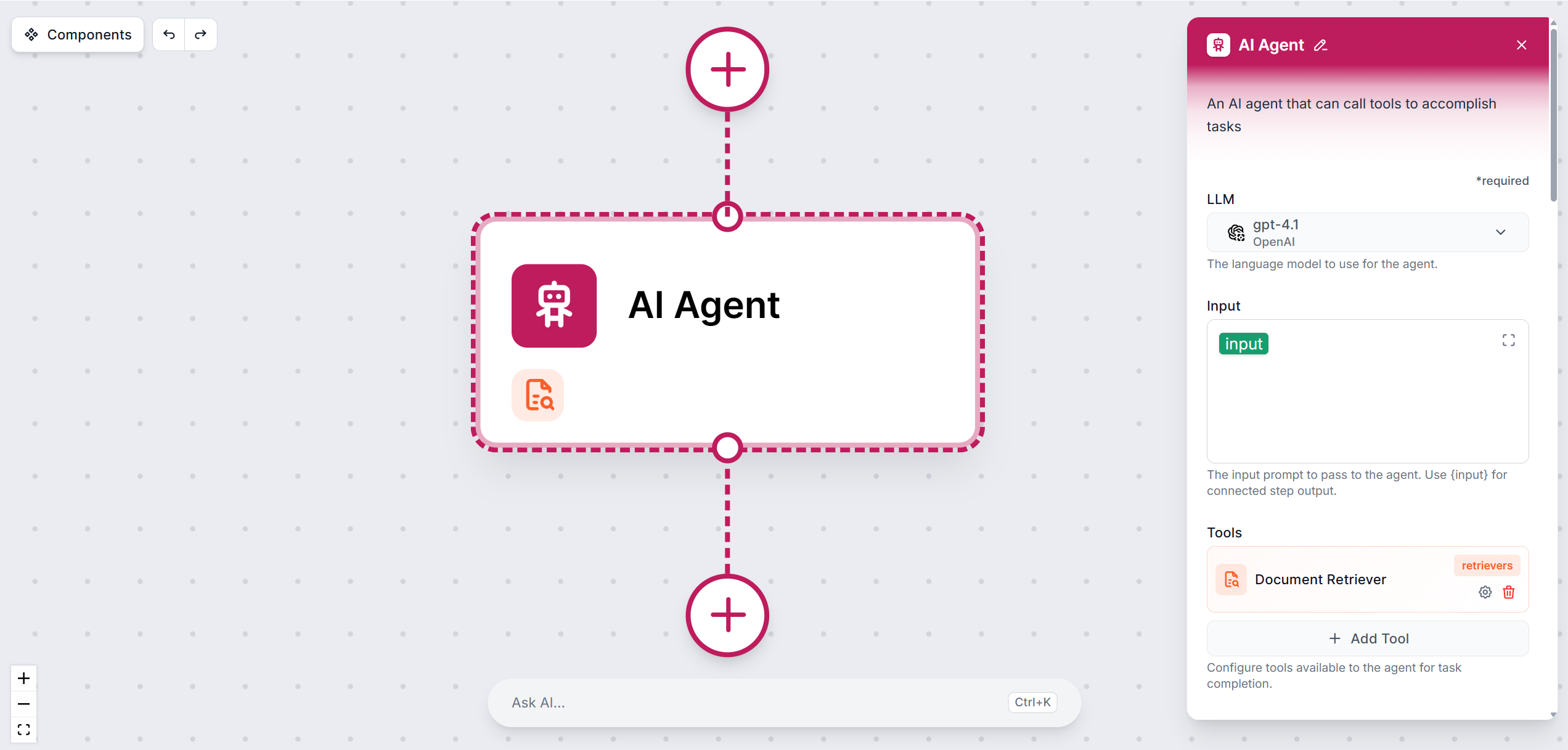
AI Agent
Làm chủ thành phần AI Agent trong quy trình làm việc FlowHunt. Tìm hiểu cách cấu hình tin nhắn hệ thống, kết nối các công cụ, chọn mô hình và tối ưu hóa hiệu su...
9 phút đọc
Components
Agents

Phân tích chuyên sâu cơ chế chèn kỹ năng của 11 nền tảng AI agent: kỹ năng được đặt ở đâu trong prompt, khi nào được tải, chi phí bao nhiêu token và cách chúng tồn tại khi ngữ cảnh bị nén.
Mọi framework AI agent đều đối mặt với cùng một câu hỏi cơ bản: làm thế nào để một LLM giỏi ở một lĩnh vực cụ thể? Bản thân mô hình có kiến thức chung rộng, nhưng khi bạn cần nó thực hiện review code, triển khai hạ tầng hoặc điều hướng trong Minecraft—nó cần các hướng dẫn chuyên biệt, quyền truy cập công cụ và ngữ cảnh lĩnh vực.
Đây chính là bài toán chèn kỹ năng. Và mỗi framework lớn giải quyết nó theo cách khác nhau.
Một số nền tảng đổ mọi thứ vào system prompt ngay từ đầu. Những nền tảng khác sử dụng tải chậm, chỉ tiết lộ khả năng khi agent cần đến. Một số ít sử dụng cơ sở dữ liệu vector để truy xuất kỹ năng liên quan dựa trên độ tương đồng ngữ nghĩa. Sự khác biệt không chỉ mang tính học thuật—chúng ảnh hưởng trực tiếp đến chi phí token, độ tin cậy của agent và số lượng kỹ năng mà agent có thể xử lý thực tế.
Chúng tôi đã phân tích 11 nền tảng AI agent lớn để hiểu chính xác kỹ năng được đặt ở đâu trong prompt, khi nào được tải, chi phí bao nhiêu token và cách chúng tồn tại khi cửa sổ ngữ cảnh đầy. Đây không phải so sánh tính năng bề mặt. Chúng tôi đã nghiên cứu mã nguồn, tài liệu và sơ đồ kiến trúc để lập bản đồ cơ chế chèn chính xác của từng nền tảng.
