
Hugging Face Transformers
Hugging Face Transformers là một thư viện Python mã nguồn mở hàng đầu giúp dễ dàng triển khai các mô hình Transformer cho các nhiệm vụ học máy trong xử lý ngôn ...
6 phút đọc
AI
Machine Learning
+4
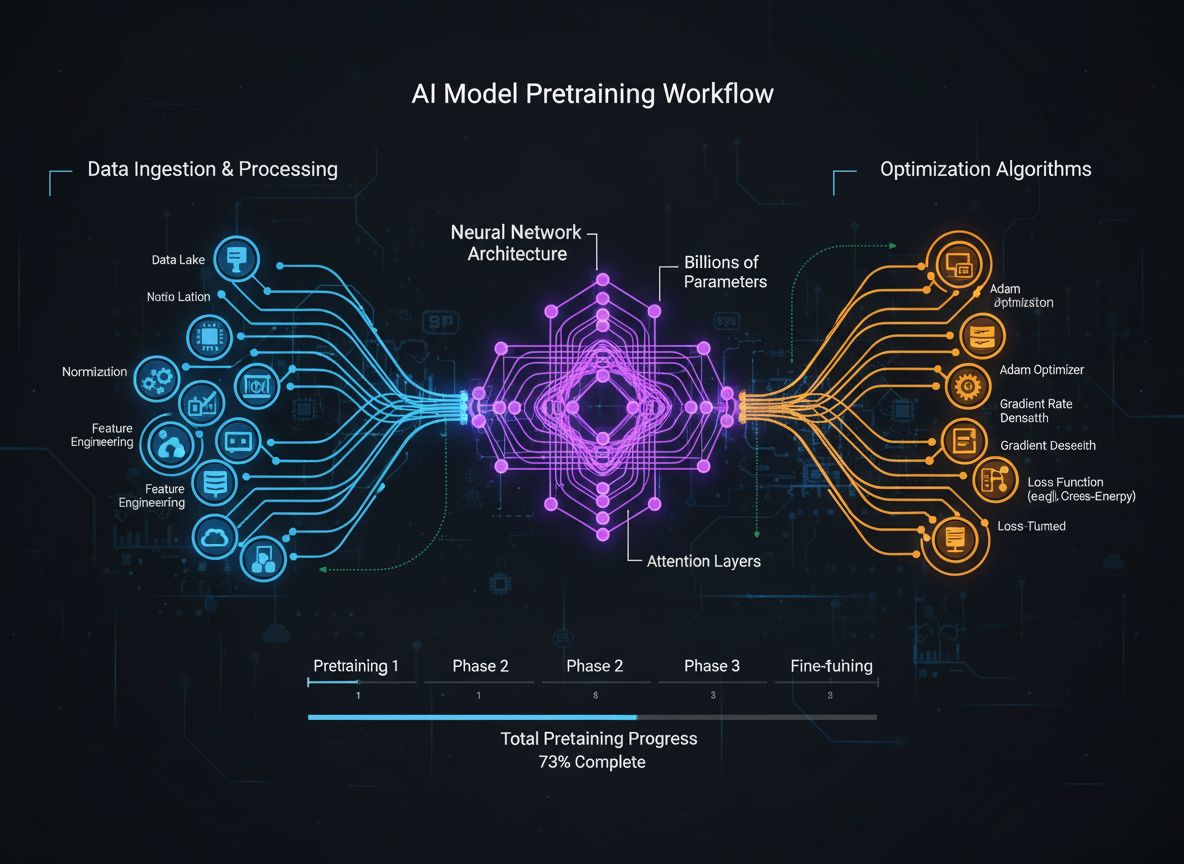
Hướng dẫn toàn diện về các chiến lược tiền huấn luyện mô hình ngôn ngữ hiện đại, kỹ thuật chọn lọc dữ liệu và phương pháp tối ưu hóa mà HuggingFace đã sử dụng để xây dựng các mô hình mã nguồn mở hiệu năng cao, tiết kiệm tài nguyên.
Bức tranh phát triển mô hình ngôn ngữ đã thay đổi căn bản trong vài năm gần đây. Trong khi các công ty công nghệ lớn tiếp tục đẩy giới hạn về quy mô mô hình, cộng đồng mã nguồn mở đã khám phá ra rằng hiệu năng vượt trội không nhất thiết phải đến từ các mô hình hàng nghìn tỷ tham số. Bài hướng dẫn này phân tích sâu các kỹ thuật và chiến lược tiên tiến mà các nhà nghiên cứu HuggingFace sử dụng để xây dựng mô hình ngôn ngữ hiệu quả, hiệu năng cao thông qua phương pháp tiền huấn luyện nghiêm ngặt. Chúng ta sẽ khám phá cách SmolLM 3, FineWeb và FinePDF đại diện cho một khuynh hướng mới—tập trung tối ưu hiệu năng trong giới hạn tài nguyên tính toán thực tế nhưng vẫn đảm bảo tính khoa học và khả năng tái lập. Những hiểu biết ở đây là kết tinh của nhiều tháng nghiên cứu, thử nghiệm, mang lại một khóa học masterclass về cách tiếp cận tiền huấn luyện mô hình trong thời đại mới.

