Trả lời câu hỏi với RAG nâng cao LLM bằng cách tích hợp truy xuất dữ liệu theo thời gian thực và sinh ngôn ngữ tự nhiên để tạo ra các câu trả lời chính xác, liên quan theo ngữ cảnh.
AI
Question Answering
RAG
LLM
Semantic Search
Natural Language Generation
Trả Lời Câu Hỏi
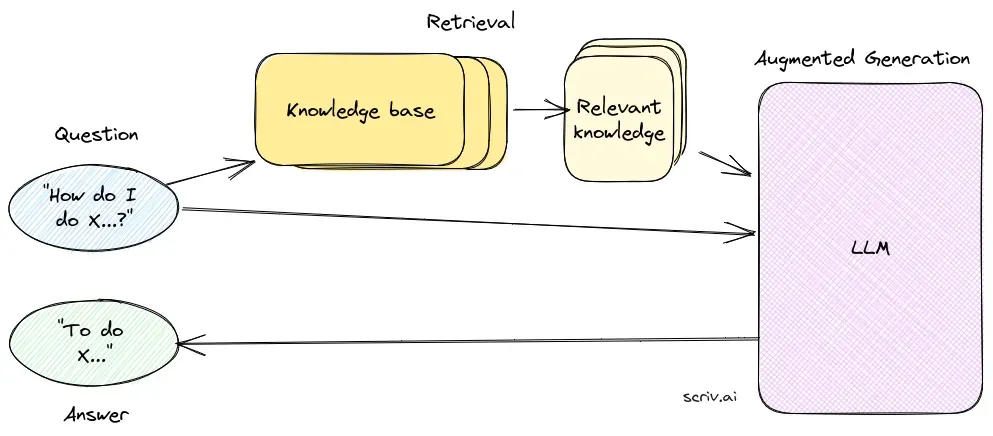
Trả lời câu hỏi với Retrieval-Augmented Generation (RAG) nâng cao các mô hình ngôn ngữ bằng cách tích hợp dữ liệu bên ngoài theo thời gian thực để tạo ra các câu trả lời chính xác và liên quan. Nó tối ưu hiệu suất trong các lĩnh vực động, mang lại độ chính xác cao hơn, nội dung động và tăng tính liên quan.
Trả lời câu hỏi với Retrieval-Augmented Generation (RAG) là một phương pháp sáng tạo kết hợp điểm mạnh của truy xuất thông tin và sinh ngôn ngữ tự nhiên, tạo ra văn bản giống con người từ dữ liệu, nâng cao AI, chatbot, báo cáo và cá nhân hóa trải nghiệm. Phương pháp lai này tăng cường khả năng của các mô hình ngôn ngữ lớn (LLMs) bằng cách bổ sung cho câu trả lời của chúng những thông tin liên quan, cập nhật được truy xuất từ các nguồn dữ liệu bên ngoài. Khác với các phương pháp truyền thống chỉ dựa vào mô hình đã huấn luyện trước, RAG tích hợp động dữ liệu bên ngoài, cho phép hệ thống cung cấp câu trả lời chính xác và liên quan theo ngữ cảnh hơn, đặc biệt trong các lĩnh vực cần thông tin mới nhất hoặc kiến thức chuyên ngành.
RAG tối ưu hóa hiệu suất của các LLM bằng cách đảm bảo rằng câu trả lời không chỉ sinh ra từ tập dữ liệu nội bộ mà còn dựa trên các nguồn tin cậy theo thời gian thực. Cách tiếp cận này rất quan trọng đối với các nhiệm vụ trả lời câu hỏi trong các lĩnh vực biến động, nơi thông tin luôn thay đổi.
Các Thành Phần Cốt Lõi của RAG
1. Thành Phần Truy Xuất
Thành phần truy xuất chịu trách nhiệm tìm kiếm thông tin liên quan từ các tập dữ liệu lớn, thường được lưu trữ trong cơ sở dữ liệu vector. Thành phần này sử dụng kỹ thuật tìm kiếm ngữ nghĩa để xác định và trích xuất các đoạn văn bản hoặc tài liệu có mức độ liên quan cao với truy vấn của người dùng.
