Middleware Human-in-the-Loop trong Python: Xây dựng AI Agent An Toàn với Quy Trình Phê Duyệt
Tìm hiểu cách triển khai middleware human-in-the-loop trong Python bằng LangChain để thêm khả năng phê duyệt, chỉnh sửa và từ chối cho AI agent trước khi thực thi công cụ.
Xây dựng AI agent có thể tự động thực thi công cụ và hành động là rất mạnh mẽ, nhưng cũng tiềm ẩn nhiều rủi ro. Điều gì sẽ xảy ra nếu agent quyết định gửi email với thông tin sai, phê duyệt một giao dịch tài chính lớn, hoặc sửa đổi dữ liệu quan trọng trong cơ sở dữ liệu? Nếu không có biện pháp bảo vệ phù hợp, các agent tự động có thể gây ra thiệt hại nghiêm trọng trước khi ai đó nhận ra. Đó là lý do mà middleware human-in-the-loop trở nên thiết yếu. Trong hướng dẫn toàn diện này, chúng ta sẽ khám phá cách triển khai middleware human-in-the-loop trong Python với LangChain, cho phép bạn xây dựng AI agent tạm dừng để con người phê duyệt trước khi thực thi các thao tác nhạy cảm. Bạn sẽ học cách thêm quy trình phê duyệt, triển khai khả năng chỉnh sửa và xử lý từ chối—tất cả vẫn duy trì hiệu quả và trí tuệ của hệ thống tự động.
Hiểu về Vòng Lặp AI Agent và Thực Thi Công Cụ
Trước khi đi sâu vào middleware human-in-the-loop, điều quan trọng là hiểu cách AI agent hoạt động cơ bản. Một AI agent hoạt động thông qua một vòng lặp liên tục lặp lại cho đến khi agent quyết định đã hoàn thành nhiệm vụ. Vòng lặp agent cốt lõi gồm ba thành phần chính: một mô hình ngôn ngữ để suy luận bước tiếp theo, một tập công cụ mà agent có thể sử dụng để hành động, và một hệ thống quản lý trạng thái lưu lại lịch sử hội thoại cùng ngữ cảnh liên quan. Agent bắt đầu bằng việc nhận thông điệp đầu vào từ người dùng, sau đó mô hình ngôn ngữ phân tích đầu vào này kết hợp với các công cụ sẵn có và quyết định gọi công cụ hoặc trả lời cuối cùng. Nếu mô hình quyết định gọi công cụ, công cụ đó sẽ được thực thi và kết quả được thêm vào lịch sử hội thoại. Quy trình này tiếp diễn—suy luận mô hình, chọn công cụ, thực thi công cụ, tích hợp kết quả—cho đến khi mô hình xác định không cần gọi công cụ nữa và trả về câu trả lời cuối cùng cho người dùng.
Mẫu hình đơn giản nhưng mạnh mẽ này đã trở thành nền tảng cho hàng trăm framework AI agent trong vài năm qua. Sự tinh tế của vòng lặp agent nằm ở tính linh hoạt: chỉ cần thay đổi tập công cụ mà agent có, bạn có thể cho phép nó thực hiện những nhiệm vụ hoàn toàn khác biệt. Một agent với công cụ email có thể quản lý liên lạc, agent có công cụ cơ sở dữ liệu có thể truy vấn và cập nhật dữ liệu, agent với công cụ tài chính có thể xử lý giao dịch. Tuy nhiên, sự linh hoạt này cũng mang lại rủi ro. Vì vòng lặp agent hoạt động tự động, không có cơ chế tích hợp nào để tạm dừng và hỏi con người liệu hành động đó có nên thực hiện không. Mô hình có thể quyết định gửi email, thực hiện truy vấn cơ sở dữ liệu, hoặc phê duyệt giao dịch tài chính, và khi con người phát hiện thì hành động đã hoàn thành. Đây là lúc những giới hạn của vòng lặp agent cơ bản trở nên rõ ràng trong môi trường thực tế.
Sẵn sàng phát triển doanh nghiệp của bạn?
Bắt đầu dùng thử miễn phí ngay hôm nay và xem kết quả trong vài ngày.