Tiền huấn luyện mô hình ngôn ngữ đã phát triển từ một quy trình khá đơn giản—chỉ cần nạp dữ liệu văn bản thô vào mạng nơ-ron—thành một ngành phức hợp với nhiều mục tiêu tối ưu hóa liên kết. Về cơ bản, tiền huấn luyện là cho mô hình tiếp xúc với lượng lớn dữ liệu văn bản, cho phép nó học các mẫu thống kê về ngôn ngữ qua học tự giám sát. Tuy nhiên, các cách tiếp cận hiện đại nhận ra rằng chỉ tăng dữ liệu và tính toán là chưa đủ. Thay vào đó, các nhà nghiên cứu cần phối hợp cẩn thận nhiều khía cạnh của quá trình huấn luyện—từ chọn lọc và xử lý dữ liệu đến thiết kế kiến trúc và thuật toán tối ưu hóa. Ngành này đã trưởng thành đến mức việc hiểu rõ các tinh chỉnh nhỏ sẽ phân biệt giữa mô hình tối tân và mô hình trung bình. Sự tiến hóa này phản ánh nhận thức sâu sắc rằng hiệu năng mô hình không do một yếu tố riêng lẻ quyết định mà bởi sự phối hợp chặt chẽ của nhiều mục tiêu tối ưu hóa có thể thực hiện song song. Cộng đồng nghiên cứu ngày càng nhận ra rằng “bí kíp thành công” không nằm ở việc mở rộng quy mô một cách mù quáng mà ở các lựa chọn thiết kế thông minh ở mọi tầng của pipeline huấn luyện.
Bắt đầu dùng thử miễn phí ngay hôm nay và xem kết quả trong vài ngày.
Một trong những bài học quan trọng nhất từ các nghiên cứu gần đây là chất lượng và sự đa dạng của dữ liệu huấn luyện quyết định hiệu năng mô hình nhiều hơn là chỉ dựa vào số lượng dữ liệu. Nguyên tắc này, thường được tóm gọn là “rác vào, rác ra”, ngày càng được xác thực qua thực nghiệm và thực tiễn. Khi các mô hình được huấn luyện trên dữ liệu chọn lọc kém, trùng lặp hoặc chất lượng thấp, chúng học các mẫu sai lệch và không tổng quát hóa được cho các tác vụ mới. Ngược lại, tập dữ liệu được chọn lọc kỹ, loại trùng lặp và lọc sạch giúp mô hình học hiệu quả hơn và đạt hiệu năng tốt hơn với ít bước huấn luyện hơn. Ý nghĩa của nhận định này rất lớn: các tổ chức và nhà nghiên cứu nên đầu tư mạnh cho khâu chọn lọc và đảm bảo chất lượng dữ liệu thay vì chỉ gom thêm dữ liệu thô. Quan điểm này dẫn đến sự xuất hiện của các đội nhóm và công cụ chuyên biệt về tạo lập, làm sạch tập dữ liệu. FineWeb, với hơn 18.5 nghìn tỷ token dữ liệu web tiếng Anh sạch và loại trùng lặp, là minh chứng tiêu biểu. Thay vì dùng dữ liệu CommonCrawl thô, nhóm FineWeb triển khai pipeline lọc, loại trùng lặp và đánh giá chất lượng tinh vi để tạo ra tập dữ liệu luôn vượt trội hơn các bộ dữ liệu lớn chưa xử lý. Đây là nhận thức nền tảng trong ngành: con đường dẫn đến mô hình tốt hơn là qua dữ liệu tốt hơn, không đơn thuần là nhiều dữ liệu hơn.
Tiền huấn luyện mô hình hiện đại có thể được hiểu qua năm mục tiêu tối ưu hóa liên kết nhưng hơi độc lập mà các nhà nghiên cứu phải tối ưu cùng lúc. Hiểu về năm trụ cột này sẽ giúp hình dung toàn bộ quá trình huấn luyện và xác định điểm cần cải tiến. Trụ cột đầu tiên là tối đa hóa tính liên quan và chất lượng thông tin thô trong dữ liệu huấn luyện, bao gồm cả chất lượng từng mẫu và sự đa dạng của toàn bộ tập dữ liệu. Mô hình huấn luyện trên dữ liệu chất lượng cao, đa dạng sẽ học được các mẫu tổng quát hơn so với mô hình chỉ học trên dữ liệu hạn hẹp hoặc chất lượng thấp, bất kể các tối ưu khác. Trụ cột thứ hai là thiết kế kiến trúc mô hình, quyết định hiệu quả xử lý thông tin và các giới hạn tài nguyên. Lựa chọn kiến trúc ảnh hưởng đến tốc độ suy luận, tiêu thụ bộ nhớ, yêu cầu bộ nhớ KV cache, và khả năng tương thích phần cứng. Trụ cột thứ ba là tối đa hóa lượng thông tin trích xuất từ dữ liệu ở mỗi bước huấn luyện, bao gồm các kỹ thuật như knowledge distillation—mô hình nhỏ học từ mô hình lớn, và dự đoán đa token—mô hình dự đoán đồng thời nhiều token tương lai. Trụ cột thứ tư là chất lượng gradient và động lực học tối ưu hóa, bao gồm lựa chọn bộ tối ưu, lịch trình learning rate và các kỹ thuật duy trì ổn định huấn luyện. Trụ cột thứ năm là tinh chỉnh siêu tham số và chiến lược mở rộng quy mô, đảm bảo huấn luyện ổn định khi mô hình lớn hơn và tránh các vấn đề như nổ gradient hoặc phân kỳ kích hoạt. Dù năm trụ cột này không hoàn toàn độc lập, việc tư duy riêng rẽ giúp nhận diện điểm cần chú ý và nơi có thể tạo ra cải tiến lớn nhất.