Cơ Sở Dữ Liệu Vector: Cơ sở dữ liệu chuyên dụng lưu trữ các biểu diễn vector của tài liệu. Các embedding này giúp tìm kiếm và truy xuất hiệu quả bằng cách đối sánh ý nghĩa ngữ nghĩa của truy vấn người dùng với các đoạn văn bản liên quan.
Tìm Kiếm Ngữ Nghĩa: Sử dụng embedding vector để tìm tài liệu dựa trên sự tương đồng về ngữ nghĩa thay vì chỉ khớp từ khóa, nâng cao độ chính xác và mức độ liên quan của thông tin truy xuất.
2. Thành Phần Sinh
Thành phần sinh, thường là một LLM như GPT-3 hoặc BERT, tổng hợp câu trả lời bằng cách kết hợp truy vấn gốc của người dùng với ngữ cảnh được truy xuất. Thành phần này rất quan trọng để tạo ra các câu trả lời mạch lạc và phù hợp với ngữ cảnh.
Mô Hình Ngôn Ngữ (LLMs): Được huấn luyện để sinh văn bản dựa trên các prompt đầu vào, LLM trong hệ thống RAG sử dụng các tài liệu truy xuất làm ngữ cảnh để nâng cao chất lượng và tính liên quan của câu trả lời được tạo ra.
Quy Trình Hoạt Động của Hệ Thống RAG
Chuẩn Bị Tài Liệu: Hệ thống bắt đầu bằng cách nạp một tập hợp lớn tài liệu, chuyển đổi chúng thành định dạng phù hợp để phân tích. Điều này thường bao gồm việc chia nhỏ tài liệu thành các đoạn dễ xử lý.
Vector Embedding: Mỗi đoạn tài liệu được chuyển đổi thành biểu diễn vector bằng embedding tạo ra từ các mô hình ngôn ngữ. Các vector này được lưu vào cơ sở dữ liệu vector để truy xuất hiệu quả.
Xử Lý Truy Vấn: Khi nhận được truy vấn của người dùng, hệ thống chuyển đổi truy vấn thành vector và thực hiện tìm kiếm tương đồng trong cơ sở dữ liệu vector để xác định các đoạn tài liệu liên quan.
Sinh Câu Trả Lời Theo Ngữ Cảnh: Các đoạn tài liệu truy xuất được kết hợp với truy vấn người dùng và đưa vào LLM, từ đó sinh ra câu trả lời cuối cùng giàu ngữ cảnh.
Đầu Ra: Hệ thống xuất ra một câu trả lời vừa chính xác vừa phù hợp với truy vấn, được bổ sung thông tin phù hợp với ngữ cảnh.
Lợi Ích của RAG
Nâng Cao Độ Chính Xác: Bằng cách truy xuất ngữ cảnh liên quan, RAG giảm nguy cơ tạo ra câu trả lời sai hoặc lỗi thời, vốn là vấn đề thường gặp ở các LLM độc lập.
Nội Dung Động: Hệ thống RAG có thể tích hợp thông tin mới nhất từ các kho kiến thức được cập nhật, rất phù hợp cho các lĩnh vực cần dữ liệu hiện thời.
Tăng Tính Liên Quan: Quy trình truy xuất đảm bảo câu trả lời sinh ra được cá nhân hóa theo ngữ cảnh truy vấn, nâng cao chất lượng và mức độ liên quan của phản hồi.
Ứng Dụng
Chatbot và Trợ Lý Ảo: Hệ thống sử dụng RAG giúp chatbot và trợ lý ảo đưa ra phản hồi chính xác, nhận biết ngữ cảnh, cải thiện tương tác và sự hài lòng của người dùng.
Hỗ Trợ Khách Hàng: Trong lĩnh vực hỗ trợ khách hàng, hệ thống RAG có thể truy xuất tài liệu chính sách hoặc thông tin sản phẩm để trả lời chính xác cho truy vấn của người dùng.
