Chatbot RAG Theo Miền Thời Gian Thực
Một chatbot thời gian thực sử dụng Google Search giới hạn trong miền của bạn, truy xuất nội dung web liên quan và tận dụng OpenAI LLM để trả lời truy vấn của ng...
5 phút đọc
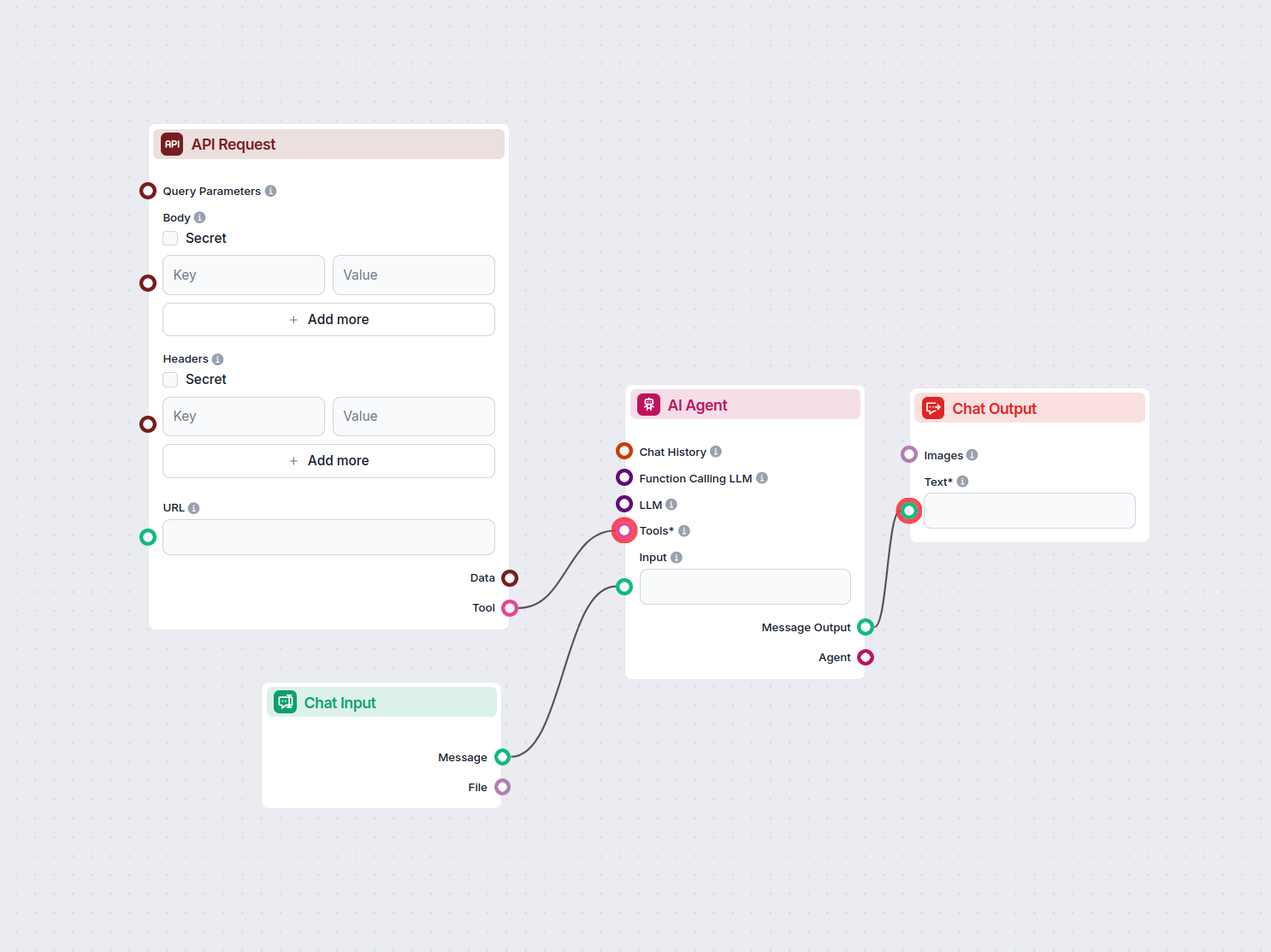
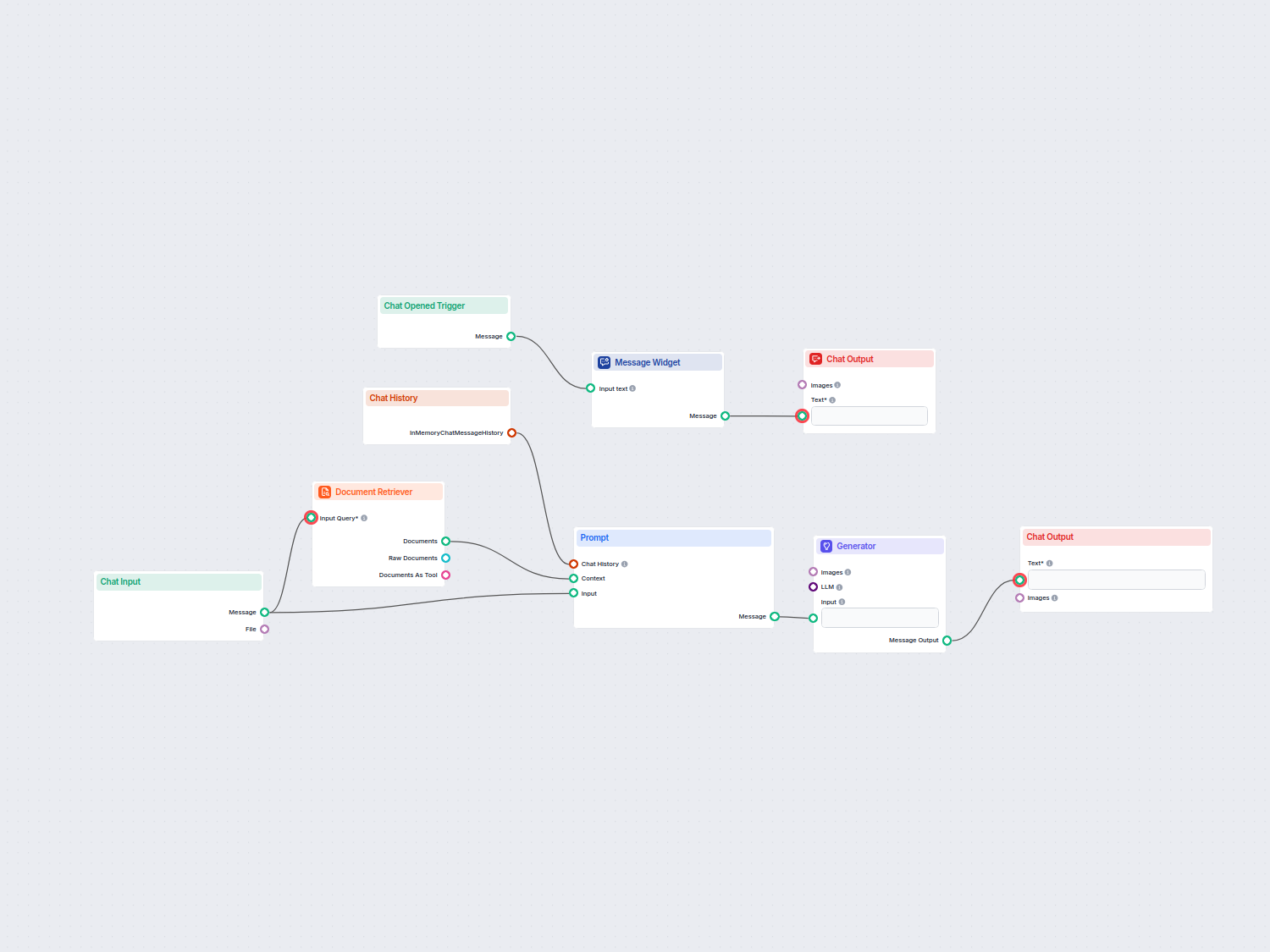
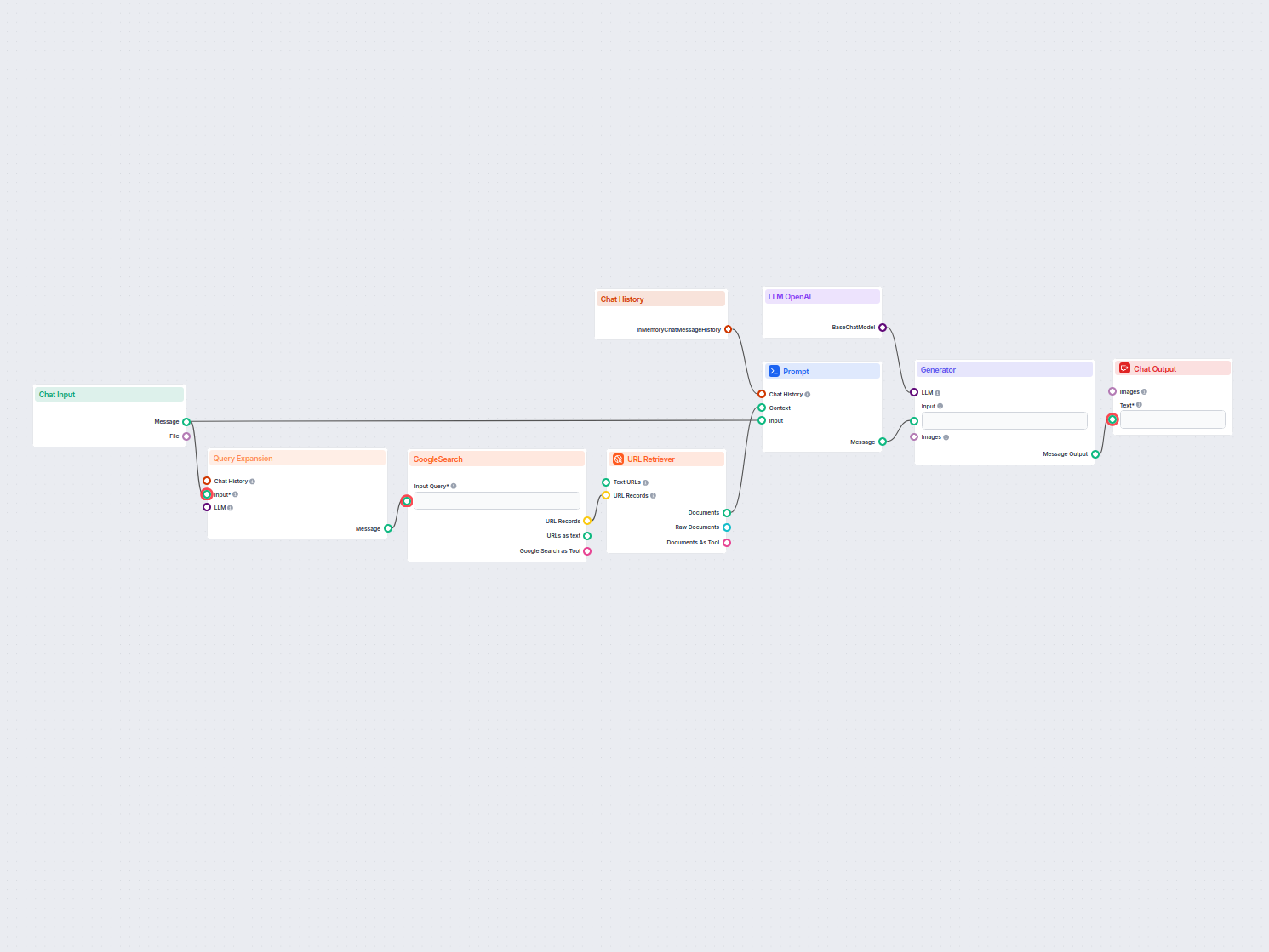
Quy trình truy xuất thông tin giúp chatbot lấy và xử lý tri thức bên ngoài phù hợp để trả lời chính xác, theo thời gian thực và theo ngữ cảnh bằng cách sử dụng RAG, embedding và cơ sở dữ liệu vector.
Quy trình truy xuất thông tin cho chatbot là kiến trúc kỹ thuật và quá trình giúp chatbot lấy, xử lý và truy xuất thông tin phù hợp để trả lời câu hỏi của người dùng. Khác với hệ thống hỏi đáp đơn giản chỉ dựa vào mô hình