Vì Sao Sự Giám Sát của Con Người Quan Trọng trong Hệ Thống AI Triển Khai Thực Tế
Khi AI agent trở nên mạnh mẽ hơn và được triển khai trong môi trường kinh doanh thực tế, nhu cầu về sự giám sát của con người ngày càng quan trọng. Mức độ rủi ro của các hành động tự động thay đổi đáng kể tùy thuộc vào ngữ cảnh. Một số lệnh gọi công cụ có rủi ro thấp và có thể thực thi ngay không cần kiểm tra—ví dụ, đọc email hoặc lấy thông tin từ cơ sở dữ liệu. Nhưng các lệnh gọi công cụ khác lại có rủi ro cao và có thể không thể đảo ngược, như gửi thông tin thay mặt người dùng, chuyển tiền, xóa dữ liệu, hoặc cam kết ràng buộc tổ chức. Trong hệ thống thực tế, cái giá của một agent mắc lỗi trong thao tác rủi ro cao có thể rất lớn. Một email viết sai gửi nhầm người nhận có thể ảnh hưởng tới quan hệ kinh doanh. Một ngân sách được phê duyệt sai có thể dẫn đến thiệt hại tài chính. Một thao tác xóa dữ liệu nhầm có thể khiến mất dữ liệu, cần nhiều giờ hoặc ngày để phục hồi.
Bên cạnh rủi ro vận hành trực tiếp, còn có các yếu tố tuân thủ và quy định pháp luật. Nhiều ngành công nghiệp yêu cầu một số quyết định nhất định phải có sự xem xét và phê duyệt của con người. Tài chính yêu cầu giám sát giao dịch vượt ngưỡng. Y tế yêu cầu kiểm tra một số quyết định tự động. Các hãng luật phải đảm bảo thông tin liên lạc được kiểm duyệt trước khi gửi thay mặt khách hàng. Những quy định này không chỉ là thủ tục hành chính—chúng tồn tại vì hậu quả của quyết định hoàn toàn tự động trong những lĩnh vực này có thể rất nghiêm trọng. Ngoài ra, sự giám sát của con người còn cung cấp cơ chế phản hồi giúp cải thiện agent theo thời gian. Khi con người xem xét và phê duyệt hoặc chỉnh sửa hành động đề xuất, phản hồi đó có thể dùng để điều chỉnh prompt, logic chọn công cụ, hoặc huấn luyện lại mô hình nền. Điều này tạo ra một vòng lặp tích cực, nơi agent ngày càng tin cậy hơn và phù hợp với nhu cầu, mức độ chấp nhận rủi ro của tổ chức.
Middleware Human-in-the-Loop là gì?
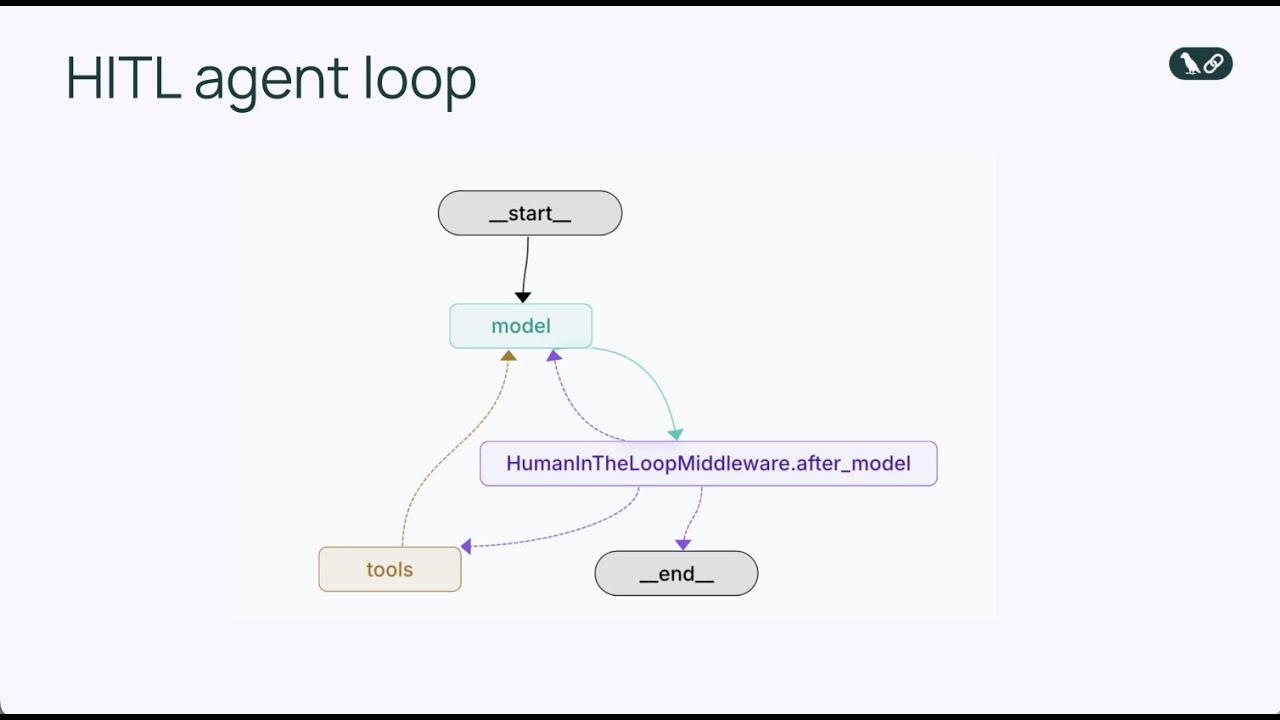
Middleware human-in-the-loop là một thành phần chuyên biệt, chặn vòng lặp agent ở một điểm then chốt: ngay trước khi công cụ được thực thi. Thay vì cho phép agent thực hiện lệnh gọi công cụ ngay, middleware sẽ tạm dừng và trình bày hành động đề xuất cho con người kiểm tra. Con người khi đó có một số lựa chọn phản hồi: phê duyệt để hành động diễn ra như đề xuất, chỉnh sửa (thay đổi tham số như người nhận email hoặc nội dung tin nhắn) rồi mới thực thi, hoặc từ chối hoàn toàn và gửi phản hồi về cho agent giải thích vì sao hành động không phù hợp, yêu cầu xem xét lại. Cơ chế ba lựa chọn này—phê duyệt, chỉnh sửa, từ chối—tạo nên khung linh hoạt đáp ứng đa dạng nhu cầu giám sát của con người.
