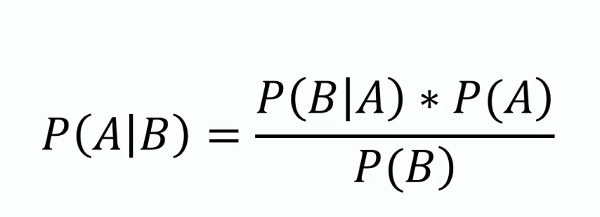
Mạng Bayesian
Mạng Bayesian (BN) là một mô hình đồ họa xác suất biểu diễn các biến và sự phụ thuộc có điều kiện của chúng thông qua Đồ thị Có Hướng Không Chu Trình (DAG). Mạn...
5 phút đọc
Bayesian Networks
AI
+3
Naive Bayes là một họ thuật toán phân loại đơn giản nhưng mạnh mẽ dựa trên Định lý Bayes, thường được sử dụng cho các nhiệm vụ quy mô lớn như phát hiện thư rác và phân loại văn bản.
Naive Bayes là một họ các thuật toán phân loại đơn giản và hiệu quả dựa trên Định lý Bayes, với giả định các đặc trưng là độc lập có điều kiện. Nó được sử dụng rộng rãi cho phát hiện thư rác, phân loại văn bản và nhiều ứng dụng khác nhờ tính đơn giản và khả năng mở rộng.
Naive Bayes là một họ các thuật toán phân loại dựa trên Định lý Bayes, áp dụng nguyên lý xác suất có điều kiện. Thuật ngữ “naive” (ngây thơ) đề cập đến giả định đơn giản hóa rằng tất cả các đặc trưng trong bộ dữ liệu là độc lập có điều kiện với nhau dựa trên nhãn lớp. Mặc dù giả định này thường bị vi phạm trong dữ liệu thực tế, các bộ phân loại Naive Bayes vẫn được ghi nhận về sự đơn giản và hiệu quả trong nhiều ứng dụng như phân loại văn bản và phát hiện thư rác.
Định lý Bayes
Định lý này là nền tảng của Naive Bayes, cung cấp phương pháp cập nhật ước lượng xác suất của một giả thuyết khi có thêm bằng chứng hoặc thông tin mới. Về mặt toán học, nó được biểu diễn như sau:
trong đó ( P(A|B) ) là xác suất hậu nghiệm, ( P(B|A) ) là độ khả dĩ, ( P(A) ) là xác suất tiên nghiệm, và ( P(B) ) là bằng chứng.
Tính độc lập có điều kiện
Giả định ngây thơ rằng mỗi đặc trưng là độc lập với các đặc trưng khác khi biết nhãn lớp. Giả định này giúp đơn giản hóa việc tính toán và cho phép thuật toán mở rộng tốt với các bộ dữ liệu lớn.
Xác suất hậu nghiệm
Xác suất của nhãn lớp khi biết giá trị các đặc trưng, được tính bằng Định lý Bayes. Đây là thành phần trung tâm trong quá trình dự đoán với Naive Bayes.
Các loại bộ phân loại Naive Bayes
Bộ phân loại Naive Bayes hoạt động bằng cách tính xác suất hậu nghiệm cho từng lớp dựa trên tập hợp các đặc trưng và chọn lớp có xác suất hậu nghiệm cao nhất. Quá trình này gồm các bước sau:
Bộ phân loại Naive Bayes đặc biệt hiệu quả trong các ứng dụng sau:
Xem xét ứng dụng lọc thư rác sử dụng Naive Bayes. Dữ liệu huấn luyện gồm các email được gán nhãn “thư rác” hoặc “không phải thư rác”. Mỗi email được biểu diễn bằng tập các đặc trưng như sự xuất hiện của các từ cụ thể. Trong quá trình huấn luyện, thuật toán tính xác suất của mỗi từ dựa trên nhãn lớp. Với một email mới, thuật toán tính xác suất hậu nghiệm cho “thư rác” và “không phải thư rác” và gán nhãn có xác suất cao hơn.
Bộ phân loại Naive Bayes có thể tích hợp vào các hệ thống AI và chatbot để tăng cường khả năng xử lý ngôn ngữ tự nhiên, kết nối giao tiếp giữa người với máy tính. Ví dụ, chúng có thể được dùng để nhận diện ý định của người dùng, phân loại văn bản theo các nhóm đã định trước hoặc lọc nội dung không phù hợp. Chức năng này giúp cải thiện chất lượng và sự phù hợp của các giải pháp AI. Ngoài ra, hiệu quả của thuật toán giúp nó phù hợp cho các ứng dụng thời gian thực, một yếu tố quan trọng với tự động hóa AI và các hệ thống chatbot.