Nhận các mẹo, xu hướng và ưu đãi mới nhất miễn phí.
FineWeb đánh dấu bước ngoặt về tạo lập tập dữ liệu cho tiền huấn luyện mô hình ngôn ngữ. Thay vì chấp nhận đầu ra thô từ các công cụ crawl web như CommonCrawl, nhóm HuggingFace đã xây dựng pipeline toàn diện để làm sạch, lọc và loại trùng lặp dữ liệu web ở quy mô khổng lồ. Kết quả là tập dữ liệu hơn 18,5 nghìn tỷ token văn bản tiếng Anh chất lượng cao, thuộc top lớn nhất cộng đồng mã nguồn mở hiện có. Quá trình tạo lập FineWeb gồm nhiều giai đoạn xử lý, mỗi bước nhằm loại bỏ nội dung kém chất lượng nhưng vẫn giữ lại thông tin giá trị. Đội ngũ sử dụng thuật toán loại trùng lặp tinh vi loại bỏ nội dung lặp lại, bộ lọc chất lượng để loại spam, trang chất lượng kém, và nhận diện ngôn ngữ đảm bảo tập dữ liệu chủ yếu là tiếng Anh. Giá trị của FineWeb không chỉ ở quy mô mà còn ở bằng chứng thực nghiệm—mô hình huấn luyện trên FineWeb luôn đạt kết quả vượt trội các tập dữ liệu thô lớn hơn. Khi trộn với các bộ dữ liệu khác, FineWeb luôn cho hiệu năng cao hơn nhiều tập dữ liệu thô lớn hơn, chứng minh rằng chất lượng thực sự vượt trội hơn số lượng. Các biểu đồ hiệu năng chỉ ra rằng mô hình huấn luyện với FineWeb đạt kết quả tốt hơn ở các benchmark tiêu chuẩn so với các mô hình cùng quy mô huấn luyện từ nguồn khác. Thành công này đã thúc đẩy cộng đồng nghiên cứu đầu tư mạnh vào khâu chọn lọc dữ liệu, nhận ra đây là nơi có thể đạt bước nhảy hiệu năng. FineWeb được chia sẻ miễn phí cho cộng đồng nghiên cứu, dân chủ hóa quyền truy cập dữ liệu huấn luyện chất lượng cao, tạo điều kiện cho tổ chức nhỏ, nhóm học thuật xây dựng mô hình cạnh tranh.
Khi FineWeb tập trung vào dữ liệu web, nhóm HuggingFace nhận ra còn một nguồn dữ liệu văn bản chất lượng cao lớn chưa khai thác: tài liệu PDF. PDF chứa lượng lớn thông tin cấu trúc chất lượng cao—từ bài báo khoa học, tài liệu kỹ thuật, sách, đến báo cáo chuyên ngành. Tuy nhiên, trích xuất văn bản từ PDF là thách thức kỹ thuật và trước đây chưa có nỗ lực hệ thống ở quy mô lớn nào. FinePDF là dự án đầu tiên triển khai pipeline trích xuất, làm sạch và chọn lọc dữ liệu PDF cho tiền huấn luyện mô hình ngôn ngữ. Nhóm phát triển pipeline tinh vi xử lý các thử thách riêng của PDF như bố cục phức tạp, trích xuất chính xác từ tài liệu nhiều cột, xử lý ảnh nhúng và bảng biểu. Một điểm đột phá của FinePDF là bước “refetch from internet”—giải quyết vấn đề PDF lưu trong CommonCrawl thường trích xuất kém hoặc đã cũ. Bằng cách tải lại PDF từ nguồn gốc trên internet, nhóm đảm bảo có phiên bản chất lượng cao nhất. Hiệu năng thực nghiệm rất ấn tượng—khi trộn với các bộ dữ liệu khác, FinePDF cho kết quả cạnh tranh với các baseline mới như NeoTron B2. Bộ dữ liệu này mở ra nguồn dữ liệu huấn luyện chất lượng cao mới, bổ sung cho dữ liệu web và giúp mô hình học từ thông tin đa dạng, có cấu trúc. Công trình này mở ra hướng mới trong xây dựng tập dữ liệu, gợi ý rằng các nguồn dữ liệu chưa khai thác khác cũng có thể mang lại lợi ích tương tự. Pipeline FinePDF đang được tài liệu hóa chi tiết qua blog, tài liệu kỹ thuật để các nhà nghiên cứu khác có thể tiếp nối và áp dụng với nguồn dữ liệu khác.