Middleware hoạt động bằng cách chỉnh sửa vòng lặp agent tiêu chuẩn để thêm điểm ra quyết định mới. Trong vòng lặp cơ bản, trình tự là: mô hình gọi công cụ → công cụ thực thi → kết quả trả về mô hình. Với human-in-the-loop middleware, trình tự sẽ là: mô hình gọi công cụ → middleware chặn lại → con người kiểm tra → con người quyết định (phê duyệt/chỉnh sửa/từ chối) → nếu phê duyệt hoặc đã chỉnh sửa, công cụ thực thi → kết quả trả về mô hình. Việc chèn điểm quyết định này không phá vỡ vòng lặp agent; ngược lại, nó tăng cường bằng một van an toàn. Middleware có thể cấu hình, nghĩa là bạn chỉ định chính xác công cụ nào cần con người kiểm tra, công cụ nào cho phép thực thi tự động. Bạn có thể muốn ngắt trên mọi công cụ gửi email nhưng cho phép truy vấn cơ sở dữ liệu chỉ đọc tự động. Kiểm soát chi tiết này đảm bảo bạn chỉ bổ sung giám sát ở nơi cần thiết mà không tạo nút thắt cho thao tác rủi ro thấp.
Tham gia bản tin của chúng tôi
Nhận các mẹo, xu hướng và ưu đãi mới nhất miễn phí.
Ba Loại Phản Hồi: Phê Duyệt, Chỉnh Sửa và Từ Chối
Khi middleware human-in-the-loop chặn việc thực thi công cụ của agent, người kiểm tra có ba cách phản hồi chính, mỗi cách phục vụ một mục đích khác nhau trong quy trình phê duyệt. Hiểu rõ ba loại phản hồi này là chìa khóa để thiết kế hệ thống human-in-the-loop hiệu quả.
Phê duyệt là phản hồi đơn giản nhất. Khi con người xem xét lệnh gọi công cụ đề xuất và xác định nó phù hợp, nên thực hiện đúng như agent đề xuất, họ đưa ra quyết định phê duyệt. Điều này báo cho middleware rằng công cụ sẽ được thực thi với đúng tham số agent đã chỉ định. Trong trường hợp trợ lý email, phê duyệt nghĩa là bản nháp email ổn và sẽ gửi tới đúng người nhận với tiêu đề, nội dung như dự kiến. Phê duyệt là con đường ít cản trở nhất—cho phép hành động của agent diễn ra mà không chỉnh sửa. Thích hợp khi agent làm tốt công việc và người kiểm tra đồng ý với đề xuất. Quyết định phê duyệt thường được đưa ra nhanh chóng, điều này quan trọng vì không muốn kiểm tra của con người trở thành nút thắt làm chậm quy trình.
Chỉnh sửa là phản hồi tinh tế hơn, thừa nhận cách tiếp cận tổng thể của agent là đúng nhưng cần điều chỉnh chi tiết trước khi thực hiện. Khi con người chọn chỉnh sửa, họ không phủ nhận quyết định hành động của agent; thay vào đó, họ tinh chỉnh cách thực hiện. Trong ví dụ email, chỉnh sửa có thể là thay đổi địa chỉ người nhận, sửa tiêu đề cho chuyên nghiệp hơn, hoặc điều chỉnh nội dung cho phù hợp ngữ cảnh hoặc loại bỏ nội dung nhạy cảm. Đặc điểm của chỉnh sửa là thay đổi tham số công cụ nhưng giữ nguyên lệnh gọi. Agent quyết định gửi email, con người đồng ý nhưng muốn chỉnh sửa nội dung hoặc người nhận. Sau khi chỉnh sửa, công cụ thực thi với tham số mới, kết quả trả về agent. Cách này đặc biệt giá trị vì cho phép agent đề xuất hành động, còn con người tinh chỉnh dựa vào chuyên môn hoặc hiểu biết ngữ cảnh tổ chức mà agent có thể không có.
