Kỹ Thuật Bối Cảnh: Hướng Dẫn Toàn Diện 2025 Về Làm Chủ Thiết Kế Hệ Thống AI
Khám phá sâu về kỹ thuật bối cảnh cho AI. Hướng dẫn này bao quát các nguyên lý cốt lõi, từ prompt so với context đến các chiến lược nâng cao như quản lý bộ nhớ, context rot và thiết kế đa agent.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
Bức tranh phát triển AI đã trải qua một sự chuyển mình sâu sắc. Nếu trước đây chúng ta chỉ tập trung vào việc tạo prompt hoàn hảo, thì nay thử thách lớn hơn nhiều: xây dựng toàn bộ kiến trúc thông tin bao quanh và tăng cường cho mô hình ngôn ngữ.
Sự chuyển đổi này đánh dấu bước tiến từ prompt engineering sang kỹ thuật bối cảnh—và nó chính là tương lai của phát triển AI thực tiễn. Những hệ thống tạo ra giá trị thật ngày nay không dựa vào prompt thần kỳ. Chúng thành công vì kiến trúc sư biết cách phối hợp một hệ sinh thái thông tin toàn diện.
Andrej Karpathy đã diễn tả hoàn hảo sự tiến hóa này khi ông cho rằng kỹ thuật bối cảnh là thực hành tỉ mỉ nhằm đưa đúng thông tin vào cửa sổ context, đúng thời điểm. Nhìn có vẻ đơn giản, nhưng lại hàm chứa một chân lý: LLM không còn là ngôi sao duy nhất. Nó là một thành phần then chốt trong hệ thống nơi mọi thông tin—từng mảnh ký ức, từng mô tả công cụ, từng tài liệu truy xuất—đều được sắp đặt có chủ đích để tối ưu kết quả.
Kỹ Thuật Bối Cảnh Là Gì?
Góc Nhìn Lịch Sử
Gốc rễ của kỹ thuật bối cảnh sâu xa hơn đa số nghĩ. Dù prompt engineering bùng nổ khoảng 2022-2023, nhưng các nguyên lý nền tảng của kỹ thuật bối cảnh đã xuất hiện hơn hai thập kỷ trước từ nghiên cứu về ubiquitous computing và tương tác người-máy.
Năm 2001, Anind K. Dey đã đưa ra một định nghĩa cực kỳ tiên đoán: bối cảnh bao gồm mọi thông tin giúp mô tả tình huống của một thực thể. Khuôn khổ ban đầu này đặt nền móng cho cách chúng ta nghĩ về việc máy hiểu môi trường.
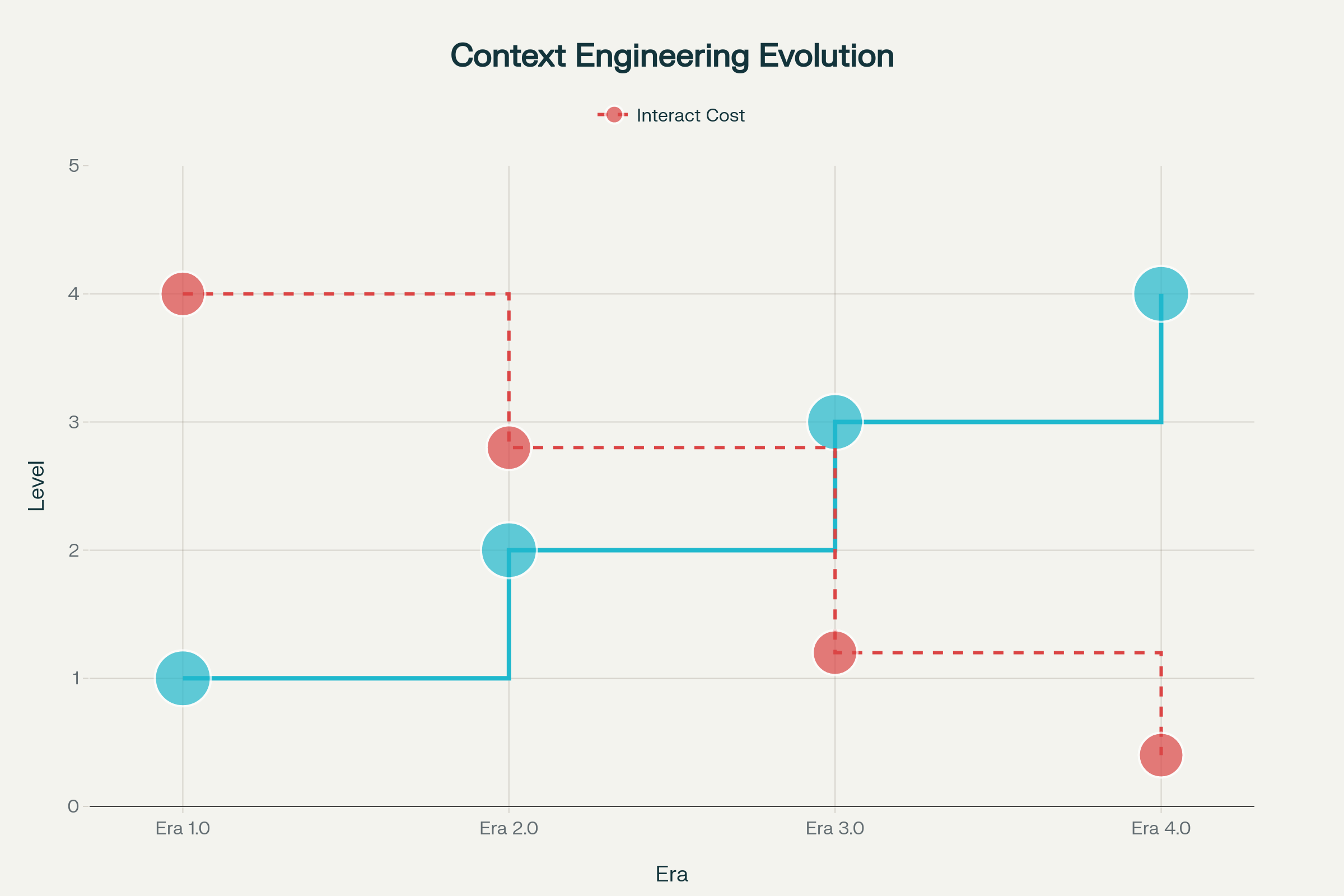
Sự phát triển của kỹ thuật bối cảnh diễn ra qua nhiều giai đoạn, mỗi giai đoạn được định hình bởi tiến bộ của trí tuệ máy:
Kỷ nguyên 1.0: Tính toán sơ khai (1990s-2020) — Trong suốt thời gian này, máy chỉ xử lý được dữ liệu có cấu trúc và tín hiệu môi trường đơn giản. Con người phải chuyển đổi hoàn toàn bối cảnh thành dạng máy xử lý được. Hãy hình dung ứng dụng desktop, mobile có cảm biến, chatbot sơ khai với kịch bản cứng nhắc.
