Sitemap'ten LLM.txt AI Dönüştürücü
Web sitenizin sitemap.xml dosyasını otomatik olarak LLM dostu dokümantasyon formatına dönüştürün. Bu yapay zeka destekli dönüştürücü, web içeriğinizi çıkarır, i...
2 dakika okuma
AI
Documentation
+4
llms.txt, web sitesi içeriğini LLM’ler için basitleştirerek, yapılandırılmış ve makine tarafından okunabilir bir indeks sağlayarak yapay zekâ odaklı etkileşimleri geliştirir.
llms.txt dosyası, Büyük Dil Modellerinin (LLM’ler) web sitelerinden bilgiye erişimini, anlamasını ve işlemesini geliştirmek için tasarlanmış, Markdown formatında standartlaştırılmış bir metin dosyasıdır. Bir web sitesinin kök dizininde (örn. /llms.txt) barındırılan bu dosya, özellikle çıkarım sırasında makine tarafından tüketim için optimize edilmiş, yapılandırılmış ve özetlenmiş içerikler sunan düzenlenmiş bir indeks görevi görür. Temel amacı, gezinme menüleri, reklamlar ve JavaScript gibi klasik HTML içeriğinin karmaşıklığını aşarak, hem insan hem de makine tarafından kolayca okunabilen veriler sunmaktır.
robots.txt veya sitemap.xml gibi diğer web standartlarından farklı olarak, llms.txt özellikle arama motorları için değil; ChatGPT, Claude veya Google Gemini gibi çıkarım motorları için uyarlanmıştır. Bu sayede yapay zekâ sistemleri, genellikle tüm bir web sitesinin içeriğini işleyemeyecek kadar küçük olan bağlam pencereleri dahilinde yalnızca en alakalı ve değerli bilgilere ulaşabilir.
Bu kavram, Answer.AI’nin kurucu ortağı Jeremy Howard tarafından Eylül 2024’te önerildi. Karmaşık web siteleriyle etkileşimde LLM’lerin karşılaştığı verimsizliklere çözüm olarak ortaya çıktı. Klasik yöntemlerle HTML sayfalarının işlenmesi, çoğu zaman gereksiz hesaplama maliyetine ve içeriklerin yanlış yorumlanmasına yol açar. llms.txt gibi bir standart oluşturularak, web sitesi sahipleri içeriklerinin yapay zekâ sistemleri tarafından doğru ve verimli bir şekilde analiz edilmesini sağlayabilir.
llms.txt dosyası, özellikle yapay zekâ ve LLM tabanlı etkileşimler alanında çeşitli pratik amaçlara hizmet eder. Yapılandırılmış formatı sayesinde, LLM’lerin web sitesi içeriğini verimli şekilde almasına ve işlemesine olanak tanır; bu da bağlam penceresi boyutları ve işlem verimliliğiyle ilgili kısıtlamaların aşılmasını sağlar.
llms.txt dosyası, hem insanlar hem de makinelerle uyumluluğu garantilemek için belirli bir Markdown tabanlı şemayı takip eder. Yapısı şunları içerir:
Örnek:
# Örnek Web Sitesi
> Yapay zekâ hakkında bilgi ve kaynak paylaşımı için bir platform.
## Dökümantasyon
- [Hızlı Başlangıç Rehberi](https://example.com/docs/quickstart.md): Yeni başlayanlar için rehber.
- [API Referansı](https://example.com/docs/api.md): Detaylı API dökümantasyonu.
## Politikalar
- [Kullanım Şartları](https://example.com/terms.md): Platform kullanımına ilişkin yasal kurallar.
- [Gizlilik Politikası](https://example.com/privacy.md): Veri işleme ve kullanıcı gizliliği hakkında bilgi.
## Optional
- [Şirket Tarihçesi](https://example.com/history.md): Önemli kilometre taşları ve başarıların zaman çizelgesi.
Python ile sunucu-taraflı web uygulamaları geliştirmek için bir kütüphane olan FastHTML, dokümantasyonuna kolay erişim sağlamak için llms.txt kullanır. Dosyasında, hızlı başlangıç rehberleri, HTMX referansları ve örnek uygulamalara bağlantılar bulunur; böylece geliştiriciler ihtiyaç duydukları kaynaklara hızla ulaşabilir.
Örnek Parça:
# FastHTML
> Sunucu-taraflı hiper medya uygulamaları oluşturmak için bir Python kütüphanesi.
