Học Máy
Học Máy (Machine Learning - ML) là một nhánh của trí tuệ nhân tạo (AI) cho phép máy móc học từ dữ liệu, nhận diện các mẫu, đưa ra dự đoán và cải thiện việc ra q...
4 phút đọc
Machine Learning
AI
+4
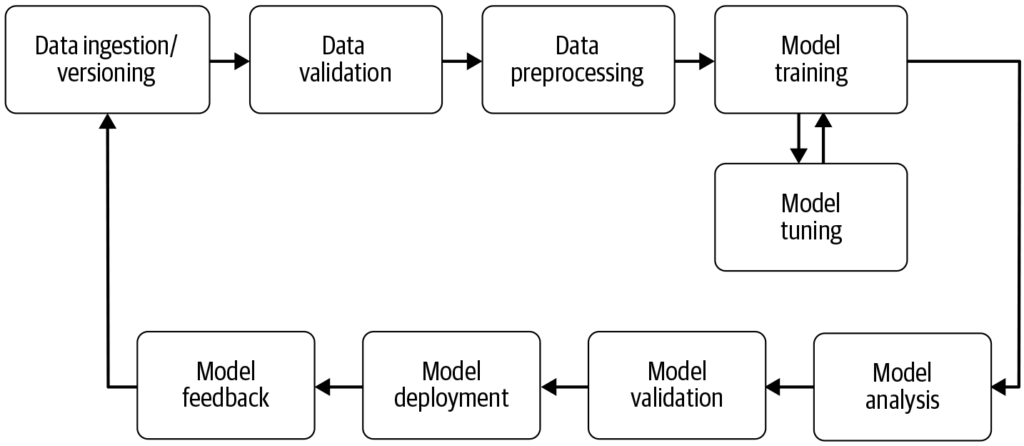
Quy trình máy học tự động hóa các bước từ thu thập dữ liệu đến triển khai mô hình, nâng cao hiệu quả, khả năng tái lập và mở rộng trong các dự án máy học.
Quy trình máy học là một quy trình làm việc tự động giúp hợp lý hóa việc phát triển, huấn luyện, đánh giá và triển khai các mô hình. Nó nâng cao hiệu quả, khả năng tái lập và mở rộng, hỗ trợ các tác vụ từ thu thập dữ liệu đến triển khai và bảo trì mô hình.
Quy trình máy học là một quy trình làm việc tự động bao gồm chuỗi các bước trong phát triển, huấn luyện, đánh giá và triển khai các mô hình máy học. Nó được thiết kế để hợp lý hóa và chuẩn hóa các quy trình cần thiết nhằm chuyển đổi dữ liệu thô thành thông tin giá trị qua các thuật toán máy học. Cách tiếp cận theo quy trình cho phép xử lý dữ liệu, huấn luyện và triển khai mô hình một cách hiệu quả, giúp dễ dàng quản lý và mở rộng các hoạt động máy học.
Nguồn: Building Machine Learning
Thu Thập Dữ Liệu: Giai đoạn đầu tiên nơi dữ liệu được thu thập từ nhiều nguồn khác nhau như cơ sở dữ liệu, API hoặc tệp. Thu thập dữ liệu là một thực hành có phương pháp nhằm lấy thông tin giá trị để xây dựng bộ dữ liệu nhất quán và đầy đủ cho một mục đích kinh doanh cụ thể. Dữ liệu thô này rất cần thiết để xây dựng các mô hình máy học nhưng thường cần phải tiền xử lý để trở nên hữu ích. Như AltexSoft đã chỉ ra, thu thập dữ liệu liên quan đến việc tích lũy hệ thống thông tin để hỗ trợ phân tích và ra quyết định. Quá trình này rất quan trọng vì nó đặt nền móng cho tất cả các bước tiếp theo trong quy trình và thường là liên tục để đảm bảo các mô hình được huấn luyện trên dữ liệu phù hợp và cập nhật.
Tiền Xử Lý Dữ Liệu: Dữ liệu thô được làm sạch và chuyển đổi thành định dạng phù hợp cho huấn luyện mô hình. Các bước tiền xử lý phổ biến bao gồm xử lý giá trị thiếu, mã hóa biến phân loại, chuẩn hóa các đặc trưng số và chia dữ liệu thành bộ huấn luyện và kiểm thử. Giai đoạn này đảm bảo dữ liệu ở đúng định dạng và không có các bất nhất có thể ảnh hưởng đến hiệu suất mô hình.