Kỷ nguyên 2.0: Trí tuệ tập trung vào agent (2020–Hiện tại) — Sự ra đời của GPT-3 năm 2020 tạo nên bước ngoặt. Các mô hình ngôn ngữ lớn mang lại khả năng hiểu ngôn ngữ tự nhiên thật sự và xử lý ý định ngầm. Kỷ nguyên này cho phép hợp tác người-agent thực sự, khi sự mơ hồ và thiếu dữ liệu trở nên có thể kiểm soát nhờ hiểu ngôn ngữ nâng cao và học trong ngữ cảnh.
Kỷ nguyên 3.0 & 4.0: Trí tuệ người và siêu người (Tương lai) — Các làn sóng tiếp theo hướng tới hệ thống có thể cảm nhận, xử lý thông tin phức tạp với sự linh hoạt như con người, tiến tới không chỉ phản ứng mà còn chủ động xây dựng bối cảnh và phát hiện nhu cầu chưa được diễn đạt.
Sự Tiến Hóa Của Kỹ Thuật Bối Cảnh Qua Bốn Kỷ Nguyên: Từ Tính Toán Sơ Khai đến Siêu Trí Tuệ
Định Nghĩa Chính Thức
Về bản chất, kỹ thuật bối cảnh là ngành khoa học hệ thống thiết kế và tối ưu hóa dòng chảy thông tin ngữ cảnh qua các hệ thống AI—từ thu thập, lưu trữ, quản lý cho đến sử dụng cuối cùng nhằm tăng cường hiểu biết máy và thực thi nhiệm vụ.
Có thể biểu diễn toán học như một hàm chuyển đổi:
$CE: (C, T) \rightarrow f_{context}$
Trong đó:
C là thông tin ngữ cảnh thô (thực thể và đặc trưng)
T là nhiệm vụ mục tiêu hoặc miền ứng dụng
f_{context} là hàm xử lý bối cảnh kết quả
Triển khai thực tế gồm bốn thao tác nền tảng:
Thu thập tín hiệu ngữ cảnh liên quan qua nhiều cảm biến và kênh dữ liệu
Lưu trữ thông tin hiệu quả ở local, hạ tầng mạng và cloud
Quản lý phức tạp qua xử lý thông minh văn bản, đa phương tiện và các mối quan hệ
Sử dụng bối cảnh chiến lược bằng cách lọc, chia sẻ liên hệ giữa hệ thống và tùy chỉnh theo yêu cầu người dùng
Vì Sao Kỹ Thuật Bối Cảnh Quan Trọng: Khung Giảm Nhiễu Thông Tin
Kỹ thuật bối cảnh giải quyết sự bất đối xứng căn bản trong giao tiếp người-máy. Khi con người nói chuyện, chúng ta tự động lấp đầy khoảng trống nhờ kiến thức văn hóa, trí tuệ cảm xúc, và nhận thức tình huống. Máy không có các khả năng này.
Khoảng cách này thể hiện dưới dạng entropy thông tin. Giao tiếp của con người hiệu quả vì chúng ta mặc định có lượng lớn bối cảnh chung. Máy cần mọi thứ phải được diễn đạt rõ ràng. Kỹ thuật bối cảnh thực chất là xử lý trước bối cảnh cho máy—nén sự phức tạp cao (entropy lớn) của ý định, tình huống thành biểu diễn đơn giản máy có thể hiểu.
Khi trí tuệ máy tiến bộ, việc giảm entropy này sẽ ngày càng được tự động hóa. Hiện tại (Kỷ nguyên 2.0), kỹ sư phải chủ động tổ chức phần lớn quá trình này. Ở Kỷ nguyên 3.0 trở đi, máy sẽ dần đảm nhận phần lớn gánh nặng. Nhưng thử thách cốt lõi vẫn không thay đổi: nối liền khoảng cách giữa phức tạp của con người và khả năng hiểu của máy.
Prompt Engineering vs Kỹ Thuật Bối Cảnh: Những Khác Biệt Cốt Lõi
Một nhầm lẫn phổ biến là gộp hai lĩnh vực này. Thực tế, chúng là hai cách tiếp cận kiến trúc hệ thống AI hoàn toàn khác biệt.
Prompt engineering tập trung vào thiết kế từng chỉ dẫn hoặc truy vấn để điều chỉnh hành vi mô hình. Nó tối ưu cấu trúc ngôn ngữ—cách diễn đạt, ví dụ, và mô hình suy luận trong một lần tương tác.
Kỹ thuật bối cảnh là ngành hệ thống toàn diện quản lý mọi thứ mô hình tiếp nhận trong quá trình suy luận—bao gồm prompt, tài liệu truy xuất, hệ thống bộ nhớ, mô tả công cụ, thông tin trạng thái, v.v.