SmolLM 3 là kết tinh của các kỹ thuật chọn lọc dữ liệu và tối ưu hóa huấn luyện tiên tiến để tạo ra mô hình ngôn ngữ cực kỳ hiệu quả. Với 3 tỷ tham số, SmolLM 3 nhỏ hơn nhiều mô hình cùng thời nhưng đạt hiệu năng cạnh tranh nhờ tối ưu kỹ lưỡng trên cả năm trụ cột huấn luyện. Mô hình hỗ trợ suy luận hai chế độ, đa ngôn ngữ sáu thứ tiếng và hiểu ngữ cảnh dài, rất đa năng dù quy mô khiêm tốn. Quá trình phát triển SmolLM 3 bao gồm lựa chọn kiến trúc cẩn trọng để tối đa hóa hiệu quả, dùng transformer cân bằng giữa hiệu quả tính toán và sức mạnh mô hình, áp dụng grouped query attention giảm tiêu thụ bộ nhớ và độ trễ suy luận. Mô hình được huấn luyện theo ba giai đoạn tăng cường năng lực từng bước trên các lĩnh vực khác nhau, cho phép tối ưu từng khả năng ở từng giai đoạn. Điểm nổi bật ở SmolLM 3 là nó chứng minh cộng đồng mã nguồn mở đã có thể tạo ra mô hình cạnh tranh với nhiều mô hình độc quyền lớn hơn ở nhiều tác vụ. Điều này thách thức giả định “càng lớn càng tốt” và gợi ý ngành đã chạm đến ngưỡng lợi ích của việc mở rộng quy mô thuần túy. Thay vào đó, trọng tâm chuyển sang hiệu quả, khả năng diễn giải và thực tiễn triển khai. SmolLM 3 có thể chạy trên phần cứng phổ thông, thiết bị biên, môi trường hạn chế tài nguyên, giúp AI tiên tiến tiếp cận với nhiều người dùng hơn. Năng lực đa ngôn ngữ và ngữ cảnh dài của mô hình cho thấy hiệu quả không đồng nghĩa phải đánh đổi tính năng quan trọng.
Knowledge distillation là kỹ thuật mạnh mẽ cho phép mô hình nhỏ hưởng lợi từ kiến thức mà mô hình lớn đã học được. Thay vì huấn luyện mô hình nhỏ từ đầu với dữ liệu thô, knowledge distillation huấn luyện mô hình nhỏ bắt chước đầu ra của mô hình lớn, mạnh hơn. Cách tiếp cận này đặc biệt giá trị trong tiền huấn luyện vì nó cho phép mô hình nhỏ học các mẫu mà mô hình lớn đã phát hiện, đẩy nhanh quá trình học và cải thiện hiệu năng cuối cùng. Cơ chế knowledge distillation là huấn luyện mô hình học sinh (mô hình nhỏ) dự đoán phân phối xác suất đầu ra giống mô hình thầy (mô hình lớn), thường bằng cách tối thiểu hóa độ lệch (divergence) giữa hai phân phối, phổ biến là KL divergence. Tham số nhiệt (temperature) điều chỉnh độ “mượt” của phân phối xác suất—nhiệt cao làm phân phối mượt hơn, cung cấp thêm thông tin về độ tự tin tương đối của các dự đoán. Knowledge distillation đặc biệt hiệu quả trong tiền huấn luyện mô hình ngôn ngữ vì cho phép truyền tải kiến thức từ mô hình lớn sang mô hình nhỏ hiệu quả hơn. Điều này đặc biệt giá trị cho các tổ chức muốn triển khai mô hình trên thiết bị biên, môi trường hạn chế mà vẫn tận dụng được năng lực của mô hình lớn. Kỹ thuật này ngày càng tinh vi, với nhiều nghiên cứu về attention transfer (cho học sinh học cả mẫu attention của thầy) và distillation dựa trên feature (so khớp biểu diễn tầng ẩn).
Huấn luyện mô hình ngôn ngữ truyền thống tập trung vào dự đoán token tiếp theo—cho mô hình học dự đoán token kế tiếp dựa trên tất cả các token trước đó. Tuy nhiên, nghiên cứu gần đây chỉ ra: huấn luyện mô hình dự đoán đồng thời nhiều token tương lai có thể cải thiện hiệu năng đáng kể, nhất là cho bài toán lập trình và suy luận phức tạp. Dự đoán đa token buộc mô hình học các phụ thuộc dài hơi hơn và hiểu sâu hơn về các mẫu ẩn trong dữ liệu. Phương pháp này bổ sung nhiều đầu dự đoán (prediction head), mỗi đầu chịu trách nhiệm dự đoán một token ở vị trí xa hơn. Trong quá trình huấn luyện, mô hình nhận tín hiệu mất mát (loss) đồng thời từ tất cả các đầu, khuyến khích học biểu diễn hữu ích cho nhiều bước dự đoán tương lai. Kỹ thuật này khó hơn dự đoán token tiếp theo đơn thuần nhưng cho biểu diễn tốt hơn. Lợi ích của dự đoán đa token không chỉ ở hiệu năng trên mục tiêu huấn luyện mà còn nâng cao khả năng tổng quát hóa, hiệu suất trên các tác vụ downstream và khả năng suy luận. Đặc biệt hiệu quả trong sinh mã (code generation), nơi hiểu được phụ thuộc dài là điều kiện để sinh ra mã đúng cú pháp, đúng nghĩa. Các nghiên cứu cho thấy dự đoán đa token có thể cải thiện 5-15% hiệu năng trên nhiều benchmark khác nhau, là một trong những kỹ thuật huấn luyện có tác động lớn nhất vài năm gần đây. Phương pháp này dễ triển khai nhưng cần tinh chỉnh số prediction head và trọng số loss hợp lý.