Xây Dựng Đặc Trưng: Tạo ra các đặc trưng mới hoặc chọn các đặc trưng phù hợp từ dữ liệu để cải thiện khả năng dự đoán của mô hình. Bước này có thể đòi hỏi kiến thức chuyên ngành và sự sáng tạo. Xây dựng đặc trưng là một quá trình sáng tạo biến đổi dữ liệu thô thành các đặc trưng có ý nghĩa hơn, đại diện tốt hơn cho bài toán và nâng cao hiệu suất của các mô hình máy học.
Lựa Chọn Mô Hình: Lựa chọn thuật toán máy học phù hợp dựa trên loại bài toán (ví dụ: phân loại, hồi quy), đặc điểm dữ liệu và yêu cầu về hiệu suất. Có thể cân nhắc điều chỉnh siêu tham số ở giai đoạn này. Việc chọn đúng mô hình rất quan trọng vì nó ảnh hưởng đến độ chính xác và hiệu quả của dự báo.
Huấn Luyện Mô Hình: Các mô hình đã chọn được huấn luyện trên bộ dữ liệu huấn luyện. Quá trình này giúp mô hình học các mẫu và mối quan hệ tiềm ẩn trong dữ liệu. Có thể sử dụng các mô hình đã được huấn luyện trước thay vì xây dựng mới từ đầu. Huấn luyện là bước then chốt giúp mô hình học hỏi từ dữ liệu để đưa ra dự đoán chính xác.
Đánh Giá Mô Hình: Sau khi huấn luyện, hiệu suất của mô hình được đánh giá bằng bộ dữ liệu kiểm thử riêng biệt hoặc qua xác thực chéo. Các chỉ số đánh giá tùy thuộc vào bài toán cụ thể, có thể gồm độ chính xác, độ nhạy, độ bao phủ, điểm F1, sai số bình phương trung bình,… Bước này rất quan trọng để đảm bảo mô hình hoạt động tốt trên dữ liệu chưa từng thấy.
Triển Khai Mô Hình: Khi đã có mô hình đạt yêu cầu, có thể triển khai vào môi trường thực tế để dự đoán trên dữ liệu mới. Triển khai có thể bao gồm xây dựng API và tích hợp với các hệ thống khác. Đây là giai đoạn cuối cùng của quy trình, nơi mô hình được sử dụng cho các ứng dụng thực tế.
Giám Sát và Bảo Trì: Sau triển khai, cần liên tục giám sát hiệu suất mô hình và huấn luyện lại khi cần để thích ứng với thay đổi của dữ liệu, đảm bảo mô hình luôn chính xác và đáng tin cậy trong thực tế. Quá trình này giúp mô hình luôn phù hợp và duy trì chất lượng theo thời gian.
Xử lý ngôn ngữ tự nhiên là cầu nối tương tác người-máy. Khám phá các khía cạnh chính, nguyên lý hoạt động và ứng dụng của nó ngay hôm nay!") (NLP): Các tác vụ NLP thường gồm nhiều bước lặp lại như nhập dữ liệu, làm sạch văn bản, tách từ, phân tích cảm xúc. Quy trình giúp phân mảnh các bước này, dễ dàng chỉnh sửa và cập nhật mà không ảnh hưởng đến các thành phần khác.
Bảo trì dự đoán: Trong các ngành như sản xuất, quy trình có thể được dùng để dự đoán hỏng hóc thiết bị bằng cách phân tích dữ liệu cảm biến, từ đó bảo trì chủ động và giảm thời gian ngưng máy.
Tài chính: Quy trình có thể tự động hóa xử lý dữ liệu tài chính để phát hiện gian lận, đánh giá rủi ro tín dụng hoặc dự đoán giá cổ phiếu, nâng cao quá trình ra quyết định.
Y tế: Trong lĩnh vực y tế, quy trình có thể xử lý hình ảnh y tế hoặc hồ sơ bệnh án để hỗ trợ chẩn đoán hoặc dự đoán kết quả điều trị, cải thiện chiến lược điều trị.
Quy trình máy học là phần không thể thiếu của AI và tự động hóa](https://www.flowhunt.io#:~:text=automation “Xây dựng công cụ AI và chatbot với nền tảng no-code của FlowHunt. Khám phá mẫu, thành phần và tự động hóa liền mạch. Đặt lịch demo ngay!”) bằng cách cung cấp một khuôn khổ có cấu trúc để tự động hóa các tác vụ máy học. Trong lĩnh vực tự động hóa AI, quy trình đảm bảo mô hình được huấn luyện và triển khai hiệu quả, cho phép các hệ thống AI như [chatbot học hỏi và thích ứng với dữ liệu mới mà không cần can thiệp thủ công. Sự tự động hóa này rất quan trọng để mở rộng các ứng dụng AI và đảm bảo chúng mang lại hiệu suất nhất quán, đáng tin cậy trên nhiều lĩnh vực khác nhau. Thông qua quy trình, tổ chức có thể tăng cường năng lực AI và đảm bảo các mô hình máy học luôn phù hợp, hiệu quả trong môi trường thay đổi.
