (NLP) is a subfield of artificial intelligence (AI) enabling computers to understand, interpret, and generate human language. Discov...
Natural Language Toolkit (NLTK) is a comprehensive suite of Python libraries and programs for symbolic and statistical natural language processing (NLP). Widely...
Part-of-Speech Tagging (POS tagging) is a pivotal task in computational linguistics and natural language processing (NLP). It involves assigning each word in a ...
Discover the importance of Readability evaluator from text in assessing text complexity and ensuring content suitability for diverse audiences. Explore FlowHunt...
spaCy is a robust open-source Python library for advanced Natural Language Processing (NLP), known for its speed, efficiency, and production-ready features like...