Từ chối là phản hồi quan trọng nhất vì không chỉ ngăn hành động được thực thi mà còn gửi phản hồi về cho agent, giải thích lý do hành động không phù hợp. Khi con người từ chối lệnh gọi công cụ, họ nói rằng hành động đề xuất không nên thực hiện, đồng thời hướng dẫn agent nên xem xét lại cách tiếp cận. Trong ví dụ email, từ chối có thể xảy ra khi agent đề xuất gửi email phê duyệt ngân sách lớn mà thiếu chi tiết. Con người từ chối và gửi thông điệp giải thích cần có thêm thông tin. Thông điệp từ chối trở thành một phần ngữ cảnh, agent có thể suy luận và đề xuất lại. Agent có thể đề xuất email hỏi thêm thông tin thay vì phê duyệt vội vàng. Từ chối rất quan trọng để tránh agent lặp lại hành động không phù hợp. Phản hồi rõ ràng giúp agent học và cải thiện suy luận.
Triển Khai Middleware Human-in-the-Loop: Ví Dụ Thực Tiễn
Hãy cùng đi qua một ví dụ triển khai middleware human-in-the-loop bằng LangChain và Python. Ví dụ là một trợ lý email—tình huống thực tế thể hiện giá trị của giám sát con người và dễ hình dung. Trợ lý email có thể gửi email thay mặt người dùng, và ta sẽ thêm middleware human-in-the-loop để đảm bảo mọi email cần được kiểm tra trước khi gửi.
Trước tiên, ta cần định nghĩa công cụ email mà agent sử dụng. Công cụ này nhận ba tham số: địa chỉ email người nhận, tiêu đề, và nội dung. Công cụ đơn giản đại diện cho hành động gửi email. Trong thực tế, có thể tích hợp với Gmail hoặc Outlook, nhưng để minh họa, ta giữ đơn giản:
defsend_email(recipient: str, subject: str, body: str) -> str:
"""Gửi email cho người nhận chỉ định."""returnf"Đã gửi email tới {recipient} với tiêu đề '{subject}'"
Tiếp theo, tạo agent sử dụng công cụ này. Sử dụng GPT-4 làm mô hình ngôn ngữ và prompt hệ thống cho agent biết nó là trợ lý email hữu ích. Agent khởi tạo với công cụ email và sẵn sàng phản hồi yêu cầu:
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
tools = [send_email]
agent = create_agent(
model=model,
tools=tools,
system_prompt="Bạn là trợ lý email hữu ích cho Sydney. Bạn có thể gửi email thay mặt người dùng.")
Tới đây, bạn đã có agent cơ bản có thể gửi email. Tuy nhiên, chưa có giám sát—agent có thể gửi email mà không kiểm tra. Giờ hãy thêm middleware human-in-the-loop. Việc này rất đơn giản, chỉ cần hai dòng mã:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
system_prompt="Bạn là trợ lý email hữu ích cho Sydney. Bạn có thể gửi email thay mặt người dùng.",
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={"send_email": True}
)
]
)
Bằng cách thêm HumanInTheLoopMiddleware và chỉ định interrupt_on={"send_email": True}, bạn yêu cầu agent tạm dừng trước khi thực thi bất kỳ lệnh gọi send_email nào và chờ phê duyệt từ con người. Giá trị True nghĩa là mọi lệnh gọi send_email đều ngắt với cấu hình mặc định. Nếu muốn kiểm soát chi tiết hơn, bạn có thể chỉ rõ loại quyết định nào được phép (phê duyệt, chỉnh sửa, từ chối) hoặc mô tả riêng cho lần ngắt.
Thử Nghiệm Middleware với Tình Huống Rủi Ro Thấp
Sau khi middleware đã triển khai, hãy thử với kịch bản gửi email rủi ro thấp. Giả sử người dùng yêu cầu agent trả lời email của đồng nghiệp tên Alice mời cà phê tuần tới. Agent xử lý và quyết định gửi email phản hồi thân thiện. Quy trình sẽ như sau:
Người dùng gửi: “Vui lòng trả lời email của Alice về việc đi uống cà phê tuần tới.”
Agent xử lý và gọi công cụ send_email với các tham số như recipient=“alice@example.com
”, subject=“Cà phê tuần tới?”, body=“Mình rất vui được đi uống cà phê với bạn tuần tới!”
Trước khi email gửi, middleware chặn lệnh gọi và tạo ngắt.