Đây là cái nhìn tổng quan trước khi đi vào chi tiết.
| Nền tảng | Điểm Chèn | Thời Điểm Tải | Cơ Chế |
|---|---|---|---|
| Claude Code | System-reminder (metadata) + tin nhắn hội thoại (nội dung) | Metadata khi bắt đầu phiên; nội dung khi dùng /command hoặc tự động khớp | Framework chèn metadata; Skill tool tải nội dung đầy đủ khi kích hoạt |
| CrewAI | Task prompt (thêm vào trước khi gọi LLM) | Mỗi lần thực thi task qua _finalize_task_prompt() | format_skill_context() thêm toàn bộ nội dung kỹ năng vào prompt |
| LangChain Deep Agents | System prompt (metadata) + lịch sử hội thoại (nội dung) | Metadata khi khởi động; nội dung khi agent gọi read_file() | SkillsMiddleware chèn chỉ mục; agent tải nội dung qua công cụ filesystem |
| OpenAI Responses API | Ngữ cảnh user prompt (do nền tảng quản lý) | Khi có skill_reference trong lệnh gọi API | Nền tảng thêm metadata; mô hình đọc SKILL.md đầy đủ khi gọi |
| OpenAI Agents SDK | Định nghĩa công cụ (hoãn qua ToolSearchTool) | Tên namespace khi tạo; schema khi gọi ToolSearchTool | tool_namespace() + ToolSearchTool() cho khám phá dần dần |
| AutoGen Teachability | Tin nhắn người dùng đã sửa đổi (memo truy xuất được chèn) | Mỗi lượt — truy xuất vector DB trước mỗi lần gọi LLM | Middleware chặn tin nhắn, truy vấn ChromaDB, chèn top-K kết quả |
| Semantic Kernel | Schema function-calling + nội dung mẫu prompt | Tất cả schema khi khởi động; nội dung mẫu khi gọi hàm | kernel.add_plugin() đăng ký tất cả; kernel.invoke() render mẫu |
| MetaGPT | Mẫu prompt Action (render vào lệnh gọi LLM) | Khi _act() của Role kích hoạt cho một Action cụ thể | Action.run() định dạng PROMPT_TEMPLATE, gửi qua aask() |
| Voyager | Prompt sinh code (code kỹ năng được truy xuất) | Trước mỗi lần sinh code; tìm kiếm theo embedding similarity | SkillLibrary.retrieve_skills() chèn top-5 làm ví dụ few-shot |
| DSPy | Demo few-shot đã biên dịch trong prompt module Predict | Biên dịch offline bởi optimizer; cố định khi chạy | BootstrapFewShot / MIPROv2 chọn demo tốt nhất; Predict render vào prompt |
| SuperAGI | Schema công cụ trong danh sách công cụ của agent | Khi tạo agent — tất cả công cụ toolkit đăng ký ngay | BaseToolkit.get_tools() đăng ký tất cả như công cụ function-calling |
| CAMEL-AI | Schema hàm + system message của vai trò | Khi tạo agent — tất cả công cụ đăng ký ngay | ChatAgent(tools=[*toolkit.get_tools()]) tải mọi thứ khi khởi tạo |
| Nền tảng | Luôn Hiện Diện? | Tính Lưu Trữ | Chi Phí Token |
|---|---|---|---|
| Claude Code | Metadata: CÓ. Nội dung: chỉ sau khi kích hoạt | Phạm vi phiên. Khi nén: đính kèm lại (5K/kỹ năng, giới hạn 25K) | ~250 ký tự/metadata kỹ năng; 1% ngân sách ngữ cảnh |
| CrewAI | CÓ — toàn bộ nội dung trong mỗi task prompt | Chèn mới mỗi task; không lưu trữ giữa các task | Toàn bộ nội dung mỗi lần gọi. Giới hạn mềm 50K ký tự |
| LangChain Deep Agents | Metadata: CÓ. Nội dung: theo yêu cầu | Nội dung nằm trong lịch sử hội thoại; kỹ năng subagent được cách ly | ~100 token/metadata kỹ năng; nội dung trả một lần (~3,302 token) |
| OpenAI Responses API | Tên+mô tả: CÓ. Nội dung đầy đủ: khi gọi | Chỉ trong một phản hồi API; không lưu trữ giữa các lần gọi | Do nền tảng quản lý |
| OpenAI Agents SDK | Danh sách namespace: CÓ. Schema: theo yêu cầu | Chỉ trong một lần chạy; khám phá lại mỗi phiên | Tối thiểu cho đến khi kích hoạt |
| AutoGen Teachability | KHÔNG — chỉ memo liên quan mỗi lượt | Xuyên phiên qua ChromaDB; lưu trữ vĩnh viễn | ~3-5 memo mỗi lượt (thay đổi) |
| Semantic Kernel | Tất cả schema: CÓ. Mẫu: khi gọi | Trong bộ nhớ mỗi instance kernel; không xuyên phiên | Tất cả schema luôn hiện diện |
| MetaGPT | KHÔNG — chỉ mẫu Action hiện tại | Chỉ trong một lần thực thi action | Một mẫu mỗi lượt |
| Voyager | KHÔNG — top-5 truy xuất mỗi tác vụ | Lưu trữ suốt đời trong vector DB | ~500-2,000 token mỗi ví dụ kỹ năng |
| DSPy | CÓ — demo đã biên dịch được nhúng cố định | Có thể serialize sang JSON; lưu trữ xuyên phiên | Cố định sau biên dịch (3-8 demo/module) |
| SuperAGI | CÓ — tất cả schema luôn hiện diện | Trong phiên agent | Tất cả schema luôn hiện diện |
| CAMEL-AI | CÓ — tất cả schema + prompt vai trò | Trong phiên hội thoại | Tất cả schema luôn hiện diện |
Bắt đầu dùng thử miễn phí ngay hôm nay và xem kết quả trong vài ngày.
Trước khi đi sâu vào so sánh, hãy định nghĩa phạm vi bài toán. Cửa sổ ngữ cảnh của AI agent—tổng lượng văn bản mà LLM nhìn thấy mỗi lần gọi—có kích thước cố định. Mỗi token của hướng dẫn, lịch sử hội thoại, định nghĩa công cụ và dữ liệu truy xuất đều cạnh tranh không gian trong cửa sổ đó.