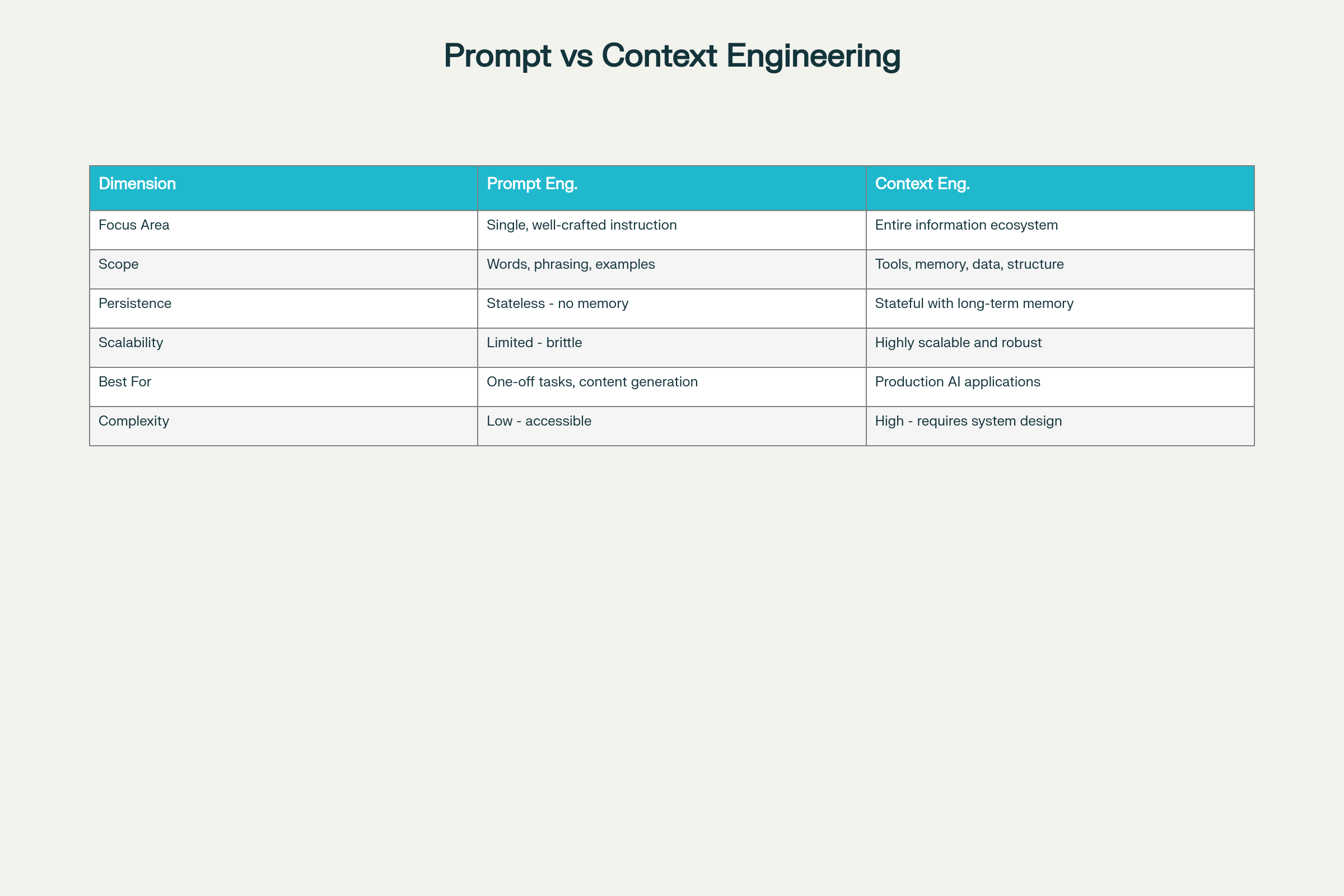
Prompt Engineering vs Kỹ Thuật Bối Cảnh: Những Khác Biệt và Cân Nhắc
Hãy phân biệt: Yêu cầu ChatGPT viết email chuyên nghiệp là prompt engineering. Xây dựng nền tảng chăm sóc khách hàng lưu lịch sử hội thoại nhiều phiên, truy cập thông tin tài khoản, ghi nhớ ticket hỗ trợ trước đó—đó là kỹ thuật bối cảnh.
Khác Biệt Cốt Lõi Qua Tám Khía Cạnh:
Khía cạnh
Prompt Engineering
Kỹ Thuật Bối Cảnh
Trọng tâm
Tối ưu hóa từng chỉ dẫn
Hệ sinh thái thông tin toàn diện
Phạm vi
Từ ngữ, diễn đạt, ví dụ
Công cụ, bộ nhớ, kiến trúc dữ liệu
Tồn tại
Không lưu trạng thái
Có trạng thái, duy trì bộ nhớ lâu dài
Khả năng mở rộng
Hạn chế, dễ vỡ khi mở rộng
Rất mở rộng và vững chắc
Phù hợp nhất cho
Tác vụ đơn lẻ, sinh nội dung
Ứng dụng AI thực tế, quy mô lớn
Độ phức tạp
Thấp, dễ tiếp cận
Cao—yêu cầu kiến thức thiết kế hệ thống
Độ tin cậy
Không ổn định khi mở rộng
Ổn định và đáng tin cậy
Bảo trì
Dễ gãy khi thay đổi yêu cầu
Dễ bảo trì, mô-đun hóa
Điểm mấu chốt: Ứng dụng LLM thực tế quy mô lớn hầu như luôn cần kỹ thuật bối cảnh, không chỉ prompt khéo léo. Như Cognition AI từng nhận định, kỹ thuật bối cảnh đã trở thành nhiệm vụ chính của kỹ sư khi xây dựng agent AI.
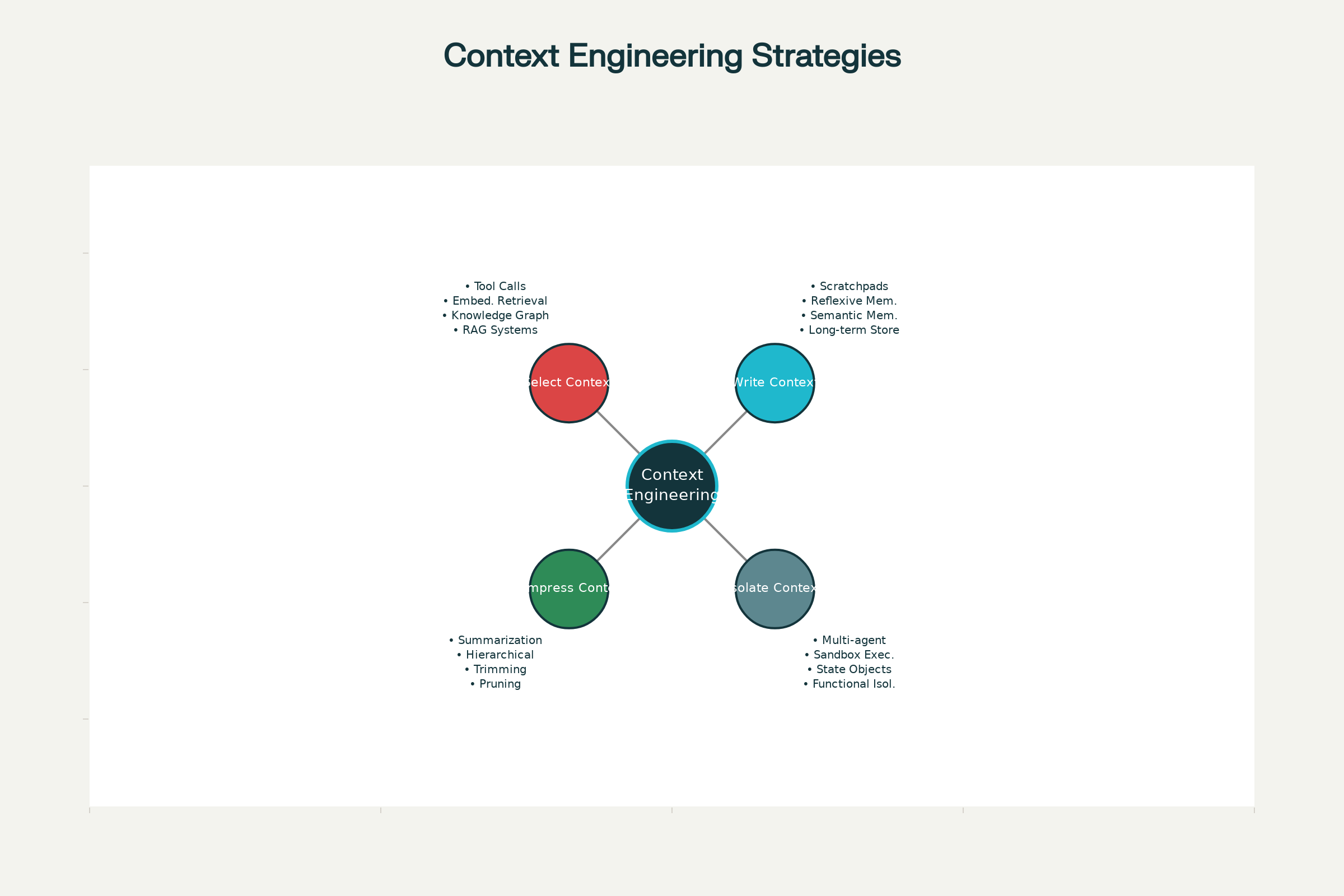
Bốn Chiến Lược Cốt Lõi Cho Kỹ Thuật Bối Cảnh
Khắp các hệ thống AI hàng đầu—Claude, ChatGPT đến agent chuyên dụng của Anthropic và các phòng lab tiên phong—bốn chiến lược cốt lõi đã định hình cho quản lý context hiệu quả. Chúng có thể áp dụng riêng lẻ hoặc phối hợp để tăng hiệu quả.