Người kiểm tra xem xét email đề xuất. Nội dung phù hợp—thân thiện, chuyên nghiệp, đúng ý người dùng.
Người kiểm tra phê duyệt hành động.
Middleware cho phép công cụ thực thi, email được gửi.
Quy trình này thể hiện đường phê duyệt cơ bản. Việc kiểm tra thêm lớp an toàn mà không làm chậm quy trình. Với thao tác rủi ro thấp, phê duyệt diễn ra nhanh vì hành động agent hợp lý, không cần chỉnh sửa.
Giờ hãy xét kịch bản quan trọng hơn, nơi chỉnh sửa phát huy tác dụng. Giả sử agent nhận yêu cầu trả lời email từ đối tác startup đề nghị người dùng phê duyệt ngân sách kỹ thuật 1 triệu đô cho quý 1. Đây là quyết định lớn cần xem xét kỹ. Agent có thể đề xuất email kiểu: “Tôi đã xem và phê duyệt đề xuất ngân sách kỹ thuật 1 triệu đô cho quý 1.”
Khi email đề xuất đến người kiểm tra qua middleware, người này nhận ra đây là cam kết tài chính lớn không nên phê duyệt vội. Người kiểm tra không muốn từ chối hoàn toàn, mà muốn chỉnh sửa nội dung thận trọng hơn. Họ đưa ra phản hồi chỉnh sửa, ví dụ: “Cảm ơn đề xuất. Tôi muốn xem kỹ hơn các chi tiết trước khi phê duyệt. Bạn có thể gửi bản phân bổ ngân sách chi tiết không?”
Cách phản hồi chỉnh sửa minh họa bằng mã:
edit_decision = {
"type": "edit",
"edited_action": {
"name": "send_email",
"args": {
"recipient": "partner@startup.com",
"subject": "Đề xuất ngân sách kỹ thuật Q1",
"body": "Cảm ơn đề xuất. Tôi muốn xem kỹ hơn các chi tiết trước khi phê duyệt. Bạn có thể gửi bản phân bổ ngân sách chi tiết không?" }
}
}
Khi middleware nhận phản hồi chỉnh sửa này, nó thực thi công cụ với các tham số đã sửa. Email được gửi với nội dung đã chỉnh sửa, phù hợp hơn với tình huống tài chính quan trọng. Điều này thể hiện sức mạnh của phản hồi chỉnh sửa: cho phép agent soạn thảo, còn con người điều chỉnh cho phù hợp tiêu chuẩn tổ chức.
Thử Nghiệm Middleware với Từ Chối và Phản Hồi
Phản hồi từ chối đặc biệt mạnh vì không chỉ ngăn hành động sai mà còn giúp agent cải thiện suy luận. Xét tiếp ví dụ ngân sách. Nếu agent đề xuất email kiểu: “Tôi đã xem và phê duyệt ngân sách kỹ thuật 1 triệu đô cho quý 1.”
Người kiểm tra nhận thấy quá vội vàng. Cam kết tài chính lớn cần kiểm tra kỹ, trao đổi thêm với bên liên quan, hiểu rõ chi tiết. Người kiểm tra không muốn chỉ chỉnh sửa mà muốn từ chối hoàn toàn và yêu cầu agent xem xét lại. Họ gửi phản hồi từ chối:
reject_decision = {
"type": "reject",
"message": "Tôi không thể phê duyệt ngân sách này nếu chưa có thêm thông tin. Vui lòng soạn email yêu cầu bản phân tích chi tiết đề xuất, gồm phân bổ ngân sách cho từng nhóm kỹ thuật và các kết quả dự kiến."}
Khi middleware nhận phản hồi từ chối, nó không thực thi công cụ. Thay vào đó, nó gửi thông điệp từ chối vào ngữ cảnh hội thoại. Agent thấy hành động bị từ chối và hiểu lý do. Agent có thể suy luận và đề xuất cách tiếp cận khác, ví dụ một email hỏi thêm chi tiết về đề xuất ngân sách. Người kiểm tra lại sẽ duyệt, chỉnh sửa, hoặc tiếp tục từ chối nếu cần.
Quy trình lặp này—đề xuất, kiểm tra, từ chối có phản hồi, đề xuất lại—là điểm mạnh nhất của middleware human-in-the-loop. Nó tạo ra quy trình cộng tác giữa tốc độ, khả năng suy luận của agent và đánh giá, chuyên môn của con người.
Tăng tốc Quy Trình cùng FlowHunt
Trải nghiệm FlowHunt tự động hóa nội dung AI và SEO — từ nghiên cứu, tạo nội dung, xuất bản đến phân tích — tất cả trong một nền tảng.