## Dökümanlar
- [Hızlı Başlangıç](https://fastht.ml/docs/quickstart.md): Temel özelliklerin genel bakışı.
- [HTMX Referansı](https://github.com/bigskysoftware/htmx/blob/master/www/content/reference.md): Tüm HTMX öznitelikleri ve metotları.
Nike gibi bir e-ticaret devi, ürün serileri, sürdürülebilirlik girişimleri ve müşteri destek politikaları hakkında yapay zekâ sistemlerine bilgi vermek için bir llms.txt dosyası kullanabilir.
Örnek Parça:
# Nike
> Sürdürülebilirlik ve inovasyona vurgu yapan, atletik ayakkabı ve giyimde küresel lider.
## Ürün Serileri
- [Koşu Ayakkabıları](https://nike.com/products/running.md): React köpük ve Vaporweave teknolojileri hakkında bilgiler.
- [Sürdürülebilirlik Girişimleri](https://nike.com/sustainability.md): 2025 hedefleri ve çevre dostu materyaller.
## Müşteri Desteği
- [İade Politikası](https://nike.com/returns.md): 60 günlük iade süresi ve istisnalar.
- [Beden Tabloları](https://nike.com/sizing.md): Ayakkabı ve giysi bedenlendirme tabloları.
Üç standart da otomatik sistemlere yardımcı olmak için tasarlanmış olsa da, amaçları ve hedef kitleleri önemli ölçüde farklılık gösterir.
llms.txt:
robots.txt:
sitemap.xml:
robots.txt ve sitemap.xml’den farklı olarak, llms.txt klasik arama motorları değil çıkarım motorları için tasarlanmıştır.llms.txt ve llms-full.txt oluşturur.llms.txt dosyası oluşturur.https://example.com/llms.txt).llms_txt2ctx gibi araçlarla dosyanızı doğrulayın.llms.txt veya llms-full.txt dosyalarını doğrudan yüklemesine izin verir (örn. Claude veya ChatGPT).llms.txt geliştiriciler ve küçük platformlar arasında yaygınlaşmış olsa da, henüz OpenAI veya Google gibi büyük sağlayıcılar tarafından resmi olarak desteklenmemektedir.llms-full.txt dosyası bazı LLM’lerin bağlam penceresi boyutunu aşabilir.Bu zorluklara rağmen, llms.txt yapay zekâ odaklı sistemler için içerik optimizasyonunda ileriye dönük bir yaklaşımı temsil eder. Bu standardı benimseyen kuruluşlar, içeriklerinin erişilebilir, doğru ve yapay zekâ öncelikli dünyada öncelikli olmasını sağlayabilir.
Araştırma: Büyük Dil Modelleri (LLM’ler)
Büyük Dil Modelleri (LLM’ler), sohbet robotları, içerik moderasyonu ve arama motorları gibi uygulamalarda doğal dil işleme için baskın bir teknoloji haline gelmiştir. Nicholas ve Bhatia’nın (2023) “Çeviri Kaybı: Büyük Dil Modelleriyle İngilizce Olmayan İçerik Analizi” başlıklı makalesinde, yazarlar LLM’lerin nasıl çalıştığına dair net bir teknik açıklama sunmakta; İngilizce ile diğer diller arasındaki veri erişim farkına dikkat çekmekte ve çok dilli modellerle bu açığın kapatılmasına yönelik çabaları tartışmaktadır. Makale, özellikle çok dilli bağlamlarda LLM’lerle içerik analizinin zorluklarını detaylandırır ve araştırmacılar, şirketler ve politika yapıcılar için bu modellerin uygulanması ve geliştirilmesine dair öneriler sunar. Yazarlar, ilerleme kaydedilmiş olsa da İngilizce dışındaki diller için önemli sınırlamaların devam ettiğini vurgular. Makaleyi oku