1. Ghi Bối Cảnh: Lưu Thông Tin Ngoài Cửa Sổ Context
Nguyên tắc nền tảng rất đơn giản: không bắt mô hình phải nhớ mọi thứ. Thay vào đó, lưu trữ thông tin quan trọng ngoài context window để dễ dàng truy xuất khi cần.
Scratchpad là cách trực quan nhất. Như con người ghi chú khi giải quyết vấn đề, agent AI dùng scratchpad để lưu thông tin phục vụ về sau. Có thể là công cụ agent gọi để lưu chú thích, hoặc trường trong đối tượng trạng thái runtime lưu trữ qua nhiều bước thực thi.
Nghiên cứu multi-agent của Anthropic thể hiện rất rõ: LeadResearcher khởi đầu bằng việc lên kế hoạch và lưu vào Memory để đảm bảo dù context window vượt 200.000 tokens và bị cắt, kế hoạch vẫn được giữ.
Bộ nhớ (Memories) mở rộng scratchpad qua nhiều phiên. Thay vì chỉ lưu trong một phiên (bộ nhớ theo session), hệ thống có thể xây dựng bộ nhớ lâu dài phát triển theo thời gian qua nhiều lần tương tác. Mô hình này đã thành chuẩn trong ChatGPT, Claude Code, Cursor, Windsurf.
Dự án như Reflexion tiên phong bộ nhớ phản chiếu—agent tự phản tư sau mỗi bước và sinh memory cho tương lai. Generative Agents mở rộng bằng cách tổng hợp memory định kỳ từ phản hồi quá khứ.
Ba loại bộ nhớ:
Episodic: Ví dụ cụ thể về hành vi/tương tác trước đây (giá trị cho few-shot learning)
Procedural: Quy tắc, hướng dẫn vận hành (đảm bảo thực thi nhất quán)
Semantic: Kiến thức về sự kiện, mối quan hệ (cung cấp nền tảng tri thức)
2. Lựa Chọn Bối Cảnh: Lấy Đúng Thông Tin Cần Thiết
Khi đã lưu trữ, agent phải truy xuất đúng cái cần cho tác vụ hiện tại. Lựa chọn sai còn tệ hơn không có memory—thông tin không liên quan có thể gây nhiễu hoặc sinh ảo tưởng.
Cơ chế chọn bộ nhớ:
Cách đơn giản là luôn kèm file hẹp. Claude Code dùng file CLAUDE.md cho procedural memory, Cursor và Windsurf dùng file rules. Tuy nhiên, cách này không mở rộng được khi agent có hàng trăm fact và mối quan hệ.
Với bộ nhớ lớn, retrieval dựa trên embedding và knowledge graph rất phổ biến. Hệ thống chuyển đổi memory và truy vấn thành vector, rồi truy xuất memory gần nhất về mặt ngữ nghĩa.
Dẫu vậy, như Simon Willison đã minh chứng tại AIEngineer World’s Fair, cách này có thể thất bại bất ngờ. ChatGPT từng lấy nhầm vị trí của ông từ memory vào ảnh sinh ra, cho thấy ngay cả hệ thống tinh vi cũng chọn nhầm memory. Điều này chứng tỏ sự cần thiết của kỹ thuật tỉ mỉ.
Chọn công cụ (Tool Selection) có thách thức riêng. Khi agent có hàng chục, hàng trăm công cụ, liệt kê tất cả sẽ gây nhiễu—mô tả trùng lặp làm model chọn nhầm. Giải pháp hiệu quả: áp dụng nguyên lý RAG cho mô tả công cụ. Chỉ truy xuất công cụ liên quan, độ chính xác chọn công cụ tăng gấp ba lần.
Truy xuất tri thức (Knowledge Retrieval) là bài toán phong phú nhất. Agent code là ví dụ điển hình ở quy mô lớn. Như kỹ sư của Windsurf nói, chỉ index code thôi chưa đủ để truy xuất context hiệu quả. Họ kết hợp indexing, embedding search với phân tích AST, chunking theo ranh giới ngữ nghĩa. Tuy nhiên, embedding search giảm độ tin cậy khi codebase lớn. Thành công đến từ phối hợp grep/file search, knowledge graph retrieval và rerank theo mức độ liên quan.
3. Nén Bối Cảnh: Giữ Lại Điều Quan Trọng Nhất
Khi agent xử lý tác vụ dài, context sẽ tích tụ dần. Ghi chú, kết quả công cụ, lịch sử tương tác nhanh chóng vượt quá cửa sổ context. Chiến lược nén giải quyết thách thức này bằng cách chắt lọc thông tin nhưng vẫn giữ điều cốt lõi.
Tóm tắt (Summarization) là kỹ thuật chính. Claude Code dùng “auto-compact”—khi context window chạm 95%, hệ thống sẽ tóm tắt toàn bộ quá trình tương tác. Có thể dùng nhiều cách:
Tóm tắt đệ quy: Tóm tắt nhiều lớp, tạo phân cấp nén
Tóm tắt phân cấp: Sinh tóm tắt ở nhiều mức trừu tượng
Tóm tắt mục tiêu: Nén riêng thành phần nặng token (ví dụ kết quả tìm kiếm) thay vì toàn context
Cognition AI tiết lộ họ dùng model fine-tune để tóm tắt ở biên agent-agent nhằm giảm token khi truyền tri thức—cho thấy chiều sâu kỹ thuật của bước này.
Cắt tỉa context (Trimming) là phương pháp bổ sung. Thay vì dùng LLM để tóm tắt, trimming chỉ đơn giản loại bỏ context dựa trên quy tắc cứng—bỏ tin nhắn cũ, lọc theo mức độ quan trọng, hoặc dùng bộ lọc huấn luyện như Provence cho QA.