Dù triển khai cơ bản của middleware human-in-the-loop rất đơn giản, LangChain cung cấp cấu hình nâng cao cho phép bạn kiểm soát chi tiết khi nào và như thế nào việc ngắt xảy ra. Một cấu hình quan trọng là xác định loại quyết định nào được phép với từng công cụ. Ví dụ, bạn có thể cho phép phê duyệt và chỉnh sửa với gửi email, nhưng không cho từ chối. Hoặc cho phép cả ba loại với giao dịch tài chính, chỉ cho phê duyệt với truy vấn chỉ đọc.
Ví dụ cấu hình chi tiết hơn:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
},
"read_database": False, # Tự động phê duyệt, không ngắt"delete_record": {
"allowed_decisions": ["approve", "reject"] # Không cho chỉnh sửa khi xóa }
}
)
]
)
Trong cấu hình này, gửi email sẽ ngắt và cho phép cả ba loại phản hồi. Truy vấn chỉ đọc sẽ thực thi tự động không cần ngắt. Xóa dữ liệu sẽ ngắt nhưng không cho chỉnh sửa—chỉ có thể phê duyệt hoặc từ chối, không thay đổi tham số xóa. Kiểm soát chi tiết này đảm bảo chỉ bổ sung giám sát ở nơi cần thiết, không gây nút thắt cho thao tác rủi ro thấp.
Một tính năng nâng cao nữa là tùy chỉnh mô tả lần ngắt. Mặc định, middleware đưa ra mô tả chung như “Thực thi công cụ cần phê duyệt.” Bạn có thể tùy chỉnh để cung cấp thông tin cụ thể cho ngữ cảnh:
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"],
"description": "Gửi email cần phê duyệt của con người trước khi thực thi" }
}
)
Lưu Ý Triển Khai Quan Trọng: Checkpointer và Quản Lý Trạng Thái
Một khía cạnh quan trọng khi triển khai middleware human-in-the-loop dễ bị bỏ qua là cần có checkpointer. Checkpointer là cơ chế lưu lại trạng thái agent tại điểm bị ngắt, cho phép tiếp tục quy trình sau đó. Điều này rất cần thiết vì việc kiểm tra của con người không diễn ra ngay lập tức—có thể có độ trễ giữa lúc ngắt và lúc con người ra quyết định. Nếu không có checkpointer, trạng thái agent sẽ mất trong thời gian chờ, không thể tiếp tục đúng quy trình.
LangChain cung cấp nhiều lựa chọn checkpointer. Khi phát triển, thử nghiệm, có thể dùng checkpointer trong bộ nhớ:
Với hệ thống sản xuất, nên dùng checkpointer lưu trạng thái vào cơ sở dữ liệu hoặc file, đảm bảo quy trình có thể tiếp tục kể cả khi ứng dụng khởi động lại. Checkpointer lưu lại đầy đủ trạng thái agent ở từng bước, gồm lịch sử hội thoại, các lệnh gọi công cụ và kết quả. Khi con người ra quyết định (phê duyệt, chỉnh sửa, từ chối), middleware dùng checkpointer để lấy lại trạng thái, áp dụng quyết định và tiếp tục vòng lặp agent từ đó.
Ứng Dụng và Kịch Bản Thực Tế
Middleware human-in-the-loop có thể áp dụng cho rất nhiều kịch bản thực tế nơi agent tự động cần hành động nhưng những hành động đó yêu cầu giám sát của con người. Trong ngành tài chính, agent xử lý giao dịch, phê duyệt khoản vay, quản lý đầu tư có thể dùng middleware để đảm bảo quyết định giá trị lớn được con người kiểm tra. Y tế có thể dùng middleware để tuân thủ quy định quyền riêng tư, quy trình lâm sàng. Dịch vụ pháp lý có thể dùng middleware để giữ kiểm soát của luật sư với nội dung và tài liệu nhạy cảm. Dịch vụ khách hàng có thể dùng middleware để đảm bảo hành động như hoàn tiền, cam kết với khách, hoặc leo thang sự vụ phù hợp với chính sách công ty.
Ngoài các ứng dụng ngành, middleware human-in-the-loop hữu ích với bất kỳ kịch bản nào mà chi phí của sai sót agent là đáng kể. Bao gồm hệ thống kiểm duyệt nội dung, nhân sự, chuỗi cung ứng, nơi agent có thể xóa nội dung, xử lý quyết định nhân sự, đặt hàng hay điều chỉnh tồn kho. Điểm chung là hành động agent có hậu quả thực sự, đủ lớn để cần con người kiểm tra trước khi thực thi.
