Truy xuất Thông tin
Truy xuất Thông tin tận dụng AI, Xử lý Ngôn ngữ Tự nhiên (NLP) và học máy để truy xuất dữ liệu đáp ứng yêu cầu của người dùng một cách hiệu quả và chính xác. Là...
10 phút đọc
Information Retrieval
AI
+4

Tìm kiếm AI tận dụng học máy và vector embedding để hiểu mục đích và ngữ cảnh truy vấn, mang lại kết quả rất phù hợp vượt xa việc khớp từ khóa chính xác.
Tìm kiếm AI sử dụng học máy để hiểu ngữ cảnh và ý định của các truy vấn tìm kiếm, chuyển chúng thành các vector số hóa nhằm mang lại kết quả chính xác hơn. Khác với tìm kiếm từ khóa truyền thống, Tìm kiếm AI diễn giải các mối quan hệ ngữ nghĩa, giúp hiệu quả với đa dạng kiểu dữ liệu và ngôn ngữ.
Tìm kiếm AI, còn gọi là tìm kiếm ngữ nghĩa hoặc vector, là một phương pháp tìm kiếm tận dụng các mô hình học máy để hiểu ý định và ý nghĩa ngữ cảnh đằng sau truy vấn. Khác với tìm kiếm dựa trên từ khóa truyền thống, tìm kiếm AI chuyển đổi dữ liệu và truy vấn thành các biểu diễn số gọi là vector hoặc embedding. Điều này cho phép công cụ tìm kiếm hiểu các mối quan hệ ngữ nghĩa giữa các dữ liệu khác nhau, cung cấp kết quả liên quan và chính xác hơn ngay cả khi không có từ khóa trùng khớp.
Tìm kiếm AI đại diện cho một bước tiến lớn trong công nghệ tìm kiếm. Công cụ tìm kiếm truyền thống phụ thuộc chủ yếu vào việc khớp từ khóa, nơi sự xuất hiện của các thuật ngữ cụ thể trong cả truy vấn và tài liệu quyết định mức độ liên quan. Tuy nhiên, Tìm kiếm AI sử dụng các mô hình học máy để nắm bắt ngữ cảnh và ý nghĩa ẩn của truy vấn và dữ liệu.
Bằng cách chuyển đổi văn bản, hình ảnh, âm thanh và các dữ liệu phi cấu trúc khác thành các vector nhiều chiều, Tìm kiếm AI có thể đo lường độ tương đồng giữa các nội dung khác nhau. Phương pháp này cho phép công cụ tìm kiếm mang lại kết quả phù hợp với ngữ cảnh, ngay cả khi chúng không chứa chính xác từ khóa trong truy vấn.
Thành phần chính:
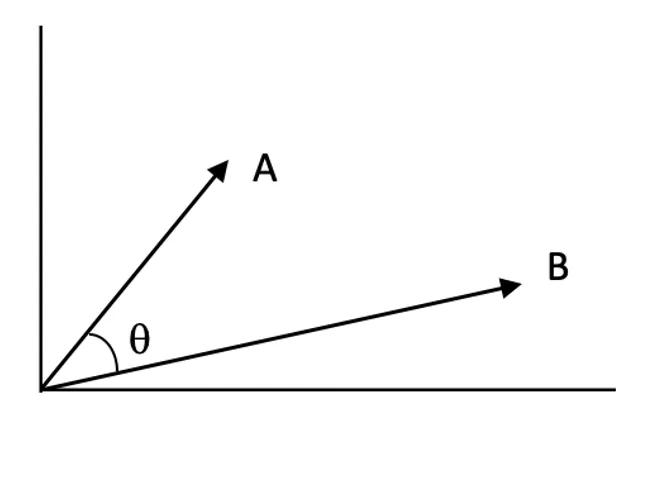
Trọng tâm của Tìm kiếm AI là khái niệm vector embedding. Vector embedding là các biểu diễn số của dữ liệu, ghi lại ý nghĩa ngữ nghĩa của văn bản, hình ảnh hoặc các loại dữ liệu khác. Những embedding này đặt các dữ liệu tương đồng gần nhau trong không gian vector nhiều chiều.
Cách hoạt động:
Ví dụ:
Công cụ tìm kiếm dựa trên từ khóa truyền thống hoạt động bằng cách khớp các thuật ngữ trong truy vấn với các tài liệu chứa các thuật ngữ đó. Chúng dựa vào các kỹ thuật như inverted index và tần suất từ để xếp hạng kết quả.
Hạn chế của tìm kiếm dựa trên từ khóa:
Lợi thế của Tìm kiếm AI:
| Khía cạnh | Tìm kiếm dựa trên từ khóa | Tìm kiếm AI (Ngữ nghĩa/Vector) |
|---|---|---|
| Khớp | Khớp từ khóa chính xác | Tương đồng ngữ nghĩa |
| Nhận biết ngữ cảnh | Giới hạn | Cao |
| Xử lý từ đồng nghĩa | Cần danh sách từ đồng nghĩa thủ công | Tự động qua embedding |
| Sai chính tả | Có thể thất bại nếu không có tìm kiếm mờ | Khoan dung hơn nhờ ngữ cảnh |
| Hiểu ý định | Tối thiểu | Đáng kể |
Tìm kiếm ngữ nghĩa là ứng dụng lõi của Tìm kiếm AI tập trung vào việc hiểu mục đích của người dùng và ý nghĩa ngữ cảnh của truy vấn.