Naive Bayes là một họ các thuật toán xác suất đơn giản nhưng mạnh mẽ dựa trên việc áp dụng Định lý Bayes với giả định mạnh về sự độc lập giữa các đặc trưng. Nó được sử dụng rộng rãi cho các nhiệm vụ phân loại nhờ sự đơn giản và hiệu quả. Dưới đây là một số bài báo khoa học thảo luận về các ứng dụng và cải tiến của bộ phân loại Naive Bayes:
Cải thiện lọc thư rác bằng cách kết hợp Naive Bayes với tìm kiếm k-láng giềng gần nhất đơn giản
Tác giả: Daniel Etzold
Xuất bản: 30 tháng 11, 2003
Bài báo này nghiên cứu việc sử dụng Naive Bayes cho phân loại email, nhấn mạnh tính dễ triển khai và hiệu quả của nó. Nghiên cứu trình bày kết quả thực nghiệm cho thấy việc kết hợp Naive Bayes với tìm kiếm k-láng giềng gần nhất có thể nâng cao độ chính xác của bộ lọc thư rác. Sự kết hợp này mang lại cải thiện nhẹ về độ chính xác với số lượng đặc trưng lớn và cải thiện đáng kể khi số đặc trưng ít. Đọc bài báo.
Naive Bayes có trọng số cục bộ (Locally Weighted Naive Bayes)
Tác giả: Eibe Frank, Mark Hall, Bernhard Pfahringer
Xuất bản: 19 tháng 10, 2012
Bài báo này đề cập đến điểm yếu chính của Naive Bayes là giả định độc lập giữa các thuộc tính. Nó giới thiệu phiên bản Naive Bayes có trọng số cục bộ, học mô hình cục bộ tại thời điểm dự đoán, do đó giảm bớt giả định độc lập. Kết quả thực nghiệm cho thấy cách tiếp cận này hiếm khi làm giảm độ chính xác và thường cải thiện đáng kể. Phương pháp này được đánh giá cao về sự đơn giản về mặt ý tưởng và tính toán so với các kỹ thuật khác. Đọc bài báo.
Phát hiện kẹt bẫy cho robot hành tinh bằng Naive Bayes
Tác giả: Dicong Qiu
Xuất bản: 31 tháng 1, 2018
Nghiên cứu này thảo luận về ứng dụng bộ phân loại Naive Bayes cho việc phát hiện kẹt bẫy ở robot hành tinh. Bài viết định nghĩa tiêu chí kẹt bẫy của robot và trình bày cách sử dụng Naive Bayes để phát hiện các tình huống này. Nghiên cứu chi tiết các thí nghiệm với robot AutoKrawler, cung cấp cái nhìn về hiệu quả của Naive Bayes cho các quy trình cứu hộ tự động. Đọc bài báo.
Naive Bayes là một họ các thuật toán phân loại dựa trên Định lý Bayes, giả định rằng tất cả các đặc trưng là độc lập có điều kiện với nhãn lớp. Nó được sử dụng rộng rãi cho phân loại văn bản, lọc thư rác và phân tích cảm xúc.
Các loại chính bao gồm Gaussian Naive Bayes (cho đặc trưng liên tục), Multinomial Naive Bayes (cho đặc trưng rời rạc như số lượng từ) và Bernoulli Naive Bayes (cho đặc trưng nhị phân/boolean).
Naive Bayes dễ triển khai, hiệu quả tính toán, mở rộng tốt cho các bộ dữ liệu lớn và xử lý tốt dữ liệu có số chiều lớn.
Hạn chế chính là giả định các đặc trưng độc lập, điều này thường không đúng với dữ liệu thực tế. Ngoài ra, nó có thể gán xác suất bằng 0 cho các đặc trưng chưa từng xuất hiện, có thể khắc phục bằng các kỹ thuật như làm trơn Laplace.
Naive Bayes được sử dụng trong các hệ thống AI và chatbot cho nhận diện ý định, phân loại văn bản, lọc thư rác và phân tích cảm xúc, nâng cao khả năng xử lý ngôn ngữ tự nhiên và cho phép ra quyết định theo thời gian thực.
Chatbot thông minh và công cụ AI trong một nền tảng. Kết nối các khối trực quan để biến ý tưởng của bạn thành các luồng tự động hóa.
Mạng Bayesian (BN) là một mô hình đồ họa xác suất biểu diễn các biến và sự phụ thuộc có điều kiện của chúng thông qua Đồ thị Có Hướng Không Chu Trình (DAG). Mạn...
Mô hình định xác là một mô hình toán học hoặc mô hình tính toán tạo ra một đầu ra duy nhất, xác định cho một tập hợp điều kiện đầu vào, mang lại tính dự đoán và...
Học Không Dựa Trên Dữ Liệu Huấn Luyện là một phương pháp trong AI cho phép mô hình nhận diện các đối tượng hoặc danh mục dữ liệu mà không cần được huấn luyện rõ...