Tạo Nội Dung: Mô hình RAG có thể sinh tài liệu, báo cáo bằng cách tích hợp thông tin truy xuất, hữu ích cho các nhiệm vụ tạo nội dung tự động.
Công Cụ Giáo Dục: Trong giáo dục, hệ thống RAG có thể tăng cường các trợ lý học tập cung cấp giải thích, tóm tắt dựa trên nội dung giáo dục mới nhất.
Triển Khai Kỹ Thuật
Việc triển khai một hệ thống RAG bao gồm các bước kỹ thuật sau:
Lưu Trữ và Truy Xuất Vector: Sử dụng cơ sở dữ liệu vector như Pinecone hoặc FAISS để lưu trữ và truy xuất embedding tài liệu hiệu quả.
Tích Hợp Mô Hình Ngôn Ngữ: Tích hợp các LLM như GPT-3 hoặc mô hình tùy chỉnh thông qua các framework như HuggingFace Transformers để thực hiện khâu sinh.
Cấu Hình Quy Trình: Thiết lập quy trình quản lý luồng từ truy xuất tài liệu đến sinh câu trả lời, đảm bảo tích hợp mượt mà các thành phần.
Thách Thức và Lưu Ý
Chi Phí và Quản Lý Tài Nguyên: Hệ thống RAG có thể tiêu tốn nhiều tài nguyên, cần tối ưu hóa để kiểm soát chi phí tính toán hiệu quả.
Độ Chính Xác Thực Tế: Đảm bảo thông tin truy xuất là chính xác và cập nhật rất quan trọng nhằm tránh tạo ra câu trả lời sai lệch.
Độ Phức Tạp Khi Thiết Lập: Việc thiết lập ban đầu hệ thống RAG có thể phức tạp, liên quan đến nhiều thành phần cần tích hợp và tối ưu hóa cẩn thận.
Nghiên cứu về Trả Lời Câu Hỏi với Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) là một phương pháp nâng cao hệ thống trả lời câu hỏi bằng cách kết hợp cơ chế truy xuất với mô hình sinh. Nghiên cứu gần đây đã khám phá hiệu quả và tối ưu hóa RAG trong nhiều bối cảnh khác nhau.
In Defense of RAG in the Era of Long-Context Language Models: Bài báo này lập luận về sự phù hợp của RAG ngay cả khi xuất hiện các mô hình ngôn ngữ xử lý ngữ cảnh dài, vốn tích hợp các chuỗi văn bản dài hơn vào quá trình xử lý. Các tác giả đề xuất cơ chế Order-Preserve Retrieval-Augmented Generation (OP-RAG) nhằm tối ưu hiệu suất của RAG khi xử lý các nhiệm vụ trả lời câu hỏi ngữ cảnh dài. Họ chứng minh qua thực nghiệm rằng OP-RAG có thể đạt chất lượng trả lời cao với ít token hơn so với mô hình ngữ cảnh dài. Đọc thêm.
CLAPNQ: Cohesive Long-form Answers from Passages in Natural Questions for RAG systems: Nghiên cứu này giới thiệu ClapNQ, bộ dữ liệu chuẩn dùng để đánh giá các hệ thống RAG trong việc sinh câu trả lời dài, mạch lạc. Bộ dữ liệu tập trung vào các câu trả lời dựa trên các đoạn văn bản cụ thể, không sinh thông tin không có thật, và khuyến khích mô hình RAG thích ứng với định dạng câu trả lời ngắn gọn, mạch lạc. Các tác giả cung cấp các thử nghiệm cơ bản làm nổi bật tiềm năng cải thiện của hệ thống RAG. Đọc thêm.