Quy trình:
Kỹ thuật chính:
Điểm tương đồng:
Điểm tương đồng định lượng mức độ liên quan giữa hai vector trong không gian vector. Điểm càng cao cho thấy mức độ liên quan giữa truy vấn và tài liệu càng lớn.
Thuật toán Approximate Nearest Neighbor (ANN):
Tìm hàng xóm gần nhất chính xác trong không gian nhiều chiều rất tốn tài nguyên tính toán. Thuật toán ANN cung cấp giải pháp xấp xỉ hiệu quả.
Tìm kiếm AI mở ra nhiều ứng dụng đa ngành nhờ khả năng hiểu và diễn giải dữ liệu vượt xa việc khớp từ khóa đơn giản.
Mô tả: Tìm kiếm ngữ nghĩa nâng cao trải nghiệm người dùng bằng cách hiểu ý định truy vấn và cung cấp kết quả phù hợp theo ngữ cảnh.
Ví dụ:
Mô tả: Bằng cách hiểu sở thích và hành vi, Tìm kiếm AI mang lại gợi ý nội dung hoặc sản phẩm cá nhân hóa.
Ví dụ:
Mô tả: Tìm kiếm AI cho phép hệ thống hiểu và trả lời truy vấn người dùng với thông tin chính xác được trích xuất từ tài liệu.
Ví dụ:
Mô tả: Tìm kiếm AI có thể lập chỉ mục và tìm kiếm qua dữ liệu phi cấu trúc như hình ảnh, âm thanh, video bằng cách chuyển đổi thành embedding.
Ví dụ:
Tích hợp Tìm kiếm AI vào hệ thống tự động hóa AI và chatbot giúp nâng cao năng lực vượt trội.
Lợi ích:
Các bước triển khai:
Ví dụ trường hợp sử dụng:
Dù Tìm kiếm AI mang lại nhiều lợi ích, vẫn tồn tại các thách thức:
Chiến lược khắc phục:
Tìm kiếm ngữ nghĩa và vector trong AI đã nổi lên như lựa chọn mạnh mẽ thay thế cho tìm kiếm từ khóa truyền thống và fuzzy, nâng cao đáng kể mức độ liên quan, chính xác của kết quả nhờ hiểu ngữ cảnh và ý nghĩa truy vấn.
Khi triển khai tìm kiếm ngữ nghĩa, dữ liệu văn bản được chuyển thành vector embedding ghi lại ý nghĩa ngữ nghĩa. Các embedding này là các biểu diễn số có chiều cao. Để tìm kiếm qua các embedding này hiệu quả và tìm embedding gần nhất với embedding truy vấn, ta cần một công cụ tối ưu hóa cho tìm kiếm tương đồng trong không gian nhiều chiều.
FAISS cung cấp các thuật toán và cấu trúc dữ liệu cần thiết để thực hiện tác vụ này hiệu quả. Bằng cách kết hợp embedding ngữ nghĩa với FAISS, chúng ta có thể xây dựng công cụ tìm kiếm ngữ nghĩa mạnh mẽ, xử lý tập dữ liệu lớn với độ trễ thấp.
Triển khai tìm kiếm ngữ nghĩa với FAISS trong Python gồm các bước:
Hãy tìm hiểu chi tiết từng bước.
Chuẩn bị bộ dữ liệu của bạn (ví dụ: bài viết, phiếu hỗ trợ, mô tả sản phẩm).
Ví dụ:
documents = [
"How to reset your password on our platform.",
"Troubleshooting network connectivity issues.",
"Guide to installing software updates.",
"Best practices for data backup and recovery.",
"Setting up two-factor authentication for enhanced security."
]
Làm sạch và định dạng dữ liệu văn bản nếu cần.
Chuyển dữ liệu văn bản thành vector embedding bằng mô hình Transformer đã huấn luyện sẵn từ các thư viện như Hugging Face (transformers hoặc sentence-transformers).
Ví dụ:
from sentence_transformers import SentenceTransformer
import numpy as np
# Tải mô hình đã huấn luyện
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# Sinh embedding cho tất cả tài liệu
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
float32 như FAISS yêu cầu.Tạo chỉ mục FAISS để lưu embedding và cho phép tìm kiếm tương đồng hiệu quả.
Ví dụ:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 tìm kiếm chính xác bằng khoảng cách L2 (Euclid).Chuyển truy vấn người dùng thành embedding và tìm hàng xóm gần nhất.
Ví dụ:
query = "How do I change my account password?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
Dùng chỉ số để hiển thị các tài liệu phù hợp nhất.
Ví dụ:
print("Top results for your query:")
for idx in indices[0]:
print(documents[idx])
Kết quả mong đợi:
Top results for your query:
How to reset your password on our platform.
Setting up two-factor authentication for enhanced security.