“Kỹ năng” trong ngữ cảnh agent là bất kỳ gói chuyên môn có cấu trúc nào thay đổi cách agent hoạt động. Điều này có thể là:
Cơ chế chèn—nội dung đó đi vào ngữ cảnh ở đâu và khi nào—quyết định ba thuộc tính quan trọng:
Mỗi framework đưa ra các đánh đổi khác nhau trên ba chiều này. Hãy xem xét từng framework.
Trên tất cả 11 nền tảng, các phương pháp chèn kỹ năng nằm trên một phổ từ “tải mọi thứ ngay từ đầu” đến “không tải gì cho đến khi được yêu cầu rõ ràng.”
Ở một đầu, các nền tảng như CrewAI, SuperAGI và CAMEL-AI chèn toàn bộ nội dung của mỗi kỹ năng đã kích hoạt vào mỗi lần gọi LLM. Agent luôn có đầy đủ chuyên môn sẵn sàng. Đơn giản, đáng tin cậy, nhưng tốn token.
Ở đầu kia, Claude Code, LangChain Deep Agents và Responses API của OpenAI sử dụng tiết lộ dần dần—agent chỉ thấy tên kỹ năng và mô tả ngắn khi khởi động, và nội dung đầy đủ được tải theo yêu cầu. Hiệu quả, có khả năng mở rộng, nhưng đòi hỏi agent phải nhận biết khi nào cần một kỹ năng.
Ở giữa, AutoGen Teachability và Voyager sử dụng truy xuất ngữ nghĩa để chỉ chèn các kỹ năng liên quan nhất mỗi lượt, tạo ra mẫu chèn động, nhạy cảm với ngữ cảnh.
Và rồi có những cách tiếp cận độc đáo: DSPy biên dịch các ví dụ few-shot tối ưu offline và nhúng vĩnh viễn vào prompt module. MetaGPT mã hóa kỹ năng dưới dạng mẫu hành động chỉ kích hoạt khi một vai trò cụ thể chuyển sang một hành động cụ thể.
Hãy xem xét chi tiết từng framework.
Nhận các mẹo, xu hướng và ưu đãi mới nhất miễn phí.

Claude Code triển khai một trong những kiến trúc chèn kỹ năng tinh vi nhất, sử dụng hệ thống tiết lộ dần dần ba lớp cân bằng giữa nhận thức và hiệu quả token.
Khi bắt đầu phiên, tên và mô tả của mỗi kỹ năng khả dụng được chèn vào tin nhắn system-reminder—một khối metadata mà mô hình luôn nhìn thấy. Chi phí khoảng 250 ký tự mỗi kỹ năng, tiêu tốn khoảng 1% ngân sách cửa sổ ngữ cảnh cho tất cả mô tả kỹ năng kết hợp (khoảng 8K ký tự làm ngân sách dự phòng, có thể ghi đè qua biến môi trường SLASH_COMMAND_TOOL_CHAR_BUDGET).
Tương tự, các công cụ hoãn tải—những công cụ chưa được tải schema JSON đầy đủ—xuất hiện dưới dạng danh sách chỉ tên trong các khối system-reminder. Tính từ Claude Code v2.1.69, ngay cả các công cụ hệ thống tích hợp như Bash, Read, Edit, Write, Glob và Grep đều được hoãn sau ToolSearch, giảm ngữ cảnh công cụ hệ thống từ khoảng 14-16K token xuống còn khoảng 968 token.
Agent thấy đủ để biết những gì khả dụng mà không phải trả chi phí token cho các định nghĩa đầy đủ.
Khi người dùng gõ lệnh slash (ví dụ /commit) hoặc mô hình tự động khớp kỹ năng dựa trên mô tả, nội dung đầy đủ SKILL.md được tải dưới dạng tin nhắn hội thoại qua Skill tool. Nội dung này chứa toàn bộ hướng dẫn—đôi khi hàng nghìn token hướng dẫn chi tiết.
Chi tiết quan trọng: Tiền xử lý shell chạy trước (bất kỳ chỉ thị !command nào trong file kỹ năng đều được thực thi và đầu ra thay thế chỉ thị), và sau khi tải, nội dung kỹ năng tồn tại trong hội thoại cho phần còn lại của phiên.
Các tài nguyên bổ sung—tài liệu tham khảo, script, file asset—chỉ được đọc khi mô hình chủ động quyết định sử dụng công cụ Read để truy cập chúng. Chúng không bao giờ tải tự động.
Khi hội thoại tiến gần giới hạn ngữ cảnh và quá trình nén được kích hoạt, Claude Code đính kèm lại các kỹ năng được gọi gần nhất với ngân sách 5K token mỗi kỹ năng và tối đa 25K kết hợp. Các kỹ năng được gọi gần nhất có ưu tiên cao nhất. Các kỹ năng cũ hơn có thể bị loại bỏ hoàn toàn.
Kiến trúc ba lớp này có nghĩa là agent với hơn 20 kỹ năng khả dụng chỉ phải trả chi phí ban đầu tối thiểu nhưng có thể truy cập đầy đủ chuyên môn về bất kỳ kỹ năng nào trong một lượt duy nhất.

CrewAI áp dụng cách tiếp cận ngược lại với tiết lộ dần dần. Khi một kỹ năng được kích hoạt cho agent, toàn bộ nội dung được chèn vào mỗi task prompt mà agent thực thi.
Kỹ năng trong CrewAI là các thư mục độc lập, mỗi thư mục có file SKILL.md chứa frontmatter YAML (tên, mô tả, giấy phép, tương thích, công cụ được phép) và nội dung markdown. Hệ thống kỹ năng phân biệt giữa kỹ năng và công cụ: kỹ năng chèn hướng dẫn và ngữ cảnh định hình cách agent suy nghĩ, trong khi công cụ cung cấp các hàm có thể gọi cho hành động.