Nghiên Cứu Về Quy Trình Máy Học
“Deep Pipeline Embeddings for AutoML” của Sebastian Pineda Arango và Josif Grabocka (2023) tập trung vào các thách thức tối ưu hóa quy trình máy học trong Automated Machine Learning (AutoML). Bài báo giới thiệu kiến trúc mạng nơ-ron mới nhằm nắm bắt các tương tác sâu giữa các thành phần quy trình. Tác giả đề xuất nhúng quy trình vào không gian tiềm ẩn qua một cơ chế mã hóa riêng cho từng thành phần. Các nhúng này được sử dụng trong khung tối ưu hóa Bayes để tìm kiếm quy trình tối ưu. Bài báo nhấn mạnh sử dụng meta-learning để tinh chỉnh tham số mạng nhúng quy trình, chứng minh kết quả hàng đầu trong tối ưu hóa quy trình trên nhiều bộ dữ liệu. Đọc thêm.
“AVATAR — Machine Learning Pipeline Evaluation Using Surrogate Model” của Tien-Dung Nguyen và cộng sự (2020) giải quyết vấn đề đánh giá quy trình máy học tốn thời gian trong AutoML. Nghiên cứu phê bình các phương pháp truyền thống như tối ưu hóa dựa trên Bayes và di truyền vì kém hiệu quả. Để khắc phục, tác giả trình bày AVATAR, một mô hình surrogate đánh giá hiệu lực quy trình mà không cần thực thi. Cách tiếp cận này tăng tốc đáng kể quá trình xây dựng và tối ưu hóa các quy trình phức tạp bằng cách loại bỏ các quy trình không hợp lệ ngay từ đầu. Đọc thêm.
“Data Pricing in Machine Learning Pipelines” của Zicun Cong và cộng sự (2021) nghiên cứu vai trò quan trọng của dữ liệu trong quy trình máy học và sự cần thiết của định giá dữ liệu để thúc đẩy hợp tác giữa nhiều bên liên quan. Bài báo tổng hợp các phát triển mới nhất về định giá dữ liệu trong bối cảnh máy học, tập trung vào tầm quan trọng của nó ở các giai đoạn khác nhau của quy trình. Nó cung cấp góc nhìn về các chiến lược định giá trong thu thập dữ liệu huấn luyện, huấn luyện mô hình hợp tác và cung cấp dịch vụ máy học, nhấn mạnh sự hình thành một hệ sinh thái năng động. Đọc thêm.
Quy trình máy học là một chuỗi các bước tự động — từ thu thập và tiền xử lý dữ liệu đến huấn luyện, đánh giá và triển khai mô hình — giúp hợp lý hóa và chuẩn hóa quá trình xây dựng và duy trì các mô hình máy học.
Các thành phần chính gồm: thu thập dữ liệu, tiền xử lý dữ liệu, xây dựng đặc trưng, lựa chọn mô hình, huấn luyện mô hình, đánh giá mô hình, triển khai mô hình, và giám sát cũng như bảo trì liên tục.
Quy trình máy học mang lại sự phân mảnh, hiệu quả, khả năng tái lập, mở rộng, tăng cường hợp tác và triển khai dễ dàng các mô hình vào môi trường thực tế.
Các trường hợp sử dụng bao gồm xử lý ngôn ngữ tự nhiên (NLP), bảo trì dự đoán trong sản xuất, đánh giá rủi ro tài chính và phát hiện gian lận, cũng như chẩn đoán y tế.
Các thách thức gồm đảm bảo chất lượng dữ liệu, quản lý độ phức tạp của quy trình, tích hợp với các hệ thống hiện có, và kiểm soát chi phí liên quan đến tài nguyên tính toán và hạ tầng.
Đặt lịch demo để khám phá cách FlowHunt giúp bạn tự động hóa và mở rộng quy trình máy học một cách dễ dàng.
Học Máy (Machine Learning - ML) là một nhánh của trí tuệ nhân tạo (AI) cho phép máy móc học từ dữ liệu, nhận diện các mẫu, đưa ra dự đoán và cải thiện việc ra q...
Học máy có giám sát là một phương pháp cơ bản trong học máy và trí tuệ nhân tạo, nơi các thuật toán học từ các tập dữ liệu đã được gán nhãn để đưa ra dự đoán ho...
BigML là một nền tảng học máy được thiết kế nhằm đơn giản hóa việc tạo và triển khai các mô hình dự đoán. Được thành lập vào năm 2011, sứ mệnh của BigML là giúp...