
Makine Öğrenimi
Makine Öğrenimi (ML), makinelerin verilerden öğrenmesini, kalıpları tanımlamasını, tahminlerde bulunmasını ve zamanla açıkça programlanmadan karar verme süreçle...
3 dakika okuma
Machine Learning
AI
+4
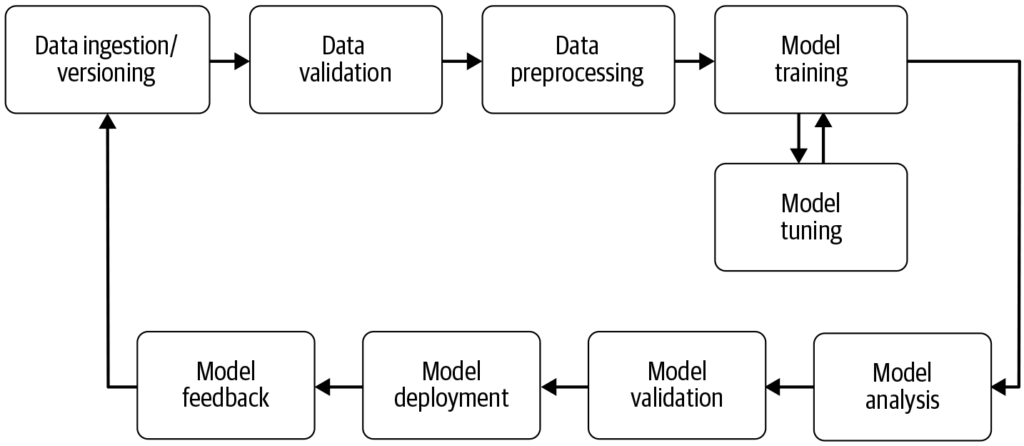
Bir makine öğrenimi hattı, veri toplamadan model dağıtımına kadar olan adımları otomatikleştirerek makine öğrenimi projelerinde verimliliği, tekrarlanabilirliği ve ölçeklenebilirliği artırır.
Bir makine öğrenimi hattı, model geliştirme, eğitim, değerlendirme ve dağıtım süreçlerini kolaylaştıran otomatik bir iş akışıdır. Verimliliği, tekrarlanabilirliği ve ölçeklenebilirliği artırır; veri toplamadan model dağıtımına ve bakımına kadar olan görevleri kolaylaştırır.
Bir makine öğrenimi hattı, makine öğrenimi modellerinin geliştirilmesi, eğitilmesi, değerlendirilmesi ve dağıtımıyla ilgili adımları kapsayan otomatik bir iş akışıdır. Ham verilerin makine öğrenimi algoritmalarıyla eyleme dönüştürülebilir içgörülere dönüştürülmesi için gereken süreçleri kolaylaştırmak ve standartlaştırmak amacıyla tasarlanmıştır. Hat yaklaşımı, verilerin, model eğitimlerinin ve dağıtımlarının verimli bir şekilde yönetilmesini ve ölçeklenmesini sağlar.
Kaynak: Building Machine Learning
Veri Toplama: Verilerin veritabanları, API’ler veya dosyalar gibi çeşitli kaynaklardan toplandığı ilk aşamadır. Veri toplama, belirli bir iş amacı için tutarlı ve eksiksiz bir veri seti oluşturmak üzere anlamlı bilgilerin edinilmesini hedefleyen yöntemsel bir uygulamadır. Bu ham veriler, makine öğrenimi modelleri için gereklidir fakat genellikle işe yarar hale gelmeleri için ön işleme gerektirir. AltexSoft’un da vurguladığı gibi, veri toplama, analitik ve karar verme süreçlerini desteklemek için bilgilerin sistematik bir şekilde biriktirilmesini içerir. Bu süreç, hattaki sonraki tüm adımların temelini oluşturduğundan kritik öneme sahiptir ve modellerin güncel ve ilgili verilerle eğitilmesini sağlamak için genellikle sürekli olarak yürütülür.
Veri Ön İşleme: Ham veriler temizlenir ve model eğitimi için uygun bir formata dönüştürülür. Sık yapılan ön işleme adımları; eksik değerlerin işlenmesi, kategorik değişkenlerin kodlanması, sayısal özelliklerin ölçeklendirilmesi ve verinin eğitim ve test kümelerine ayrılmasıdır. Bu aşama, verinin doğru formatta ve model performansını etkileyebilecek tutarsızlıklardan arındırılmış olmasını sağlar.