Ý nghĩa then chốt: Loại bỏ gì quan trọng không kém giữ lại gì. Một context 300 token tập trung thường hiệu quả hơn một context 113.000 token không chọn lọc khi đối thoại.
4. Cô Lập Bối Cảnh: Chia Nhỏ Thông Tin Theo Hệ Thống
Cuối cùng, chiến lược cô lập thừa nhận mỗi tác vụ cần thông tin khác nhau. Thay vì dồn hết vào một context window, các kỹ thuật này phân bổ context cho các hệ thống chuyên biệt.
Kiến trúc đa agent là phổ biến nhất. Thư viện OpenAI Swarm thiết kế với “tách biệt chức năng”—mỗi sub-agent chuyên xử lý một tác vụ với công cụ, hướng dẫn, context riêng.
Nghiên cứu của Anthropic chứng minh sức mạnh của cách này: nhiều agent với context riêng thường vượt trội agent đơn, vì mỗi subagent có thể tối ưu cho tiểu nhiệm vụ. Subagent chạy song song với context riêng, cùng lúc khám phá nhiều khía cạnh vấn đề.
Tuy nhiên, hệ thống đa agent có mặt trái. Anthropic ghi nhận token sử dụng cao hơn tới 15 lần so với chat agent đơn. Điều này đòi hỏi phải điều phối chặt chẽ, prompt engineering cho lên kế hoạch và cơ chế phối hợp tinh vi.
Sandbox là một cách cô lập khác. CodeAgent của HuggingFace cho thấy: thay vì trả về JSON để model xử lý, agent xuất code chạy trong sandbox. Chỉ kết quả (return value) được trả về LLM, giữ các object nặng token trong môi trường thực thi. Cách này rất tốt cho dữ liệu hình, âm thanh.
Cô lập trạng thái (State Object Isolation) có thể là kỹ thuật bị đánh giá thấp nhất. Trạng thái runtime của agent có thể thiết kế theo schema cấu trúc (Pydantic model) với nhiều trường. Một trường (ví dụ messages) sẽ truyền vào LLM mỗi bước, các trường khác giữ riêng để dùng chọn lọc. Kiểm soát chi tiết mà không tăng phức tạp kiến trúc.
Bốn Chiến Lược Cốt Lõi Cho Kỹ Thuật Bối Cảnh Hiệu Quả Trong AI Agent
Vấn Đề Context Rot: Thách Thức Trọng Yếu
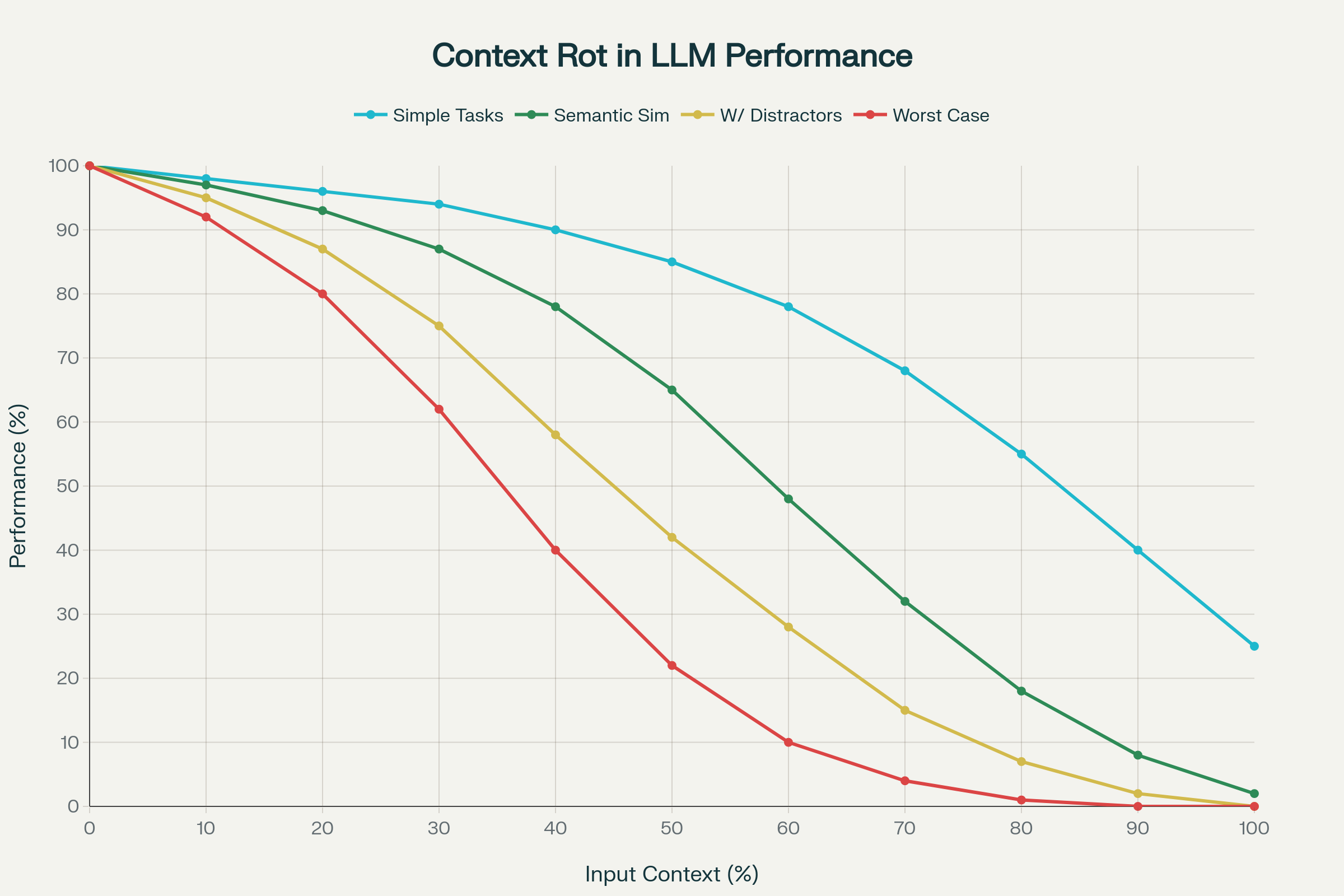
Dù khả năng kéo dài context window được ca ngợi, nghiên cứu gần đây cho thấy một thực tế đáng lo: context dài hơn không đồng nghĩa chất lượng cao hơn.
Một nghiên cứu lớn trên 18 LLM hàng đầu—gồm GPT-4.1, Claude 4, Gemini 2.5, Qwen 3—phát hiện hiện tượng context rot: hiệu suất suy giảm không thể đoán trước và thường rất mạnh khi đầu vào dài dần.