So Sánh với Các Phương Pháp Khác
Cần so sánh middleware human-in-the-loop với các phương pháp khác để bổ sung giám sát con người cho hệ thống agent. Một lựa chọn là cho con người kiểm tra mọi kết quả agent sau khi đã thực hiện, nhưng cách này có nhiều hạn chế. Khi con người kiểm tra, hành động đã xảy ra, việc đảo ngược có thể khó hoặc không thể. Email đã gửi, dữ liệu đã xóa, giao dịch đã hoàn thành. Middleware human-in-the-loop ngăn các hành động không thể đảo ngược này xảy ra ngay từ đầu.
Một lựa chọn khác là cho con người làm thủ công toàn bộ những việc agent có thể làm, nhưng như vậy sẽ mất ý nghĩa dùng agent. Giá trị của agent là xử lý nhanh các công việc thường nhật, giải phóng con người cho quyết định cấp cao. Middleware human-in-the-loop giúp cân bằng: cho agent tự động hóa công việc lặp lại, nhưng dừng lại để con người kiểm tra khi rủi ro cao.
Một lựa chọn nữa là cài đặt các rule hoặc guardrail để ngăn agent thực hiện hành động không phù hợp. Ví dụ, không cho gửi email ra ngoài tổ chức, hoặc không cho xóa dữ liệu mà không xác nhận. Dù guardrail rất giá trị và nên dùng song song với middleware human-in-the-loop, chúng vẫn có giới hạn. Guardrail thường dựa trên luật tĩnh, không lường trước mọi tình huống. Agent có thể qua mọi guardrail nhưng vẫn đề xuất hành động không phù hợp trong ngữ cảnh cụ thể. Đánh giá của con người linh hoạt và nhận biết ngữ cảnh tốt hơn, nên middleware human-in-the-loop rất giá trị.
Thực Tiễn Tốt Nhất Khi Triển Khai Quy Trình Human-in-the-Loop
Khi triển khai middleware human-in-the-loop, một số thực tiễn tốt sẽ giúp hệ thống hiệu quả. Thứ nhất, hãy chọn lọc công cụ cần ngắt. Ngắt mọi lệnh gọi công cụ sẽ gây nút thắt, làm chậm quy trình. Thay vào đó, hãy tập trung vào công cụ đắt đỏ, rủi ro, hoặc hậu quả lớn nếu thực thi sai. Thao tác chỉ đọc thường không cần ngắt. Thao tác ghi dữ liệu hoặc hành động bên ngoài thường nên ngắt.
Thứ hai, cung cấp ngữ cảnh rõ ràng cho người kiểm tra. Khi ngắt xảy ra, người kiểm tra phải hiểu agent định làm gì và lý do. Đảm bảo mô tả ngắt rõ ràng, cung cấp đủ ngữ cảnh. Nếu agent định gửi email, hãy hiển thị đầy đủ nội dung email. Nếu xóa dữ liệu, hãy cho biết xóa bản ghi nào và lý do. Càng nhiều ngữ cảnh, quyết định của con người càng nhanh và chính xác.
Thứ ba, làm cho quy trình phê duyệt thuận tiện nhất có thể. Con người sẽ phê duyệt nhanh hơn nếu quy trình đơn giản, không phải nhập liệu nhiều. Cung cấp nút hoặc lựa chọn rõ ràng cho phê duyệt, chỉnh sửa, từ chối. Nếu cho phép chỉnh sửa, hãy làm cho việc chỉnh sửa tham số dễ dàng, không cần hiểu mã nguồn hay cấu trúc dữ liệu.
Thứ tư, sử dụng phản hồi từ chối một cách chiến lược. Khi từ chối, hãy cung cấp phản hồi rõ vì sao hành động không phù hợp và agent nên làm gì thay thế. Phản hồi này giúp agent học và cải thiện quyết định. Theo thời gian, agent sẽ ngày càng phù hợp với tiêu chuẩn, mức rủi ro tổ chức bạn.
Thứ năm, theo dõi và phân tích mô hình ngắt. Xem công cụ nào bị ngắt nhiều nhất, quyết định nào phổ biến, thời gian phê duyệt trung bình. Dữ liệu này giúp bạn phát hiện nút thắt, điều chỉnh cấu hình ngắt, cải thiện prompt hoặc logic chọn công cụ cho agent.
Tích Hợp Middleware Human-in-the-Loop với FlowHunt
Đối với tổ chức muốn triển khai quy trình human-in-the-loop ở quy mô lớn, FlowHunt cung cấp nền tảng toàn diện tích hợp mượt mà với khả năng middleware của LangChain. FlowHunt cho phép bạn xây dựng, triển khai, quản lý agent AI với quy trình phê duyệt tích hợp, dễ dàng bổ sung giám sát con người vào tự động hóa. Với FlowHunt, bạn cấu hình công cụ cần phê duyệt, tùy biến giao diện phê duyệt, theo dõi toàn bộ quyết định phê duyệt/từ chối cho mục đích kiểm soát và tuân thủ. Nền tảng xử lý phức tạp về quản lý trạng thái, checkpoint, điều phối quy trình, giúp bạn tập trung xây dựng agent hiệu quả và quy định phê duyệt hợp lý. Tích hợp LangChain giúp bạn tận dụng sức mạnh middleware human-in-the-loop với giao diện thân thiện và độ tin cậy cấp doanh nghiệp.