Trong nhiều năm, AdamW là bộ tối ưu mặc định cho huấn luyện mô hình ngôn ngữ lớn. AdamW kết hợp cập nhật gradient động lượng với weight decay, đảm bảo huấn luyện ổn định và hội tụ tốt. Tuy nhiên, nghiên cứu mới chỉ ra rằng AdamW không tối ưu cho mọi kịch bản, đặc biệt khi mở rộng quy mô mô hình rất lớn. Các bộ tối ưu mới như Muon, King K2 thử nghiệm các hướng tiếp cận khác mang lại động lực học tốt hơn và hiệu năng vượt trội. Ý tưởng chính của các bộ tối ưu này là tận dụng ma trận Hessian (diễn tả hình dạng bề mặt hàm mất mát) tốt hơn qua các kỹ thuật như Newton-Schulz. Bằng cách xấp xỉ tốt hơn Hessian, các bộ tối ưu này cho cập nhật gradient nhiều thông tin hơn, giúp hội tụ nhanh và hiệu năng cuối tốt hơn. Muon chẳng hạn, dùng kỹ thuật Newton-Schulz để trực giao hóa ma trận gradient, giúp học trải rộng hơn thay vì chỉ đi theo quỹ đạo tối ưu truyền thống của AdamW. King K2 lại theo dõi các chỉ số như log lớn nhất trên mỗi đầu (head) để điều chỉnh learning rate, gradient clipping thích ứng. Ý nghĩa của đổi mới bộ tối ưu rất lớn. Nhiều người vẫn dùng AdamW với siêu tham số tối ưu cho mô hình nhỏ, kể cả khi huấn luyện mô hình lớn hơn hàng trăm lần. Điều này cho thấy chỉ cần cập nhật lựa chọn bộ tối ưu, siêu tham số cho mô hình lớn cũng có thể tăng hiệu năng đáng kể. Cộng đồng nghiên cứu ngày càng nhận ra rằng bộ tối ưu vẫn chưa phải là bài toán đã giải quyết xong và đổi mới liên tục ở lĩnh vực này sẽ tạo ra cải tiến lớn về hiệu quả huấn luyện và hiệu năng cuối.
Duy trì chất lượng gradient cao trong suốt quá trình huấn luyện là điều kiện tiên quyết để đạt hiệu năng tốt. Khi mô hình mở rộng đến hàng tỷ, hàng nghìn tỷ tham số, huấn luyện trở nên bất ổn hơn, nguy cơ nổ hoặc mất gradient tăng cao. Khắc phục vấn đề này đòi hỏi chú ý đến chất lượng gradient và triển khai các kỹ thuật giữ ổn định từ đầu đến cuối. Một cách cải thiện gradient là dùng gradient clipping—giới hạn gradient không vượt quá ngưỡng—tránh làm huấn luyện bất ổn. Tuy nhiên, clipping đơn giản có thể làm mất thông tin quan trọng. Các phương pháp tinh vi hơn sẽ chuẩn hóa gradient sao cho giữ được thông tin mà vẫn tránh bất ổn. Một yếu tố quan trọng khác là lựa chọn hàm kích hoạt và kỹ thuật chuẩn hóa lớp (layer normalization). Mỗi hàm kích hoạt có đặc điểm riêng về luồng gradient, lựa chọn đúng sẽ ảnh hưởng lớn đến ổn định huấn luyện. Layer normalization, chuẩn hóa kích hoạt trên chiều đặc trưng, trở thành tiêu chuẩn trong transformer vì cho luồng gradient tốt hơn batch normalization. Lịch trình learning rate cũng quyết định chất lượng gradient. Learning rate quá cao có thể gây nổ gradient, quá thấp thì hội tụ chậm hoặc mắc kẹt ở cực tiểu cục bộ. Huấn luyện hiện đại thường dùng lịch trình gồm pha warm-up (tăng dần learning rate), cho phép mô hình “ổn định” trong vùng tham số tốt, sau đó giảm dần learning rate khi huấn luyện tiến triển. Hiểu và tối ưu hóa các yếu tố này rất quan trọng để huấn luyện thành công mô hình lớn, và đây là lĩnh vực vẫn còn nhiều nghiên cứu.
Độ phức tạp của tiền huấn luyện mô hình hiện đại—với nhiều mục tiêu tối ưu hóa, pipeline dữ liệu tinh vi và tinh chỉnh siêu tham số cẩn thận—tạo ra thách thức lớn cho các nhóm triển khai thực tế. FlowHunt giải quyết vấn đề này bằng nền tảng tự động hóa, điều phối các quy trình huấn luyện mô hình phức tạp. Thay vì phải tự tay xử lý dữ liệu, huấn luyện mô hình, đánh giá thủ công, các nhóm có thể dùng FlowHunt định nghĩa workflow tự động xử lý, giảm lỗi và tăng khả năng tái lập. Khả năng tự động hóa của FlowHunt đặc biệt giá trị ở các bước chọn lọc, xử lý dữ liệu—yếu tố quyết định hiệu năng mô hình. Nền tảng có thể tự động hóa các pipeline tinh vi như của FineWeb, FinePDF: loại trùng lặp, lọc chất lượng, chuyển đổi định dạng… giúp các nhóm tập trung vào quyết định chiến lược về loại dữ liệu và cách xử lý, thay vì sa lầy vào chi tiết kỹ thuật. Ngoài ra, FlowHunt giúp quản lý tinh chỉnh siêu tham số, thử nghiệm cần thiết để tối ưu hóa huấn luyện. Bằng cách tự động hóa việc chạy nhiều thí nghiệm khác nhau và thu thập kết quả, FlowHunt giúp các nhóm khám phá không gian tham số nhanh hơn, tìm cấu hình tối ưu hiệu quả hơn. Nền tảng còn cung cấp công cụ theo dõi tiến trình huấn luyện, phát hiện các sự cố như nổ gradient, phân kỳ và tự động điều chỉnh thông số để duy trì ổn định. Đối với các tổ chức xây dựng hoặc tinh chỉnh mô hình ngôn ngữ, FlowHunt có thể giảm đáng kể thời gian, công sức mà vẫn nâng cao chất lượng kết quả.