Trong quá trình khởi tạo agent, Agent.set_skills() gọi discover_skills() để quét thư mục kỹ năng ở cấp metadata, sau đó activate_skill() để đọc nội dung đầy đủ. Khi thực thi task, _finalize_task_prompt() gọi format_skill_context() cho mỗi kỹ năng đã kích hoạt và thêm tất cả nội dung kỹ năng đã định dạng vào task prompt.
LLM nhận được: [system message] + [task prompt + TẤT CẢ nội dung kỹ năng]
CrewAI đặt cảnh báo mềm ở 50,000 ký tự mỗi kỹ năng nhưng không có giới hạn cứng. Tài liệu khuyến nghị giữ kỹ năng tập trung và ngắn gọn vì việc chèn prompt lớn làm phân tán sự chú ý của mô hình—mối lo ngại thực tế dựa trên nghiên cứu về suy giảm ngữ cảnh.
Sự đánh đổi rất rõ ràng: agent luôn có đầy đủ chuyên môn sẵn sàng (độ tin cậy cao), nhưng chi phí token tăng tuyến tính theo số lượng kỹ năng mỗi task (hiệu quả thấp). Đối với agent có 1-2 kỹ năng tập trung, cách này hoạt động tốt. Đối với agent cần bộ khả năng rộng, chi phí tăng nhanh.
Mỗi task được chèn mới. Không có sự tích lũy nội dung kỹ năng giữa các task—điều này thực ra là tính năng chứ không phải lỗi. Nó đảm bảo mỗi task bắt đầu với ngữ cảnh sạch, tránh các vấn đề cũ kỹ mà lưu trữ theo phiên có thể tạo ra.

LangChain Deep Agents triển khai hệ thống kỹ năng dựa trên middleware tinh vi, trong đó chính agent quyết định khi nào tải nội dung đầy đủ—một mô hình tiết lộ dần dần thực sự nơi agent kiểm soát việc kích hoạt.
Tầng 1 (Chỉ Mục): SkillsMiddleware phân tích frontmatter của tất cả SKILL.md khi khởi động và chèn chỉ mục nhẹ vào system prompt. Chỉ mục này chỉ chứa tên và mô tả, chi phí khoảng 278 token mỗi kỹ năng so với 3,302 token cho nội dung đầy đủ.
Tầng 2 (Nội Dung Đầy Đủ): Khi agent xác định kỹ năng liên quan, nó gọi read_file() trên đường dẫn SKILL.md của kỹ năng. Đây là lệnh gọi công cụ bình thường—framework không chèn nội dung; agent đưa ra quyết định có chủ đích để tải nó. Nội dung đầy đủ đi vào lịch sử hội thoại dưới dạng kết quả công cụ.
Tầng 3 (Đào Sâu): Tài liệu hỗ trợ, tài liệu tham khảo và script chỉ được truy cập khi agent chủ động đọc chúng.
Với 12 kỹ năng, tiết lộ dần dần giảm ngữ cảnh từ khoảng 30,000 token (tải tất cả) xuống còn khoảng 600 token (chỉ chỉ mục), mở rộng lên 2,000-5,000 khi các kỹ năng liên quan được tải cho tác vụ cụ thể. Đó là tiềm năng giảm 83-98% lượng token liên quan đến kỹ năng.
Nhiều nguồn kỹ năng có thể được xếp chồng, và khi tên trùng, nguồn cuối cùng thắng. File trên 10 MB tự động bị bỏ qua.
Trong khi Claude Code sử dụng Skill tool chuyên dụng để kích hoạt tải, Deep Agents tái sử dụng công cụ read_file sẵn có của agent. Điều này có nghĩa cơ chế tải minh bạch—agent đọc file kỹ năng cùng cách nó đọc bất kỳ file nào khác. Nhược điểm là không có hành vi nén đặc biệt: nội dung kỹ năng đi vào lịch sử hội thoại chịu quá trình cắt tỉa tin nhắn tiêu chuẩn của LangChain, không có ưu tiên đặc biệt.

OpenAI triển khai chèn kỹ năng thông qua hai cơ chế riêng biệt nhưng có cùng triết lý: kiểu công cụ tool_search của Responses API và ToolSearchTool của Agents SDK.
Kiểu công cụ tool_search (khả dụng trên GPT-5.4+) cho phép nhà phát triển hoãn các bề mặt công cụ lớn cho đến khi chạy. Ba chiến lược hoãn khả dụng:
@function_tool(defer_loading=True) — mô hình thấy tên hàm và mô tả nhưng schema tham số được hoãn. Tiết kiệm token ở cấp tham số.tool_namespace(name=..., description=..., tools=[...]) — nhóm các hàm dưới một namespace duy nhất. Mô hình chỉ thấy tên và mô tả namespace, tiết kiệm đáng kể token hơn.HostedMCPTool(tool_config={..., "defer_loading": True}) — hoãn toàn bộ bề mặt công cụ MCP server.Khi mô hình xác định cần một công cụ cụ thể, nó phát lệnh gọi tool_search. API trả về 3-5 định nghĩa công cụ liên quan, được chèn vào cuối cửa sổ ngữ cảnh để bảo toàn prompt caching.
Agents SDK cung cấp tương đương lập trình. Namespace công cụ được đăng ký nhưng không được tải:
crm_tools = tool_namespace(
name="crm",
description="CRM management tools",
tools=[...]
)
agent = Agent(tools=[*crm_tools, ToolSearchTool()])
Khi chạy, agent chỉ thấy tên namespace. Nó gọi ToolSearchTool("crm") để khám phá và tải schema đầy đủ, sau đó có thể gọi các công cụ riêng lẻ trong namespace đó.
Mỗi yêu cầu API là độc lập. Các công cụ đã khám phá không lưu trữ giữa các lần gọi. Đây là cách tiếp cận phi trạng thái nhất trong so sánh của chúng tôi—sạch, dễ đoán, nhưng đòi hỏi khám phá lại mỗi yêu cầu nếu công cụ thay đổi.