Phát Hiện Chính Về Context Rot
1. Suy giảm không đồng đều
Hiệu suất không giảm tuyến tính. Thay vào đó, mô hình có thể giảm đột ngột, khác nhau tùy model và tác vụ. Có thể giữ 95% chính xác đến một ngưỡng, rồi rơi thẳng xuống 60%. Những “vách đá” này không thể dự đoán giữa các model.
2. Độ phức tạp ngữ nghĩa làm trầm trọng context rot
Tác vụ đơn giản (lặp lại từ, truy xuất chính xác) giảm vừa phải. Nhưng với tác vụ cần gần nghĩa, thêm thông tin gây nhiễu sẽ làm giảm chính xác rõ rệt.
3. Thiên vị vị trí và attention sụp đổ
Cơ chế attention của transformer không mở rộng đều cho context dài. Token đầu (thiên vị đầu) và cuối (thiên vị cuối) được chú ý nhiều hơn. Trong trường hợp cực đoan, attention sụp đổ hoàn toàn, model bỏ qua phần lớn đầu vào.
4. Lỗi đặc thù từng mô hình
Mỗi LLM có hành vi riêng khi scale lớn:
GPT-4.1: Dễ sinh ảo tưởng, lặp lại token sai
Gemini 2.5: Thêm đoạn rời hoặc ký tự lạ
Claude Opus 4: Có thể từ chối hoặc quá thận trọng
5. Ảnh hưởng thực tế trong hội thoại
Nghiêm trọng hơn cả: ở benchmark LongMemEval, model truy cập toàn bộ hội thoại (khoảng 113k token) lại kém hơn rõ rệt khi chỉ dùng đoạn 300 token trọng tâm. Điều này chứng tỏ context rot làm giảm cả truy xuất lẫn suy luận trong môi trường thực tế.
Context Rot: Suy Giảm Hiệu Suất Khi Tăng Độ Dài Đầu Vào Trên 18 LLM
Ý Nghĩa: Chất Lượng Quan Trọng Hơn Số Lượng
Thông điệp then chốt từ nghiên cứu context rot: số lượng token đầu vào không quyết định toàn bộ chất lượng. Cách xây dựng, lọc và trình bày context quan trọng không kém, thậm chí quan trọng hơn.
Phát hiện này củng cố lý do tồn tại của kỹ thuật bối cảnh. Thay vì nghĩ context window lớn là vạn năng, các đội ngũ tinh vi nhận ra kỹ thuật bối cảnh—nén, chọn lọc, cô lập—là bắt buộc để duy trì hiệu suất với đầu vào lớn.
Kỹ Thuật Bối Cảnh Trong Thực Tiễn: Ứng Dụng Thực Tế
Case Study 1: Hệ Thống Agent Nhiều Lượt (Claude Code, Cursor)
Claude Code và Cursor là ví dụ điển hình cho kỹ thuật bối cảnh trợ giúp code:
Thu thập: Hệ thống lấy context từ nhiều nguồn—file mở, cấu trúc dự án, lịch sử chỉnh sửa, đầu ra terminal, bình luận người dùng.
Quản lý: Thay vì dồn mọi file vào prompt, họ nén thông minh. Claude Code dùng tóm tắt phân cấp. Context được gắn thẻ chức năng (ví dụ “file đang chỉnh sửa”, “phụ thuộc”, “thông báo lỗi”).
Sử dụng: Mỗi lượt, hệ thống chọn file và thành phần context liên quan, trình bày có cấu trúc, giữ riêng track cho suy luận và output.
Nén: Khi gần chạm giới hạn context, auto-compact kích hoạt, tóm tắt lại quá trình mà vẫn giữ quyết định then chốt.
Kết quả: Dụng cụ này dùng được với dự án lớn (hàng ngàn file) mà không giảm hiệu suất, dù context window hạn chế.
Case Study 2: Tongyi DeepResearch (Agent Nghiên Cứu Sâu Mã Nguồn Mở)
Tongyi DeepResearch cho thấy kỹ thuật bối cảnh cho phép thực hiện nhiệm vụ nghiên cứu phức tạp:
Pipeline tổng hợp dữ liệu: Thay vì phụ thuộc dữ liệu gán nhãn thủ công, Tongyi dùng pipeline tổng hợp tạo câu hỏi cấp độ tiến sĩ qua nhiều vòng tăng độ phức tạp. Mỗi vòng mở rộng ranh giới kiến thức và tác vụ suy luận.
Quản lý context: Hệ thống theo mô hình IterResearch—mỗi vòng nghiên cứu, workspace được tái cấu trúc chỉ giữ lại output thiết yếu từ vòng trước. Tránh “nghẹt thở nhận thức” do dồn hết thông tin vào một context window.
Khám phá song song: Nhiều agent nghiên cứu hoạt động song song với context riêng, mỗi agent đi sâu một khía cạnh. Một agent tổng hợp sẽ tích hợp kết quả cho câu trả lời hoàn chỉnh.
Kết quả: Tongyi DeepResearch đạt kết quả ngang ngửa OpenAI DeepResearch, đạt 32.9 điểm ở Humanity’s Last Exam và 75 điểm trên benchmark tập trung người dùng.
Case Study 3: Nghiên Cứu Đa Agent của Anthropic
Nghiên cứu của Anthropic chứng minh cô lập và chuyên môn hóa cải thiện hiệu suất:
Kiến trúc: Subagent chuyên trách từng nhiệm vụ nghiên cứu (tổng quan tài liệu, tổng hợp, xác minh) với context window riêng.
Lợi ích: Phương pháp này vượt trội agent đơn, mỗi subagent tối ưu context cho nhiệm vụ hẹp.
Đánh đổi: Chất lượng vượt trội, nhưng token sử dụng tăng tới 15 lần so với chat agent đơn.
Điều này chỉ ra: kỹ thuật bối cảnh luôn phải cân bằng giữa chất lượng, tốc độ, chi phí. Lựa chọn phù hợp phụ thuộc vào yêu cầu ứng dụng.