Một trong những thách thức lớn nhất khi huấn luyện mô hình là làm sao mở rộng từ mô hình nhỏ lên lớn mà vẫn duy trì ổn định và hiệu năng. Quan hệ giữa kích cỡ mô hình và siêu tham số tối ưu không tuyến tính—siêu tham số phù hợp cho mô hình nhỏ thường phải điều chỉnh lại cho mô hình lớn hơn. Điều này càng đúng với learning rate, thường phải giảm khi mô hình to ra. Hiểu về các định luật mở rộng (scaling law) cực kỳ quan trọng để dự đoán hiệu năng mô hình ở các quy mô khác nhau và quyết định phân bổ tài nguyên. Nghiên cứu cho thấy hiệu năng mô hình tuân theo các định luật dạng hàm mũ—hiệu năng cải thiện theo quy mô mô hình, tập dữ liệu, và ngân sách tính toán. Các định luật này giúp dự đoán mức cải thiện khi tăng kích cỡ mô hình hay tập dữ liệu, từ đó đầu tư hợp lý. Tuy nhiên, scaling law không phổ quát—chúng phụ thuộc vào kiến trúc, quy trình huấn luyện, tập dữ liệu cụ thể. Các nhóm cần tự thực hiện thử nghiệm mở rộng để hiểu cách setup cụ thể của mình mở rộng ra sao. Quá trình mở rộng cũng đòi hỏi chú ý kỹ đến ổn định huấn luyện. Mô hình càng lớn càng dễ gặp bất ổn như nổ gradient, phân kỳ… Khắc phục bằng kỹ thuật gradient clipping, lịch trình learning rate cẩn thận, hoặc thay đổi kiến trúc/bộ tối ưu. Cộng đồng nghiên cứu ngày càng nhận ra rằng mở rộng không chỉ là tăng kích cỡ mô hình mà là quản lý tinh vi quá trình huấn luyện để mô hình lớn vẫn huấn luyện hiệu quả.
Học đặc trưng (feature learning) là quá trình mô hình học trích xuất các đặc trưng hữu ích từ dữ liệu thô trong huấn luyện. Trong tiền huấn luyện mô hình ngôn ngữ, đây là quá trình mô hình học biểu diễn các khái niệm ngôn ngữ, quan hệ ngữ nghĩa, mẫu cú pháp trong biểu diễn nội tại. Tối đa hóa học đặc trưng—nghĩa là đảm bảo mô hình khai thác tối đa thông tin hữu ích từ dữ liệu ở mỗi bước—là một trong các mục tiêu then chốt của huấn luyện hiện đại. Một cách tiếp cận là xem xét mức độ thay đổi của biểu diễn mô hình khi cập nhật gradient: nếu mô hình học hiệu quả, mỗi cập nhật sẽ tạo ra thay đổi ý nghĩa giúp dự đoán tốt hơn. Nếu không, cập nhật chỉ thay đổi nhỏ hoặc không cải thiện hiệu năng. Các kỹ thuật tăng cường học đặc trưng gồm khởi tạo trọng số hợp lý (giúp mô hình học nhanh đặc trưng hữu ích sớm), dùng lịch trình learning rate phù hợp—học nhanh ban đầu khi học đặc trưng cơ bản, chậm dần khi hoàn thiện các mẫu tinh tế hơn. Khái niệm học đặc trưng liên quan chặt chẽ tới “feature collapse”—khi mô hình bỏ qua một số đặc trưng hoặc chiều đầu vào. Điều này xảy ra khi mô hình tìm được lối tắt đạt hiệu năng mà không học đủ đặc trưng cần thiết. Kỹ thuật regularization, thiết kế hàm mất mát cẩn thận giúp tránh hiện tượng này và đảm bảo mô hình học đa dạng đặc trưng hữu ích.