Khả năng Teachability của AutoGen áp dụng cách tiếp cận khác biệt cơ bản so với mọi framework khác trong so sánh này. Thay vì chèn nội dung kỹ năng tĩnh, nó truy xuất động các “memo” liên quan từ cơ sở dữ liệu vector ChromaDB trên mỗi lượt đơn lẻ.
Teachability đăng ký hook trên process_last_received_message chặn mỗi tin nhắn người dùng đến trước khi agent xử lý:
TextAnalyzerAgent trích xuất các khái niệm chính từ tin nhắn đếnmax_num_retrievals, mặc định 10)Điều quan trọng là tin nhắn đã sửa đổi không lan truyền vào lịch sử hội thoại đã lưu—chỉ tin nhắn gốc được lưu. Điều này ngăn nội dung memo tích lũy qua các lượt.
Sau khi LLM phản hồi, hook thứ hai phân tích phản hồi để tìm kiến thức mới:
TextAnalyzerAgent xác định kiến thức mới trong phản hồiĐiều này tạo ra vòng lặp học thực sự nơi agent tích lũy chuyên môn theo thời gian.
AutoGen Teachability là một trong ba nền tảng duy nhất trong so sánh của chúng tôi (cùng với Voyager và DSPy) lưu trữ kỹ năng xuyên phiên. Cơ sở dữ liệu ChromaDB nằm trên ổ đĩa, nghĩa là agent có thể học từ tương tác ngày thứ Hai và áp dụng kiến thức đó vào thứ Sáu.
Tham số recall_threshold (mặc định 1.5) kiểm soát mức độ tương đồng cần thiết giữa tin nhắn và memo đã lưu để truy xuất, và reset_db có thể xóa toàn bộ bộ nhớ khi cần.
Vì chỉ các memo liên quan được chèn mỗi lượt (thường 3-5), chi phí token được giới hạn tự nhiên bất kể cơ sở dữ liệu memo lớn đến đâu. Agent với 10,000 memo đã lưu vẫn chỉ trả chi phí cho một số ít liên quan nhất với lượt hiện tại.

Semantic Kernel của Microsoft áp dụng cách tiếp cận trực tiếp: plugin là tập hợp các đối tượng KernelFunction được đăng ký với Kernel, và schema của chúng được hiển thị cho LLM dưới dạng định nghĩa công cụ function-calling.
Function Calling: Khi ToolCallBehavior.AutoInvokeKernelFunctions được thiết lập, tất cả hàm đã đăng ký được gửi cho LLM dưới dạng công cụ khả dụng trong mỗi yêu cầu API. LLM quyết định gọi hàm nào; Semantic Kernel xử lý việc gọi và chuyển kết quả.
Mẫu Prompt: Cú pháp mẫu của Semantic Kernel ({{plugin.function}}, Handlebars hoặc Liquid) cho phép gọi hàm inline trong quá trình render prompt. Kết quả được nhúng trực tiếp vào văn bản prompt trước khi đến LLM—một dạng đánh giá háo hức thay vì gọi công cụ lười.
Schema của mỗi plugin đã đăng ký được bao gồm trong mỗi lệnh gọi API. Không có tải hoãn tích hợp, nhóm namespace hay kích hoạt theo yêu cầu. Tài liệu khuyến nghị rõ ràng chỉ import các plugin cần thiết cho kịch bản cụ thể để giảm tiêu thụ token và lỗi gọi nhầm.
Điều này làm Semantic Kernel trở thành một trong những nền tảng dễ đoán nhất—bạn luôn biết chính xác agent có quyền truy cập gì—nhưng hạn chế khả năng mở rộng. Agent với 50 hàm đã đăng ký phải trả toàn bộ chi phí schema trên mỗi lần gọi.
Đăng ký plugin theo từng instance Kernel và trong bộ nhớ. Không có cơ chế tích hợp cho lưu trữ kỹ năng xuyên phiên.

MetaGPT mã hóa kỹ năng không phải dưới dạng gói độc lập mà dưới dạng mẫu hành động được nhúng trong các Quy Trình Vận Hành Tiêu Chuẩn (SOP) điều khiển hành vi vai trò.
Mỗi Role trong MetaGPT có tiền tố persona được chèn vào prompt và một tập các lớp Action. Mỗi Action chứa một proxy LLM được gọi qua aask(), sử dụng mẫu prompt ngôn ngữ tự nhiên để cấu trúc lệnh gọi LLM.
Khi Role._act() kích hoạt, nó hỗ trợ ba chế độ react:
"react": LLM chọn hành động động trong các vòng lặp suy nghĩ-hành động"by_order": Các hành động thực thi tuần tự theo thứ tự đã định"plan_and_act": Agent lập kế hoạch trước, sau đó thực thi hành động theo kế hoạchChỉ mẫu prompt của Action hiện tại hoạt động tại bất kỳ thời điểm nào. Agent không thấy mẫu của các action khác—nó chỉ thấy tiền tố vai trò cộng ngữ cảnh của action cụ thể. Đây là cửa sổ chèn hẹp nhất trong tất cả framework chúng tôi khảo sát.
Các hàm phân tích ngữ cảnh trong các lớp Action trích xuất thông tin liên quan từ đầu vào, nên mỗi action nhận được tập con ngữ cảnh được chọn lọc thay vì toàn bộ lịch sử hội thoại.
Mẫu được render mới cho mỗi lần thực thi action. Không có tích lũy hay lưu trữ xuyên phiên. Điều này giữ mỗi action tập trung nhưng có nghĩa agent không thể xây dựng trên nội dung kỹ năng đã tải trước đó trong một workflow duy nhất.

Voyager, agent khám phá Minecraft từ NVIDIA và Caltech, triển khai một trong những kiến trúc chèn kỹ năng thanh lịch nhất: thư viện chương trình đã xác minh ngày càng mở rộng, được truy xuất theo độ tương đồng embedding.
Khi Voyager viết code vượt qua xác minh tự động (JavaScript Mineflayer được tạo thực sự hoạt động trong game), code và chuỗi tài liệu được lưu trong cơ sở dữ liệu vector. Embedding docstring trở thành khóa truy xuất.