Özellik Mühendisliği: Modelin tahmin gücünü artırmak için yeni özellikler oluşturulur veya veriden uygun özellikler seçilir. Bu adım, alan bilgisi ve yaratıcılık gerektirebilir. Özellik mühendisliği, ham verileri, altta yatan problemi daha iyi temsil eden anlamlı özelliklere dönüştüren ve makine öğrenimi modellerinin performansını artıran yaratıcı bir süreçtir.
Model Seçimi: Problemin türüne (ör. sınıflandırma, regresyon), veri özelliklerine ve performans gereksinimlerine göre uygun makine öğrenimi algoritmaları seçilir. Bu aşamada hiperparametre ayarlamaları da yapılabilir. Doğru modelin seçilmesi, tahminlerin doğruluğu ve verimliliği açısından kritiktir.
Model Eğitimi: Seçilen model(ler), eğitim veri setiyle eğitilir. Bu süreçte model, veri içindeki örüntüleri ve ilişkileri öğrenir. Sıfırdan bir model eğitmek yerine önceden eğitilmiş modeller de kullanılabilir. Eğitim, modelin veri üzerinden öğrenerek doğru tahminler yapabilmesi için hayati bir adımdır.
Model Değerlendirme: Eğitimden sonra modelin performansı, ayrı bir test veri seti veya çapraz doğrulama ile ölçülür. Değerlendirme metrikleri probleme göre değişmekle birlikte; doğruluk, hassasiyet, geri çağırma, F1 skoru, ortalama kare hatası gibi değerler olabilir. Bu adım, modelin görülmemiş verilerde iyi performans göstereceğinden emin olmak için kritiktir.
Model Dağıtımı: Tatmin edici bir model geliştirildikten ve değerlendirildikten sonra, yeni ve görülmemiş veriler üzerinde tahmin yapmak üzere üretim ortamına dağıtılabilir. Dağıtım, API’ler oluşturmayı ve diğer sistemlerle entegrasyonu içerebilir. Bu, hattın modelin gerçek dünyada kullanılabilir hale geldiği son aşamasıdır.
İzleme ve Bakım: Dağıtımdan sonra, modelin performansının sürekli izlenmesi ve değişen veri desenlerine uyum sağlayabilmesi için gerekirse tekrar eğitilmesi çok önemlidir. Bu sürekli süreç sayesinde model gerçek dünyada güvenilir ve doğru kalır.
Doğal Dil İşleme (NLP): NLP görevleri, veri alma, metin temizleme, tokenizasyon ve duygu analizi gibi tekrarlanabilir birçok adım içerir. Hatlar bu adımları modülerleştirir; böylece diğer bileşenleri etkilemeden kolayca değişiklik ve güncelleme yapılabilir.
Kestirimci Bakım: Üretim gibi sektörlerde hatlar, sensör verilerini analiz ederek ekipman arızalarını öngörmekte kullanılabilir ve böylece proaktif bakım sağlanıp arıza süreleri azaltılabilir.
Finans: Hatlar, finansal verilerin işlenmesini otomatikleştirerek dolandırıcılık tespiti, kredi riski değerlendirmesi veya hisse senedi fiyat tahmini gibi süreçleri geliştirebilir.
Sağlık: Sağlık alanında hatlar, tıbbi görüntüleri veya hasta kayıtlarını işleyerek teşhise yardımcı olabilir ya da hasta sonuçlarını tahmin ederek tedavi stratejilerini iyileştirebilir.
Makine öğrenimi hatları, makine öğrenimi görevlerini otomatikleştirmek için yapılandırılmış bir çerçeve sunarak yapay zeka ve otomasyonun ayrılmaz bir parçası haline gelir. AI otomasyonu alanında, hatlar modellerin verimli şekilde eğitilmesini ve dağıtılmasını sağlar; böylece [sohbet botları gibi] AI sistemlerinin manuel müdahale olmadan yeni verileri öğrenip uyum sağlamasına imkan tanır. Bu otomasyon, AI uygulamalarının ölçeklenmesi ve farklı alanlarda tutarlı, güvenilir performans sunması açısından kritiktir. Hatlardan yararlanan kuruluşlar, yapay zeka yeteneklerini artırabilir ve modellerinin değişen ortamlarda etkili ve güncel kalmasını sağlayabilir.