{{ cta-dark-panel heading=“Tăng tốc quy trình làm việc với FlowHunt” description=“Trải nghiệm FlowHunt tự động hóa mọi quy trình AI và SEO — từ nghiên cứu, tạo nội dung đến xuất bản và phân tích — tất cả trong một nền tảng.” ctaPrimaryText=“Đặt Lịch Demo” ctaPrimaryURL=“https://calendly.com/liveagentsession/flowhunt-chatbot-demo" ctaSecondaryText=“Dùng thử FlowHunt miễn phí” ctaSecondaryURL=“https://app.flowhunt.io/sign-in" gradientStartColor="#123456” gradientEndColor="#654321” gradientId=“827591b1-ce8c-4110-b064-7cb85a0b1217” }}
Trong nhiều năm, quan điểm chủ đạo của nghiên cứu AI là mô hình càng lớn càng tốt. Điều này dẫn tới cuộc đua xây dựng các mô hình ngày càng to, các công ty cạnh tranh thông báo mô hình nhiều tham số hơn. Tuy nhiên, các tiến bộ gần đây cho thấy quan điểm này đang thay đổi. Thành công của SmolLM 3 và các mô hình hiệu quả khác chứng minh hiệu năng vượt trội có thể đạt được với mô hình nhỏ hơn nhiều lần. Sự thay đổi này phản ánh nhận thức sâu sắc rằng hiệu năng mô hình do nhiều yếu tố ngoài số lượng tham số quyết định. Một mô hình 3 tỷ tham số huấn luyện với dữ liệu chất lượng cao, tối ưu kỹ thuật hiện đại có thể vượt một mô hình lớn hơn nhiều huấn luyện từ dữ liệu kém chất lượng, tối ưu sơ sài. Nhận thức này có ý nghĩa lớn với ngành. Nó cho thấy nghiên cứu tác động mạnh nhất không phải ở việc xây mô hình to hơn mà là cải thiện chất lượng dữ liệu, phát triển kỹ thuật huấn luyện tốt hơn, kiến trúc hiệu quả hơn. Đồng thời, AI trở nên dân chủ hóa, cho phép tổ chức nhỏ, nhóm học thuật xây mô hình cạnh tranh mà không cần nguồn lực tính toán khổng lồ cho mô hình hàng nghìn tỷ tham số. Dịch chuyển khỏi quy mô thuần túy còn có ý nghĩa thực tiễn khi triển khai: mô hình nhỏ chạy được trên thiết bị biên, môi trường hạn chế, độ trễ và tiêu thụ điện thấp. Điều này giúp AI tiên tiến tiếp cận với đa dạng ứng dụng, người dùng hơn. Cộng đồng nghiên cứu ngày càng nhận thức rằng tương lai phát triển AI sẽ gồm nhiều mô hình ở các quy mô khác nhau, tối ưu cho từng bài toán thay vì chỉ tập trung xây mô hình to nhất có thể.
Tinh chỉnh siêu tham số là quá trình chọn giá trị cho các tham số kiểm soát quá trình huấn luyện—như learning rate, batch size, weight decay. Các tham số này ảnh hưởng lớn đến hiệu năng mô hình, và tìm giá trị tối ưu là điều kiện cần để đạt kết quả tốt. Tuy nhiên, tinh chỉnh siêu tham số thường bị xem như nghệ thuật, dựa vào trực giác, thử-sai thay vì các phương pháp hệ thống. Cách tiếp cận hiện đại dùng các kỹ thuật hệ thống hơn như Bayesian optimization để khám phá không gian siêu tham số, nhận diện vùng tiềm năng và tập trung tìm kiếm. Grid search, random search là các cách đơn giản hơn cũng hiệu quả khi kết hợp tính toán song song. Một phát hiện quan trọng là siêu tham số tối ưu phụ thuộc vào mô hình, tập dữ liệu, setting huấn luyện cụ thể. Nghĩa là siêu tham số tối ưu cho mô hình này có thể không phù hợp với mô hình khác, dù giống nhau về quy mô, kiến trúc. Điều này dẫn đến thực tiễn quét siêu tham số cho mỗi mô hình/tập dữ liệu mới, dù tốn kém nhưng thường là cần thiết để đạt hiệu năng tối ưu. Hiểu quan hệ giữa siêu tham số và hiệu năng cũng rất quan trọng khi debug vấn đề huấn luyện. Nếu huấn luyện không ổn định hoặc hội tụ chậm, nguyên nhân có thể do siêu tham số chưa chuẩn hơn là vấn đề dữ liệu hay mô hình. Khám phá hệ thống không gian siêu tham số thường giúp phát hiện và khắc phục các vấn đề này.
Các nhận thức từ nghiên cứu tiền huấn luyện mô hình hiện đại có ý nghĩa thực tiễn lớn cho các tổ chức tự xây hoặc tinh chỉnh mô hình ngôn ngữ. Trước hết, cần đầu tư mạnh vào chọn lọc, đảm bảo chất lượng dữ liệu. Bằng chứng cho thấy dữ liệu chất lượng cao giá trị hơn nhiều so với số lượng lớn nhưng chất lượng thấp. Điều này đòi hỏi xây dựng pipeline dữ liệu tinh vi—loại trùng lặp, lọc chất lượng, chuẩn hóa định dạng. Thứ hai, doanh nghiệp cần xác định rõ mục tiêu tối ưu hóa và đảm bảo tối ưu đúng chỉ số quan trọng. Mỗi ứng dụng có thể cần cân bằng khác nhau giữa kích cỡ, tốc độ suy luận và độ chính xác. Định nghĩa rõ trade-off này từ đầu giúp ra quyết định kiến trúc, quy trình huấn luyện hợp lý. Thứ ba, luôn cập nhật các tiến bộ mới về kỹ thuật huấn luyện, bộ tối ưu. Lĩnh vực thay đổi nhanh, kỹ thuật tối tân năm ngoái có thể đã bị thay thế. Thường xuyên đọc nghiên cứu mới, thử nghiệm kỹ thuật mới giúp doanh nghiệp cạnh tranh hơn. Thứ tư, đầu tư vào công cụ, hạ tầng hỗ trợ triển khai quy trình huấn luyện hiện đại—có thể là nền tảng như FlowHunt để tự động hóa xử lý dữ liệu, huấn luyện, hoặc hạ tầng custom giúp thử nghiệm, tinh chỉnh siêu tham số hiệu quả. Cuối cùng, nhận thức rằng phát triển mô hình không chỉ là huấn luyện mà còn là đánh giá, phân tích lỗi, cải tiến lặp lại có hệ thống—bao gồm kiểm tra định kỳ trên benchmark đa dạng, tìm hiểu ca thất bại, cải tiến liên tục dựa trên kết quả.