Với mỗi tác vụ mới do curriculum tự động đề xuất:
Prompt trông như sau:
You are a Minecraft bot. Here are some relevant skills you've learned:
// Skill: mineWoodLog
async function mineWoodLog(bot) { ... }
// Skill: craftPlanks
async function craftPlanks(bot) { ... }
Now write code to: build a wooden pickaxe
Code được tạo có thể gọi kỹ năng đã truy xuất theo tên, cho phép xây dựng kỹ năng có tính tổ hợp—các hành vi phức tạp được xây dựng từ các nguyên thủy đơn giản đã xác minh.
Thư viện kỹ năng là cơ chế “học suốt đời” cốt lõi. Nó phát triển trong suốt vòng đời của agent, và kỹ năng mới xây dựng trên kỹ năng cũ. Khác với hầu hết framework nơi kỹ năng được con người tạo ra, kỹ năng của Voyager được tạo, xác minh và lưu trữ bởi chính agent.
Chi phí token được giới hạn tự nhiên: bất kể thư viện chứa 50 hay 5,000 kỹ năng, mỗi tác vụ chỉ trả cho 5 truy xuất liên quan nhất.

DSPy áp dụng cách tiếp cận khác biệt hoàn toàn so với mọi framework khác. Thay vì chèn kỹ năng khi chạy, DSPy biên dịch các demo few-shot tối ưu offline và nhúng vĩnh viễn vào prompt module.
Hai bộ tối ưu chính xử lý biên dịch:
BootstrapFewShot: Sử dụng module teacher để tạo trace qua chương trình. Các trace vượt qua metric do người dùng định nghĩa được giữ làm demo. Mỗi module dspy.Predict trong chương trình nhận bộ demo được chọn lọc riêng.
MIPROv2 (Multi-prompt Instruction Proposal Optimizer v2): Quy trình ba giai đoạn:
Các tham số như max_bootstrapped_demos (ví dụ được tạo) và max_labeled_demos (từ dữ liệu huấn luyện) kiểm soát số lượng ví dụ kết thúc trong prompt mỗi module.
Sau khi biên dịch, các demo được lưu trong thuộc tính demos của mỗi module Predict và được định dạng vào prompt trên mỗi lần gọi LLM. Chúng không thay đổi khi chạy—“kỹ năng” bị đóng băng.
Điều này có nghĩa kỹ năng DSPy là dễ đoán nhất trong so sánh: chi phí token được biết sau biên dịch, không có biến động giữa các lượt, và agent luôn thấy cùng demo. Nhược điểm là thiếu linh hoạt—để thay đổi kỹ năng, bạn phải biên dịch lại.
Chương trình đã biên dịch serialize sang JSON, bao gồm tất cả demo. Chúng lưu trữ hoàn toàn và có thể tải xuyên phiên, làm DSPy trở thành một trong những cơ chế lưu trữ kỹ năng bền vững nhất.

SuperAGI sử dụng mẫu toolkit truyền thống nơi tất cả công cụ được đăng ký khi khởi tạo agent.
Mỗi toolkit kế thừa BaseToolkit với:
name và descriptionget_tools() trả về danh sách instance BaseToolget_env_keys() cho các biến môi trường bắt buộcToolkit được cài đặt từ repository GitHub qua trình quản lý công cụ của SuperAGI. Khi khởi tạo agent, BaseToolkit.get_tools() trả về tất cả công cụ, và schema đầy đủ được hiển thị cho LLM dưới dạng định nghĩa function-calling.
Không có tải hoãn, không tiết lộ dần dần và không lọc theo lượt. Schema của mỗi công cụ đã đăng ký hiện diện trong mỗi lần gọi. Đây là mô hình chèn đơn giản nhất và hoạt động tốt cho agent với bộ công cụ nhỏ, tập trung nhưng không mở rộng được cho agent cần hàng chục khả năng.
CAMEL-AI tuân theo mẫu đăng ký ngay tương tự. Các công cụ từ nhiều toolkit (ví dụ MathToolkit, SearchToolkit) được truyền dưới dạng danh sách cho ChatAgent(tools=[...]) khi khởi tạo.
Framework nhấn mạnh rằng các hàm tùy chỉnh cần tên tham số rõ ràng và docstring toàn diện để mô hình hiểu cách sử dụng—schema công cụ là nội dung “kỹ năng” duy nhất mà mô hình thấy. Không có cơ chế chèn hướng dẫn riêng.
Các bổ sung gần đây bao gồm hỗ trợ MCP (Model Context Protocol) qua MCPToolkit, cho phép ChatAgent kết nối với MCP server và đăng ký công cụ bên ngoài. Điều này mở rộng bề mặt công cụ khả dụng nhưng không thay đổi mô hình chèn—tất cả công cụ MCP đã phát hiện vẫn được đăng ký ngay.
| Thời điểm | Nền tảng | Nội dung được chèn |
|---|---|---|
| Luôn hiện diện (bắt đầu phiên) | Claude Code, CrewAI, Deep Agents, Semantic Kernel, SuperAGI, CAMEL-AI, DSPy | Metadata (tên + mô tả) hoặc schema đầy đủ |
| Khi kích hoạt (người dùng hoặc agent kích hoạt) | Claude Code, Deep Agents, OpenAI | Nội dung kỹ năng đầy đủ |
| Mỗi task/lượt | CrewAI, AutoGen Teachability | Nội dung đầy đủ (CrewAI) hoặc memo truy xuất (AutoGen) |
| Khi LLM chọn | Semantic Kernel, MetaGPT | Nội dung mẫu prompt |
| Khi khớp tương đồng | Voyager, AutoGen Teachability | Code hoặc memo được truy xuất |
| Đã biên dịch/cố định | DSPy | Ví dụ few-shot đã tối ưu |
| Tính lưu trữ | Nền tảng | Cơ chế |
|---|---|---|
| Chỉ một lượt | MetaGPT, Voyager | Mẫu render mỗi action / mỗi lần sinh |
| Trong phiên | Claude Code, Deep Agents, OpenAI, Semantic Kernel | Nội dung nằm trong lịch sử tin nhắn |
| Chèn lại mỗi task | CrewAI, SuperAGI, CAMEL-AI | Thêm mới mỗi lần thực thi task |
| Xuyên phiên (lưu trữ vĩnh viễn) | AutoGen Teachability, Voyager, DSPy | Vector DB / module đã biên dịch / thư viện kỹ năng |
| Nền tảng | Điều Gì Xảy Ra Khi Ngữ Cảnh Đầy |
|---|---|
| Claude Code | Đính kèm lại kỹ năng gần nhất (5K token mỗi cái, giới hạn 25K). Kỹ năng cũ bị loại bỏ |
| CrewAI | Không áp dụng—chèn mới mỗi task, không tích lũy |
| Deep Agents | Nội dung trong lịch sử hội thoại, chịu cắt tỉa tiêu chuẩn LangChain |
| OpenAI | Không áp dụng—mỗi lệnh gọi API độc lập |
| AutoGen | Chỉ memo liên quan được truy xuất mỗi lượt, giới hạn tự nhiên |
| Voyager | Chỉ top-K kỹ năng truy xuất mỗi tác vụ, giới hạn tự nhiên |
Xu hướng kiến trúc quan trọng nhất trên các nền tảng này là việc áp dụng tiết lộ dần dần—khái niệm mượn từ thiết kế giao diện người dùng nơi thông tin được tiết lộ dần dần theo nhu cầu.