Khung Thiết Kế: Cân Nhắc Khi Xây Dựng Kỹ Thuật Bối Cảnh
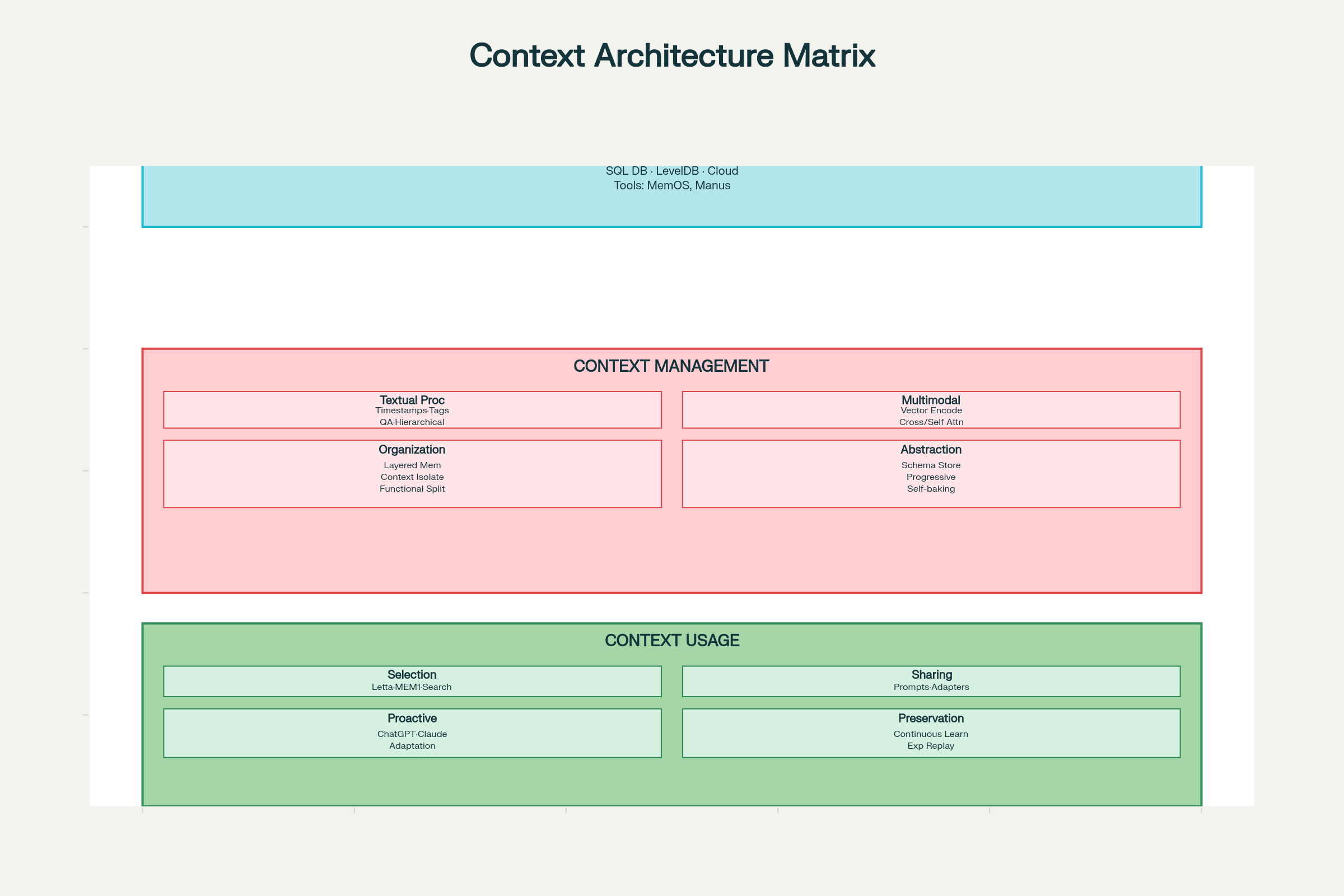
Triển khai kỹ thuật bối cảnh hiệu quả cần tư duy hệ thống ở ba chiều: thu thập & lưu trữ, quản lý, sử dụng.
Khung Thiết Kế Kỹ Thuật Bối Cảnh: Kiến Trúc Hệ Thống và Các Thành Phần
Quyết Định Thiết Kế: Thu Thập & Lưu Trữ
Lựa chọn công nghệ lưu trữ:
Local storage (SQLite, LevelDB): Nhanh, độ trễ thấp, phù hợp agent phía client
Cloud storage (DynamoDB, PostgreSQL): Mở rộng, truy cập mọi nơi
Hệ thống phân tán: Quy mô lớn, dự phòng, chịu lỗi
Mẫu thiết kế:
MemOS: Hệ điều hành bộ nhớ cho quản lý tập trung
Manus: Bộ nhớ cấu trúc với phân quyền vai trò
Nguyên tắc: Thiết kế tối ưu cho truy xuất, không chỉ lưu trữ. Hệ thống tốt là nơi bạn tìm nhanh thứ mình cần.
Quyết Định Quản Lý
Xử lý context văn bản:
Đánh dấu thời gian: Đơn giản nhưng giới hạn. Giữ thứ tự thời gian nhưng thiếu cấu trúc ngữ nghĩa, khó mở rộng.
Đánh thẻ vai trò/chức năng: Gắn thẻ từng thành phần context—“mục tiêu”, “quyết định”, “hành động”, “lỗi”… Hỗ trợ đa thẻ (ưu tiên, nguồn, độ tin cậy). Các hệ thống mới như LLM4Tag hiện thực hóa điều này ở quy mô lớn.
Nén bằng QA pairs: Chuyển tương tác thành cặp hỏi-đáp nén, giữ thông tin quan trọng, giảm token.
Ghi chú phân cấp: Nén dần thành vector ý nghĩa như H-MEM, thu tóm ngữ nghĩa nhiều lớp.
Xử lý context đa phương tiện:
Không gian vector tương đương: Mã hóa mọi loại dữ liệu (text, hình, âm thanh) vào không gian vector chung bằng embedding (như ChatGPT, Claude).
Cross-attention: Dùng một modality điều hướng attention cho cái khác (như Qwen2-VL).
Mã hóa riêng biệt với self-attention: Mỗi modality mã hóa riêng, sau đó kết hợp qua attention chung.
Tổ chức context:
Kiến trúc bộ nhớ phân lớp: Tách working memory (context hiện tại), short-term (lịch sử gần), long-term (kiến thức lâu dài).
Cô lập theo chức năng: Subagent có context window riêng cho từng chức năng (Claude dùng).
Trừu tượng hóa context (Self-Baking):
“Self-baking” là khả năng context tự cải thiện qua xử lý lặp lại. Mẫu gồm:
Lưu context thô, sau đó thêm tóm tắt tự nhiên (Claude Code, Gemini CLI)
Trích xuất fact bằng schema cố định (ChatSchema)
Nén dần thành vector ý nghĩa (H-MEM)
Quyết Định Sử Dụng
Chọn context:
Retrieval dựa trên embedding (phổ biến nhất)
Duyệt knowledge graph (mối quan hệ phức tạp)
Đánh giá tương đồng ngữ nghĩa
Trọng số ưu tiên/gần đây
Chia sẻ context:
Nội bộ hệ thống:
Nhúng context vào prompt (AutoGPT, ChatDev)
Trao đổi thông điệp cấu trúc giữa agent (Letta, MemOS)
Chia sẻ bộ nhớ qua liên lạc gián tiếp (A-MEM)
Giữa hệ thống:
Adapter chuyển đổi định dạng context (Langroid)
Đại diện chung giữa nền tảng (Sharedrop)
Suy đoán chủ động nhu cầu người dùng:
ChatGPT, Claude phân tích mẫu tương tác để đoán nhu cầu
Hệ thống context chủ động đưa thông tin trước khi được hỏi
Cân bằng sự hữu ích và quyền riêng tư là thách thức lớn
Kỹ Năng Kỹ Thuật Bối Cảnh Và Điều Đội Ngũ Cần Làm Chủ
Khi kỹ thuật bối cảnh ngày càng trọng yếu, một số kỹ năng tách biệt đội ngũ hiệu quả và những nhóm vật lộn mở rộng.