Lĩnh vực tiền huấn luyện mô hình đang tiến hóa rất nhanh, liên tục xuất hiện kỹ thuật, nhận thức mới. Một số xu hướng chỉ ra hướng đi tương lai: Thứ nhất, tiếp tục tập trung vào chất lượng, chọn lọc dữ liệu; sẽ có nhiều pipeline xử lý dữ liệu tinh vi và nghiên cứu về đặc điểm của dữ liệu “tốt” cho huấn luyện. Thứ hai, đổi mới về thiết kế bộ tối ưu, động lực học huấn luyện vẫn tiếp diễn. Thành công của Muon, King K2 cho thấy còn rất nhiều dư địa nâng cao cách tối ưu hóa huấn luyện mô hình. Thứ ba, khả năng sẽ có nhiều nghiên cứu về hiệu quả, khả năng triển khai thực tiễn—làm mô hình nhỏ hơn, nhanh hơn, tiết kiệm hơn, bao gồm nén mô hình, lượng tử hóa, distillation. Thứ tư, nghiên cứu về khả năng diễn giải, giải thích mô hình sẽ tăng lên—mô hình càng mạnh, càng cần hiểu cách nó hoạt động, lý do đưa ra quyết định. Cuối cùng, công cụ, kỹ thuật dân chủ hóa phát triển mô hình sẽ ngày càng phổ biến, giúp
SmolLM 3 là mô hình 3 tỷ tham số được thiết kế tối ưu hiệu suất trong khi vẫn duy trì khả năng xử lý đa ngôn ngữ và suy luận dải ngữ cảnh dài. Không giống các mô hình lớn hơn, SmolLM 3 tập trung vào hiệu quả tối ưu trong giới hạn tài nguyên tính toán, lý tưởng cho triển khai trên thiết bị biên và môi trường hạn chế tài nguyên.
Nguyên tắc 'rác vào, rác ra' là nền tảng của học máy. Dữ liệu đa dạng, chất lượng cao ảnh hưởng trực tiếp đến hiệu năng mô hình hơn là chỉ tăng số lượng dữ liệu. FineWeb và FinePDF chứng minh rằng chọn lọc, loại trùng lặp và lọc dữ liệu kỹ lưỡng sẽ mang lại kết quả vượt trội so với các tập dữ liệu thô chưa xử lý.
Knowledge distillation là kỹ thuật để mô hình nhỏ học từ mô hình lớn, mạnh mẽ hơn. Trong giai đoạn tiền huấn luyện, cách tiếp cận này cho phép mô hình nhỏ khai thác tối đa thông tin từ dữ liệu huấn luyện bằng cách học các mẫu đã được mô hình lớn phát hiện, giúp đạt hiệu năng tốt hơn với ít tham số hơn.
Dự đoán đa token huấn luyện mô hình dự đoán đồng thời nhiều token tiếp theo thay vì chỉ một token. Phương pháp này đặc biệt hiệu quả cho các tác vụ lập trình và giúp mô hình hiểu các phụ thuộc dài hơi, từ đó nâng cao hiệu suất ở các bài toán suy luận phức tạp.
Các bộ tối ưu hiện đại như Muon vượt xa AdamW truyền thống nhờ áp dụng các kỹ thuật như Newton-Schulz để xấp xỉ tốt hơn ma trận Hessian. Nhờ đó, huấn luyện ổn định hơn, gradient chất lượng tốt hơn và động lực học được cải thiện, đặc biệt khi mở rộng mô hình lên số lượng tham số lớn.
Arshia là Kỹ sư Quy trình AI tại FlowHunt. Với nền tảng về khoa học máy tính và niềm đam mê AI, anh chuyên tạo ra các quy trình hiệu quả tích hợp công cụ AI vào các nhiệm vụ hàng ngày, nâng cao năng suất và sự sáng tạo.

FlowHunt giúp các nhóm tối ưu hóa quy trình tiền huấn luyện mô hình, xử lý dữ liệu và tối ưu hóa pipeline với tự động hóa thông minh.
Hugging Face Transformers là một thư viện Python mã nguồn mở hàng đầu giúp dễ dàng triển khai các mô hình Transformer cho các nhiệm vụ học máy trong xử lý ngôn ...
Phát hiện ngôn ngữ trong các mô hình ngôn ngữ lớn (LLMs) là quá trình giúp các mô hình này nhận diện ngôn ngữ của văn bản đầu vào, cho phép xử lý chính xác đối ...

Khám phá cách Jamba 3B của AI21 kết hợp attention transformer với mô hình state space để đạt được hiệu suất chưa từng có và khả năng xử lý ngữ cảnh dài trên thi...
Đồng Ý Cookie
Chúng tôi sử dụng cookie để cải thiện trải nghiệm duyệt web của bạn và phân tích lưu lượng truy cập của mình. See our privacy policy.