Makine Öğrenimi Hattı Üzerine Araştırmalar
“Deep Pipeline Embeddings for AutoML” – Sebastian Pineda Arango ve Josif Grabocka (2023), Otomatik Makine Öğrenimi (AutoML) süreçlerinde makine öğrenimi hatlarının optimize edilmesindeki zorluklara odaklanır. Bu makale, hat bileşenleri arasındaki derin etkileşimleri yakalamak için yeni bir sinir ağı mimarisi sunar. Yazarlar, hatları özel bir bileşen başına kodlayıcı mekanizması ile gizli temsillere gömer. Bu gömüler, en uygun hatları aramak için Bayesci Optimizasyon çerçevesinde kullanılır. Makale, hat gömme ağının parametrelerinin meta-öğrenme ile iyileştirilmesinin altını çizer ve çoklu veri setlerinde hat optimizasyonunda son teknoloji sonuçlar gösterir. Daha fazla oku.
“AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model” – Tien-Dung Nguyen ve diğerleri (2020), Otomatik Makine Öğrenimi süreçlerinde makine öğrenimi hatlarının değerlendirilmesinin zaman alıcı olmasını ele alır. Çalışma, Bayesci ve genetik tabanlı optimizasyonlar gibi geleneksel yöntemleri verimsiz bulur. Buna karşı, yazarlar, hattın geçerliliğini çalıştırmadan değerlendiren AVATAR adında bir vekil model sunar. Bu yaklaşım, karmaşık hatların bileşimi ve optimizasyonunu büyük ölçüde hızlandırır ve geçersiz olanları erken aşamada eler. Daha fazla oku.
“Data Pricing in Machine Learning Pipelines” – Zicun Cong ve diğerleri (2021), makine öğrenimi hatlarında verinin kritik rolünü ve çoklu paydaşlar arasında işbirliğini kolaylaştırmak için veri fiyatlandırmasının gerekliliğini ele alır. Makale, makine öğrenimi bağlamında veri fiyatlandırmasındaki son gelişmeleri inceleyerek, hattın çeşitli aşamalarında bunun önemine odaklanır. Eğitim verisi toplama, işbirlikçi model eğitimi ve makine öğrenimi hizmetlerinin sunulması için fiyatlandırma stratejilerine dair içgörüler sunar ve dinamik bir ekosistemin oluşumunu vurgular. Daha fazla oku.
Bir makine öğrenimi hattı, veri toplamadan ve ön işlemeden model eğitimi, değerlendirme ve dağıtımına kadar olan adımları otomatikleştiren bir süreçtir ve makine öğrenimi modellerinin oluşturulmasını ve sürdürülmesini kolaylaştırır ve standartlaştırır.
Temel bileşenler arasında veri toplama, veri ön işleme, özellik mühendisliği, model seçimi, model eğitimi, model değerlendirme, model dağıtımı ve sürekli izleme ile bakım yer alır.
Makine öğrenimi hatları modülerlik, verimlilik, tekrarlanabilirlik, ölçeklenebilirlik, geliştirilmiş işbirliği ve modellerin üretim ortamına daha kolay dağıtılmasını sağlar.
Kullanım alanları arasında doğal dil işleme (NLP), üretimde kestirimci bakım, finansal risk değerlendirmesi ve dolandırıcılık tespiti ile sağlık teşhisleri yer alır.
Zorluklar arasında veri kalitesinin sağlanması, hattın karmaşıklığının yönetilmesi, mevcut sistemlerle entegrasyon ve hesaplama kaynakları ile altyapıya ilişkin maliyetlerin kontrol edilmesi bulunur.
FlowHunt'ın makine öğrenimi iş akışlarınızı kolayca otomatikleştirmenize ve ölçeklendirmenize nasıl yardımcı olabileceğini keşfetmek için bir demo planlayın.
Makine Öğrenimi (ML), makinelerin verilerden öğrenmesini, kalıpları tanımlamasını, tahminlerde bulunmasını ve zamanla açıkça programlanmadan karar verme süreçle...
BigML, öngörüsel modellerin oluşturulmasını ve dağıtımını basitleştirmek için tasarlanmış bir makine öğrenimi platformudur. 2011 yılında kurulan BigML’nin misyo...
MLflow, makine öğrenimi (ML) yaşam döngüsünü kolaylaştırmak ve yönetmek için tasarlanmış açık kaynaklı bir platformdur. Deney takibi, kod paketleme, model yönet...