Kết Luận
Middleware human-in-the-loop là cầu nối quan trọng giữa hiệu quả của AI agent tự động và nhu cầu giám sát con người trong hệ thống thực tế. Triển khai quy trình phê duyệt, khả năng chỉnh sửa, cơ chế phản hồi từ chối giúp bạn xây dựng agent vừa mạnh mẽ vừa an toàn. Mô hình ba quyết định—phê duyệt, chỉnh sửa, từ chối—đem lại sự linh hoạt cho các loại kiểm soát, từ thao tác rủi ro thấp có thể phê duyệt nhanh đến quyết định lớn cần xem xét, chỉnh sửa kỹ. Việc triển khai rất đơn giản, chỉ cần thêm vài dòng mã cho agent LangChain hiện có, nhưng tác động tới độ tin cậy, an toàn hệ thống là rất lớn. Khi AI agent ngày càng mạnh và được ứng dụng vào các quy trình doanh nghiệp trọng yếu, middleware human-in-the-loop sẽ trở thành thành phần không thể thiếu của AI có trách nhiệm. Dù bạn xây dựng trợ lý email, hệ thống tài chính, ứng dụng y tế, hay bất cứ lĩnh vực nào mà hành động agent có hậu quả thực, middleware human-in-the-loop là khung giúp bảo đảm phán xét của con người luôn trung tâm của tự động hóa.
Câu hỏi thường gặp
Middleware human-in-the-loop là một thành phần tạm dừng việc thực thi của AI agent trước khi chạy các công cụ nhất định, cho phép con người phê duyệt, chỉnh sửa hoặc từ chối hành động đề xuất. Điều này bổ sung một lớp an toàn cho các thao tác đắt đỏ hoặc rủi ro.
Hãy sử dụng cho các thao tác có rủi ro cao như gửi email, giao dịch tài chính, ghi dữ liệu vào cơ sở dữ liệu, hoặc bất kỳ thao tác nào đòi hỏi kiểm soát tuân thủ hoặc có thể gây hậu quả đáng kể nếu thực hiện sai.
Ba loại phản hồi chính là: Phê duyệt (thực thi công cụ như đề xuất), Chỉnh sửa (thay đổi tham số công cụ trước khi thực thi), và Từ chối (từ chối thực thi và gửi phản hồi về cho mô hình để sửa lại).
Import HumanInTheLoopMiddleware từ langchain.agents.middleware, cấu hình với các công cụ bạn muốn ngắt, và truyền vào hàm tạo agent của bạn. Bạn cũng cần một checkpointer để duy trì trạng thái giữa các lần ngắt.
Arshia là Kỹ sư Quy trình AI tại FlowHunt. Với nền tảng về khoa học máy tính và niềm đam mê AI, anh chuyên tạo ra các quy trình hiệu quả tích hợp công cụ AI vào các nhiệm vụ hàng ngày, nâng cao năng suất và sự sáng tạo.
Arshia Kahani
Kỹ sư Quy trình AI
Tự động hóa Quy Trình AI An Toàn với FlowHunt
Xây dựng agent thông minh với quy trình phê duyệt tích hợp và sự giám sát của con người. FlowHunt giúp bạn dễ dàng triển khai tự động hóa human-in-the-loop cho quy trình doanh nghiệp.
Xây dựng AI Agent mở rộng: Khám phá sâu về Kiến trúc Middleware
Tìm hiểu cách kiến trúc middleware của LangChain 1.0 cách mạng hóa phát triển agent, giúp lập trình viên xây dựng deep agent mạnh mẽ, mở rộng với khả năng lập k...
Cách Sử Dụng Lindy AI: Hướng Dẫn Cho Người Mới Bắt Đầu Xây Dựng Agent Tự Động Đầu Tiên
Tìm hiểu cách xây dựng agent tự động hóa bằng AI đầu tiên với Lindy AI chỉ trong vài phút—không cần biết lập trình. Hướng dẫn thân thiện cho người mới bắt đầu n...
Human-in-the-Loop (HITL) là một phương pháp trong AI và học máy tích hợp chuyên môn của con người vào quá trình huấn luyện, điều chỉnh và ứng dụng hệ thống AI, ...
3 phút đọc
AI
Human-in-the-Loop
+4
Đồng Ý Cookie Chúng tôi sử dụng cookie để cải thiện trải nghiệm duyệt web của bạn và phân tích lưu lượng truy cập của mình. See our privacy policy.