Müller ve Laurent’in (2022) “Cedille: Büyük, Otoregresif Fransızca Dil Modeli” başlıklı makalesi, Fransızca’ya özgü büyük ölçekli bir dil modeli olan Cedille’i tanıtmaktadır. Cedille açık kaynaklıdır ve mevcut modellere kıyasla Fransızca sıfır-atış testlerinde üstün performans gösterir, hatta bazı görevlerde GPT-3 ile rekabet eder. Çalışma ayrıca Cedille’in güvenliğini değerlendirir ve dikkatli veri kümesi filtrelemesiyle toksisiteyi azalttığını gösterir. Bu çalışma, özel dillere optimize edilmiş LLM’lerin önemini ve etkisini vurgular. Makale, LLM ekosisteminde dil-özel kaynaklara duyulan ihtiyacı ortaya koymaktadır. Makaleyi oku
Ojo ve Ogueji’nin (2023) “Ticari Büyük Dil Modelleri Afrika Dillerinde Ne Kadar İyi?” başlıklı çalışması, ticari LLM’lerin hem çeviri hem de metin sınıflandırma görevlerinde Afrika dillerindeki performansını değerlendirmektedir. Bulgular, bu modellerin genellikle Afrika dillerinde düşük performans gösterdiğini, sınıflandırmada ise çeviriye göre daha iyi sonuçlar elde edildiğini ortaya koymaktadır. Analiz, çeşitli dil aileleri ve bölgelerden sekiz Afrika dilini kapsamaktadır. Yazarlar, ticari LLM’lerde Afrika dillerinin daha fazla temsil edilmesi çağrısı yapmakta ve artan kullanım oranlarına dikkat çekmektedir. Bu çalışma, mevcut eksiklikleri ve daha kapsayıcı dil modeli geliştirilmesi gerekliliğini vurgulamaktadır. Makaleyi oku
Chang ve arkadaşlarının (2024) “Goldfish: 350 Dil İçin Tek Dilli Dil Modelleri” başlıklı makalesi, düşük kaynaklı dillerde tek dilli ve çok dilli modellerin performansını incelemektedir. Araştırma, büyük çok dilli modellerin birçok dilde çoğunlukla basit bigram modellerinden bile kötü performans gösterdiğini (FLORES perplexity ile ölçülmüştür) ortaya koymaktadır. Goldfish, 350 dil için eğitilmiş tek dilli modeller sunarak düşük kaynaklı dillerde performansı önemli ölçüde artırır. Yazarlar, daha az temsil edilen diller için daha hedefli model geliştirilmesini savunmaktadır. Bu çalışma, mevcut çok dilli LLM’lerin sınırlamaları ve tek dilli alternatiflerin potansiyeline dair değerli içgörüler sunmaktadır. Makaleyi oku
llms.txt, bir web sitesinin kök dizininde (örn. /llms.txt) barındırılan, Büyük Dil Modelleri için optimize edilmiş içeriklerin düzenlenmiş bir indeksini sunan standartlaştırılmış bir Markdown dosyasıdır ve verimli yapay zekâ odaklı etkileşimleri mümkün kılar.
robots.txt (arama motoru taraması için) veya sitemap.xml’den (indeksleme için) farklı olarak, llms.txt LLM’ler için tasarlanmıştır ve yapay zekâ çıkarımı için yüksek değerli içeriği önceliklendiren basitleştirilmiş, Markdown tabanlı bir yapı sunar.
Bir H1 başlığı (web sitesi başlığı), bir blockquote özet, bağlam için detaylı bölümler, açıklamalı bağlantılarla H2 ile ayrılmış kaynak listeleri ve isteğe bağlı olarak ikincil kaynaklar bölümü içerir.
llms.txt, Büyük Dil Modellerinin karmaşık web sitesi içeriğini işleme biçimindeki verimsizlikleri gidermek için Eylül 2024’te Answer.AI’nin kurucu ortağı Jeremy Howard tarafından önerildi.
llms.txt, gürültüyü azaltarak (örneğin reklamlar, JavaScript), içeriği bağlam pencereleri için optimize ederek ve teknik dokümantasyon veya e-ticaret gibi uygulamalar için doğru ayrıştırma sağlayarak LLM verimliliğini artırır.
Markdown formatında elle yazılabilir veya Mintlify ya da Firecrawl gibi araçlarla oluşturulabilir. llms_txt2ctx gibi doğrulama araçları, standarda uygunluğu sağlar.
İçeriğinizi yapay zekâya hazır hale getirmek ve Büyük Dil Modelleriyle etkileşimi geliştirmek için llms.txt’yi FlowHunt ile nasıl uygulayacağınızı öğrenin.