Optimizing Retrieval-Augmented Generation with Elasticsearch for Enhanced Question-Answering Systems: Nghiên cứu này tích hợp Elasticsearch vào khung RAG nhằm tăng hiệu quả và độ chính xác của hệ thống trả lời câu hỏi. Sử dụng bộ dữ liệu Stanford Question Answering Dataset (SQuAD) phiên bản 2.0, nghiên cứu so sánh nhiều phương pháp truy xuất và nhấn mạnh lợi thế của mô hình ES-RAG về hiệu suất truy xuất và độ chính xác, vượt trội hơn các phương pháp khác 0,51 điểm phần trăm. Bài báo đề xuất tiếp tục nghiên cứu sự tương tác giữa Elasticsearch và mô hình ngôn ngữ để nâng cao phản hồi của hệ thống. Đọc thêm.
Câu hỏi thường gặp
Retrieval-Augmented Generation (RAG) trong Trả Lời Câu Hỏi là gì?
RAG là một phương pháp kết hợp truy xuất thông tin và sinh ngôn ngữ tự nhiên để cung cấp các câu trả lời chính xác, cập nhật bằng cách tích hợp các nguồn dữ liệu bên ngoài vào các mô hình ngôn ngữ lớn.
Các thành phần chính của hệ thống RAG là gì?
Một hệ thống RAG bao gồm thành phần truy xuất, lấy thông tin liên quan từ cơ sở dữ liệu vector bằng tìm kiếm ngữ nghĩa, và thành phần sinh, thường là một LLM, tổng hợp câu trả lời dựa trên truy vấn người dùng và ngữ cảnh được truy xuất.
Lợi ích chính của việc sử dụng RAG cho trả lời câu hỏi là gì?
RAG cải thiện độ chính xác bằng cách truy xuất thông tin liên quan theo ngữ cảnh, hỗ trợ cập nhật nội dung động từ các kho kiến thức bên ngoài, và nâng cao tính liên quan cũng như chất lượng câu trả lời được tạo ra.
Các trường hợp sử dụng phổ biến cho trả lời câu hỏi dựa trên RAG là gì?
Các trường hợp sử dụng phổ biến bao gồm chatbot AI, hỗ trợ khách hàng, tạo nội dung tự động và công cụ giáo dục cần các câu trả lời chính xác, nhận biết ngữ cảnh và cập nhật thường xuyên.
Những thách thức cần lưu ý khi triển khai RAG là gì?
Hệ thống RAG có thể tiêu tốn nhiều tài nguyên, yêu cầu tích hợp cẩn thận để đạt hiệu suất tối ưu, và phải đảm bảo thông tin truy xuất là chính xác nhằm tránh câu trả lời sai lệch hoặc lỗi thời.
Bắt Đầu Xây Dựng Giải Pháp Trả Lời Câu Hỏi AI
Khám phá cách Retrieval-Augmented Generation có thể tăng cường chatbot và các giải pháp hỗ trợ của bạn với câu trả lời chính xác, theo thời gian thực.
Tạo sinh kết hợp truy xuất (CAG) và tạo sinh kết hợp truy hồi (RAG): So sánh
Khám phá những điểm khác biệt chính giữa Tạo sinh kết hợp truy hồi (RAG) và Tạo sinh kết hợp bộ nhớ đệm (CAG) trong AI. Tìm hiểu cách RAG truy xuất thông tin th...
Tạo sinh kết hợp truy xuất (RAG) là một khuôn khổ AI tiên tiến kết hợp các hệ thống truy xuất thông tin truyền thống với các mô hình ngôn ngữ lớn sinh sinh (LLM...
Khiến LLM tự kiểm tra thông tin và đính kèm nguồn tham khảo
Tăng độ chính xác AI với RIG! Tìm hiểu cách tạo chatbot kiểm tra thông tin bằng cả nguồn dữ liệu tùy chỉnh lẫn nguồn tổng hợp để mang lại câu trả lời đáng tin c...
6 phút đọc
AI
Chatbot
+5
Đồng Ý Cookie Chúng tôi sử dụng cookie để cải thiện trải nghiệm duyệt web của bạn và phân tích lưu lượng truy cập của mình. See our privacy policy.