Cách tiếp cận đơn giản với chèn kỹ năng—tải mọi thứ ngay—tạo ra hai vấn đề:
Tiết lộ dần dần giải quyết cả hai vấn đề bằng cách duy trì chỉ mục nhẹ các kỹ năng khả dụng trong khi chỉ tải nội dung đầy đủ khi cần.
Claude Code sử dụng hệ thống chuyên dụng: metadata kỹ năng trong tin nhắn system-reminder, Skill tool cho kích hoạt và ToolSearch cho schema công cụ hoãn. Framework quản lý việc chèn tự động với nén dựa trên ưu tiên.
LangChain Deep Agents sử dụng khả năng đọc file sẵn có của agent: SkillsMiddleware chèn chỉ mục, và agent tải nội dung đầy đủ qua read_file(). Cách này minh bạch hơn nhưng ít tối ưu ở cấp framework.
OpenAI Responses API sử dụng nhóm theo namespace với tìm kiếm do nền tảng quản lý: namespace công cụ cung cấp mô tả cấp cao, và tool_search trả về schema liên quan. Nền tảng xử lý hoàn toàn logic tìm kiếm.
Các con số rất thuyết phục. Với 12 kỹ năng:
Đó là giảm 83-98% lượng token liên quan đến kỹ năng mỗi lượt. Qua phiên dài với hàng trăm lượt, khoản tiết kiệm tích lũy đáng kể.
Nhìn tổng quan trên 11 nền tảng, bốn mẫu kiến trúc riêng biệt xuất hiện:
Được sử dụng bởi: CrewAI, SuperAGI, CAMEL-AI, Semantic Kernel
Cách hoạt động: Toàn bộ nội dung kỹ năng hoặc schema công cụ hiện diện trong mỗi lần gọi LLM.
Ưu điểm:
Nhược điểm:
Phù hợp nhất cho: Agent tập trung với 1-3 kỹ năng cốt lõi luôn liên quan.
Được sử dụng bởi: Claude Code, LangChain Deep Agents, OpenAI Responses API/Agents SDK
Cách hoạt động: Metadata nhẹ luôn hiện diện; nội dung đầy đủ tải theo yêu cầu.
Ưu điểm:
Nhược điểm:
Phù hợp nhất cho: Agent đa mục đích cần truy cập nhiều khả năng nhưng chỉ dùng vài cái mỗi tác vụ.
Được sử dụng bởi: AutoGen Teachability, Voyager
Cách hoạt động: Truy vấn cơ sở dữ liệu vector tìm kỹ năng/kiến thức liên quan dựa trên độ tương đồng ngữ nghĩa với ngữ cảnh hiện tại.
Ưu điểm:
Nhược điểm:
Phù hợp nhất cho: Agent học từ kinh nghiệm và cần tích lũy kiến thức lĩnh vực theo thời gian.
Được sử dụng bởi: DSPy, MetaGPT
Cách hoạt động: Kỹ năng được biên dịch thành nội dung prompt cố định (DSPy) hoặc kích hoạt qua mẫu action cứng (MetaGPT).
Ưu điểm:
Nhược điểm:
Phù hợp nhất cho: Pipeline sản xuất với tác vụ được định nghĩa rõ nơi độ tin cậy quan trọng hơn tính linh hoạt.
Kiến trúc chèn kỹ năng phù hợp phụ thuộc vào hồ sơ agent của bạn:
Nếu agent có vai trò hẹp, được định nghĩa rõ (ví dụ bot review code, agent hỗ trợ khách hàng cho một sản phẩm), chèn luôn bật (mẫu CrewAI/SuperAGI) đơn giản và đáng tin cậy nhất. Chi phí token của 2-3 kỹ năng luôn hiện diện có thể quản lý được, và bạn tránh được sự phức tạp của logic kích hoạt.
Nếu agent cần khả năng rộng nhưng chỉ dùng vài cái mỗi tương tác (ví dụ trợ lý lập trình, agent tự động hóa đa mục đích), tiết lộ dần dần (mẫu Claude Code/Deep Agents) là lựa chọn rõ ràng. Khoản tiết kiệm 83-98% token ở quy mô quá đáng kể để bỏ qua.
Nếu agent cần học và cải thiện từ tương tác (ví dụ trợ lý cá nhân, chuyên gia lĩnh vực tích lũy kiến thức), truy xuất ngữ nghĩa (mẫu AutoGen Teachability) cung cấp vòng lặp học mà các mẫu khác thiếu. Chỉ cần đảm bảo bạn có kiểm soát chất lượng cho những gì đi vào cơ sở kiến thức.
Nếu agent chạy pipeline được định nghĩa rõ (ví dụ xử lý dữ liệu, tạo báo cáo, workflow tiêu chuẩn), chèn biên dịch (mẫu DSPy) cho bạn hành vi dự đoán được, tối ưu nhất.