Best practices for data backup and recovery.
FAISS cung cấp nhiều loại chỉ mục:
Dùng Inverted File Index (IndexIVFFlat):
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
Chuẩn hóa và tìm kiếm theo tích trong:
Sử dụng cosine similarity có thể hiệu quả hơn cho dữ liệu văn bản
Tìm kiếm AI là phương pháp tìm kiếm hiện đại sử dụng học máy và vector embedding để hiểu ý định và ý nghĩa ngữ cảnh của truy vấn, mang lại kết quả chính xác và liên quan hơn so với tìm kiếm dựa trên từ khóa truyền thống.
Khác với tìm kiếm dựa trên từ khóa, vốn phụ thuộc vào sự khớp chính xác, Tìm kiếm AI diễn giải các mối quan hệ ngữ nghĩa và ý định đằng sau truy vấn, giúp hiệu quả với ngôn ngữ tự nhiên và các đầu vào mơ hồ.
Vector embedding là các biểu diễn số của văn bản, hình ảnh hoặc các loại dữ liệu khác, ghi lại ý nghĩa ngữ nghĩa của chúng, cho phép công cụ tìm kiếm đo lường sự tương đồng và ngữ cảnh giữa các dữ liệu khác nhau.
Tìm kiếm AI cung cấp tìm kiếm ngữ nghĩa trong thương mại điện tử, gợi ý cá nhân hóa trong dịch vụ streaming, hệ thống hỏi đáp trong hỗ trợ khách hàng, duyệt dữ liệu phi cấu trúc và truy xuất tài liệu trong nghiên cứu và doanh nghiệp.
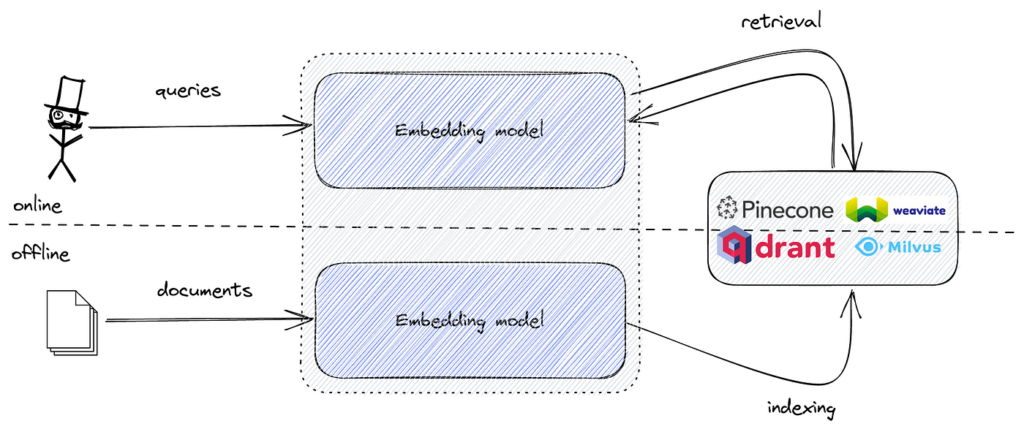
Các công cụ phổ biến bao gồm FAISS để tìm kiếm tương đồng vector hiệu quả, và các cơ sở dữ liệu vector như Pinecone, Milvus, Qdrant, Weaviate, Elasticsearch, và Pgvector để lưu trữ và truy xuất embedding quy mô lớn.
Bằng cách tích hợp Tìm kiếm AI, chatbot và hệ thống tự động hóa có thể hiểu truy vấn người dùng sâu sắc hơn, truy xuất câu trả lời phù hợp theo ngữ cảnh và đưa ra phản hồi động, cá nhân hóa.
Các thách thức bao gồm yêu cầu tính toán cao, phức tạp trong việc giải thích mô hình, cần dữ liệu chất lượng cao và đảm bảo quyền riêng tư, bảo mật với thông tin nhạy cảm.
FAISS là thư viện mã nguồn mở dùng để tìm kiếm tương đồng hiệu quả trên vector embedding nhiều chiều, được sử dụng rộng rãi để xây dựng công cụ tìm kiếm ngữ nghĩa xử lý tập dữ liệu lớn.
Khám phá cách tìm kiếm ngữ nghĩa được hỗ trợ bởi AI có thể chuyển đổi quy trình truy xuất thông tin, chatbot và tự động hóa của bạn.
Truy xuất Thông tin tận dụng AI, Xử lý Ngôn ngữ Tự nhiên (NLP) và học máy để truy xuất dữ liệu đáp ứng yêu cầu của người dùng một cách hiệu quả và chính xác. Là...
Khám phá Insight Engine là gì—một nền tảng tiên tiến, vận hành bởi AI giúp nâng cao khả năng tìm kiếm và phân tích dữ liệu bằng cách hiểu ngữ cảnh và ý định. Tì...
Perplexity AI là một công cụ tìm kiếm và trò chuyện dựa trên AI tiên tiến, tận dụng NLP và học máy để cung cấp câu trả lời chính xác, theo ngữ cảnh kèm trích dẫ...