1. Lắp Ghép Bối Cảnh Chiến Lược
Đội ngũ cần hiểu thông tin nào phục vụ mỗi nhiệm vụ. Không chỉ gom dữ liệu—mà phải hiểu sâu yêu cầu để nhận diện điều thực sự cần so với nhiễu.
Thực tế:
Phân tích lỗi nhiệm vụ để tìm context thiếu
A/B test các tổ hợp context để đánh giá hiệu quả
Xây dựng hệ quan sát để biết yếu tố context nào tác động hiệu suất
2. Kiến Trúc Hệ Thống Bộ Nhớ
Thiết kế hệ memory hiệu quả đòi hỏi hiểu rõ loại và thời điểm dùng:
Khi nào nên lưu ở short-term, khi nào ở long-term?
Các loại memory nên phối hợp ra sao?
Chiến lược nén giữ độ trung thực mà giảm token thế nào?
3. Tìm Kiếm Và Truy Xuất Ngữ Nghĩa
Vượt qua tìm kiếm từ khóa đơn giản, đội ngũ phải nắm:
Mô hình embedding và giới hạn
Chỉ số tương đồng vector và đánh đổi
Chiến lược rerank, lọc
Xử lý truy vấn mơ hồ
4. Quản Lý Token Và Phân Tích Chi Phí
Mỗi byte context đều có đánh đổi:
Theo dõi token dùng cho các variant context
Hiểu chi phí xử lý token theo từng model
Cân bằng chất lượng, chi phí, độ trễ
5. Điều Phối Hệ Thống
Khi có nhiều agent, công cụ, memory, điều phối trở nên then chốt:
Phối hợp giữa subagent
Xử lý lỗi và phục hồi
Quản lý trạng thái cho tác vụ dài hơi
6. Đánh Giá, Đo Lường
Kỹ thuật bối cảnh là ngành tối ưu hóa:
Định nghĩa metric đo hiệu suất
A/B test các kỹ thuật context engineering
Đo tác động tới trải nghiệm thực tế, không chỉ độ chính xác model
Như một kỹ sư cấp cao nói, cách nhanh nhất để đưa phần mềm AI chất lượng đến khách hàng là lấy các ý tưởng nhỏ, mô-đun từ agent và tích hợp vào sản phẩm hiện có.
Thực Tiễn Tốt Nhất Khi Áp Dụng Kỹ Thuật Bối Cảnh
1. Khởi Đầu Đơn Giản, Tiến Hóa Có Chủ Đích
Bắt đầu với prompt cơ bản cộng bộ nhớ dạng scratchpad. Chỉ thêm phức tạp (đa agent, retrieval nâng cao) khi có bằng chứng cần thiết.
2. Đo Lường Mọi Thứ
Dùng công cụ như LangSmith để quan sát. Theo dõi:
Token sử dụng qua các phương pháp context engineering
Metric hiệu suất (chính xác, đúng đắn, hài lòng người dùng)
Cân nhắc chi phí – độ trễ
3. Tự Động Quản Lý Bộ Nhớ
Curation memory thủ công không mở rộng được. Thực hiện:
Tóm tắt tự động tại ranh giới context
Lọc, đánh giá liên quan thông minh
Giảm dần giá trị cho thông tin cũ
4. Thiết Kế Minh Bạch, Dễ Kiểm Tra
Chất lượng context càng quan trọng khi bạn hiểu
Câu hỏi thường gặp
Prompt engineering tập trung vào soạn thảo một chỉ dẫn cho LLM. Kỹ thuật bối cảnh là một ngành hệ thống rộng hơn, quản lý toàn bộ hệ sinh thái thông tin cho mô hình AI, bao gồm bộ nhớ, công cụ và dữ liệu truy xuất, để tối ưu hóa hiệu suất cho các tác vụ phức tạp, có trạng thái.
Context rot là sự suy giảm không thể dự đoán của hiệu suất LLM khi ngữ cảnh đầu vào ngày càng dài. Mô hình có thể giảm mạnh độ chính xác, bỏ qua một phần bối cảnh hoặc sinh ra thông tin ảo, cho thấy sự cần thiết phải quản lý chất lượng và cẩn thận đối với bối cảnh thay vì chỉ tăng số lượng.
Bốn chiến lược cốt lõi gồm: 1. Ghi Bối Cảnh (lưu trữ thông tin ngoài cửa sổ context, như scratchpad hoặc bộ nhớ), 2. Lựa Chọn Bối Cảnh (chỉ truy xuất thông tin liên quan), 3. Nén Bối Cảnh (tóm tắt hoặc cắt bớt để tiết kiệm không gian), và 4. Cô Lập Bối Cảnh (dùng hệ thống đa agent hoặc sandbox để tách biệt chức năng).
Arshia là Kỹ sư Quy trình AI tại FlowHunt. Với nền tảng về khoa học máy tính và niềm đam mê AI, anh chuyên tạo ra các quy trình hiệu quả tích hợp công cụ AI vào các nhiệm vụ hàng ngày, nâng cao năng suất và sự sáng tạo.
Arshia Kahani
Kỹ sư Quy trình AI
Làm Chủ Kỹ Thuật Bối Cảnh
Sẵn sàng xây dựng thế hệ hệ thống AI tiếp theo? Khám phá tài nguyên và công cụ của chúng tôi để ứng dụng kỹ thuật bối cảnh nâng cao vào dự án của bạn.
Tôn Vinh Kỹ Thuật Context: Xây Dựng Hệ Thống AI Sản Xuất Với Cơ Sở Dữ Liệu Vector Hiện Đại
Khám phá cách kỹ thuật context đang định hình lại phát triển AI, quá trình tiến hóa từ RAG đến hệ thống sẵn sàng sản xuất, và vì sao các cơ sở dữ liệu vector hi...
Đánh Bại Tính Không Xác Định trong LLM: Giải Quyết Khủng Hoảng Tái Lập Kết Quả của AI
Khám phá cách phòng thí nghiệm Thinking Machines Lab của Mira Murati giải quyết vấn đề không xác định trong các mô hình ngôn ngữ lớn, cho phép AI tạo ra kết quả...
19 phút đọc
AI
LLMs
+3
Đồng Ý Cookie Chúng tôi sử dụng cookie để cải thiện trải nghiệm duyệt web của bạn và phân tích lưu lượng truy cập của mình. See our privacy policy.