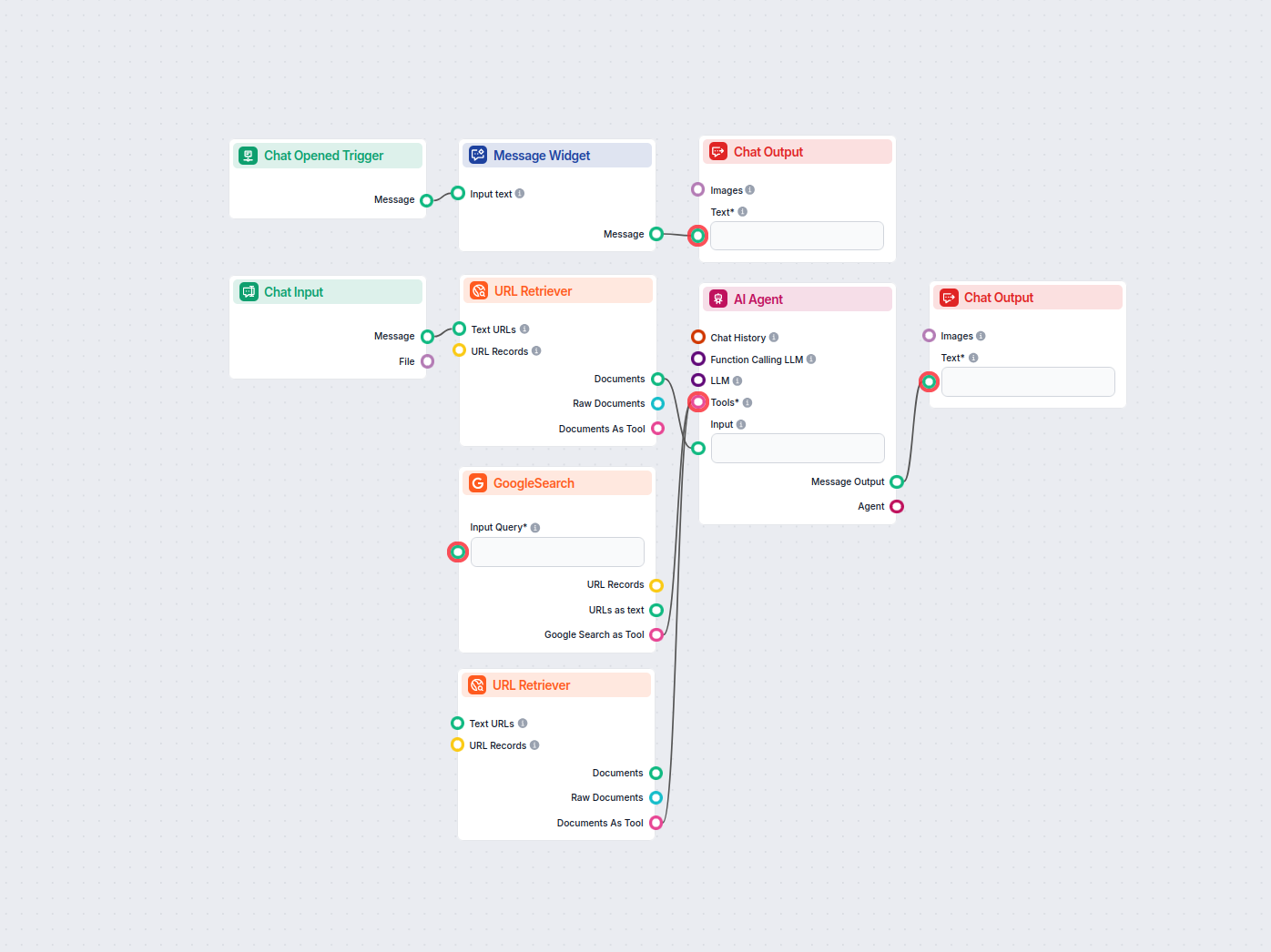
Web sitenizin sitemap.xml dosyasını otomatik olarak LLM dostu dokümantasyon formatına dönüştürün. Bu yapay zeka destekli dönüştürücü, web içeriğinizi çıkarır, i...
Herhangi bir sitemap.xml dosyasını iyi yapılandırılmış bir llms.txt formatına AI kullanarak dönüştürün. Bu iş akışı, bir sitemap'ten URL'leri alır, içeriklerini...
FlowHunt’ta bulunan 5 popüler modelin yazma yeteneklerini test ederek içerik yazarlığı için en iyi LLM’yi bulduk ve sıraladık.