Đối với đội agent sản xuất nơi agent cần hoạt động ngay lập tức, chúng tôi khuyến nghị phương pháp kết hợp:
Kỹ năng cốt lõi (1-2 mỗi agent, xác định chuyên môn lĩnh vực chính): luôn chèn vào system prompt, kiểu CrewAI. Đây là khả năng không thể thiếu mà agent cần ở mỗi lượt.
Kỹ năng mở rộng (khả năng bổ sung agent có thể cần): chỉ metadata trong system prompt, tải qua cơ chế tìm kiếm/tải khi cần, kiểu Deep Agents. Chúng mở rộng bộ khả năng của agent mà không phải trả chi phí token khi không liên quan.
Kiến thức đã học (chuyên môn lĩnh vực tích lũy): lưu trong cơ sở dữ liệu vector và truy xuất ngữ nghĩa mỗi lượt, kiểu AutoGen. Điều này cho phép agent cải thiện theo thời gian mà không cần tạo kỹ năng thủ công.
Kiến trúc phân lớp này ánh xạ tự nhiên với cách system prompt được xây dựng: ngày → persona → hướng dẫn hệ thống → kỹ năng cốt lõi → chỉ mục kỹ năng → ngữ cảnh vai trò/đội. Kỹ năng cốt lõi và chỉ mục thêm chi phí token dự đoán được, trong khi nội dung kỹ năng đầy đủ chỉ xuất hiện khi cần.
Bất kể bạn sử dụng mẫu chèn nào, các chiến lược quản lý token sau áp dụng phổ quát:
Xếp ngữ cảnh không thay đổi (hướng dẫn hệ thống, schema công cụ) ở đầu prompt. Trên các nhà cung cấp hỗ trợ prompt caching, token được cache giảm 75% chi phí. Claude Code và OpenAI đều chèn schema công cụ đã khám phá ở cuối ngữ cảnh cụ thể để bảo toàn cache hit trên phần tĩnh phía trước.
Tóm tắt phản hồi công cụ thay vì giữ toàn bộ kết quả trong ngữ cảnh. Lưu dữ liệu đầy đủ trong tham chiếu bên ngoài mà agent có thể đọc theo yêu cầu. Điều này đặc biệt quan trọng cho agent thực hiện nhiều lần gọi công cụ mỗi phiên.
Nén lịch sử hội thoại qua tóm tắt. Trích xuất các sự kiện chính từ trao đổi dài thành biểu diễn cô đọng. Mọi framework có lưu trữ theo phiên đều hưởng lợi từ quản lý lịch sử tích cực.
Lấy thông tin liên quan động khi chạy thay vì tải mọi thứ trước. Điều này áp dụng cho kỹ năng, cơ sở kiến thức và cả lịch sử hội thoại. Nghiên cứu cho thấy điều này có thể giảm kích thước prompt lên đến 70%.
Sử dụng sub-agent cho tác vụ cụ thể để ngữ cảnh mỗi agent tập trung. Thay vì cho một agent 20 kỹ năng, tạo đội 5 agent với 4 kỹ năng mỗi agent. Mỗi agent duy trì cửa sổ ngữ cảnh gọn gàng, và đội tổng thể bao phủ đầy đủ bộ khả năng.
Cách các framework AI agent chèn kỹ năng vào ngữ cảnh là một trong những quyết định kiến trúc có tác động lớn nhất trong thiết kế agent—nhưng hiếm khi được thảo luận ở mức chi tiết này.
Lĩnh vực này rõ ràng đang hội tụ về tiết lộ dần dần như mẫu ưa thích cho agent đa mục đích, với Claude Code, LangChain Deep Agents và OpenAI đều độc lập đi đến kiến trúc ba tầng tương tự. Trong khi đó, các mẫu chuyên biệt như truy xuất ngữ nghĩa (AutoGen, Voyager) và chèn biên dịch (DSPy) phục vụ các nhu cầu quan trọng mà tiết lộ dần dần đơn lẻ không giải quyết được.
Đối với những người xây dựng hệ thống agent ngày nay, hiểu biết chính là chèn kỹ năng không phải bài toán một-kích-cỡ-cho-tất-cả. Cách tiếp cận phù hợp phụ thuộc vào vai trò agent, số lượng kỹ năng cần, liệu nó có cần học theo thời gian hay không, và mức chấp nhận giữa chi phí token và độ tin cậy.
Các hệ thống sản xuất mạnh mẽ nhất có lẽ sẽ kết hợp nhiều mẫu—luôn bật cho khả năng cốt lõi, tiết lộ dần dần cho kỹ năng mở rộng, và truy xuất ngữ nghĩa cho kiến thức tích lũy—tạo ra agent vừa hiệu quả vừa chuyên nghiệp.
Yasha là một nhà phát triển phần mềm tài năng, chuyên về Python, Java và học máy. Yasha viết các bài báo kỹ thuật về AI, kỹ thuật prompt và phát triển chatbot.

Thiết kế đội ngũ AI agent với khả năng chèn kỹ năng thông minh và quản lý ngữ cảnh hiệu quả. Không cần viết code.
Làm chủ thành phần AI Agent trong quy trình làm việc FlowHunt. Tìm hiểu cách cấu hình tin nhắn hệ thống, kết nối các công cụ, chọn mô hình và tối ưu hóa hiệu su...
Hướng dẫn toàn diện về các nền tảng xây dựng AI agent tốt nhất năm 2025, gồm FlowHunt.io, OpenAI và Google Cloud. Khám phá đánh giá chi tiết, bảng xếp hạng và s...

So sánh các bot giao dịch mới nhất dựa trên LLM, các mô hình nền tảng, kỹ thuật cải thiện chất lượng và kết quả thực tế. Bao gồm các dự án mã nguồn mở hàng đầu ...
Đồng Ý Cookie
Chúng tôi sử dụng cookie để cải thiện trải nghiệm duyệt web của bạn và phân tích lưu lượng truy cập của mình. See our privacy policy.