ngôn ngữ đã huấn luyện, quy trình này tích hợp các kho tri thức bên ngoài hoặc nguồn dữ liệu khác nhau. Điều này cho phép chatbot trả lời chính xác, phù hợp với ngữ cảnh và cập nhật mới nhất ngay cả khi dữ liệu không có sẵn trong mô hình ngôn ngữ.
Quy trình truy xuất thông tin thường gồm nhiều thành phần: thu thập dữ liệu, tạo embedding, lưu trữ vector, truy xuất ngữ cảnh và sinh phản hồi. Việc triển khai quy trình này thường tận dụng Retrieval-Augmented Generation (RAG), kết hợp sức mạnh của hệ thống truy xuất dữ liệu và Mô hình ngôn ngữ lớn (LLMs) để tạo phản hồi.
Quy trình này giúp tăng cường khả năng của chatbot bằng cách cho phép:
Thu Thập Tài Liệu
Thu thập và tiền xử lý dữ liệu thô, có thể là PDF, file văn bản, cơ sở dữ liệu hoặc API. Các công cụ như LangChain hoặc LlamaIndex thường được sử dụng để nhập dữ liệu thuận tiện.
Ví dụ: Tải lên câu hỏi thường gặp dịch vụ khách hàng hoặc thông số kỹ thuật sản phẩm vào hệ thống.
Tiền Xử Lý Tài Liệu
Các tài liệu dài được chia nhỏ thành các đoạn có ý nghĩa về mặt ngữ nghĩa. Điều này cần thiết để phù hợp với giới hạn token của các mô hình embedding (ví dụ: 512 token).
Ví dụ đoạn mã:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(document_list)
Tạo Embedding
Dữ liệu văn bản được chuyển thành vector không gian nhiều chiều bằng mô hình embedding. Các embedding này mã hóa ngữ nghĩa của dữ liệu dưới dạng số.
Ví dụ mô hình embedding: OpenAI’s text-embedding-ada-002 hoặc Hugging Face’s e5-large-v2.
Lưu Trữ Vector
Các embedding được lưu trong cơ sở dữ liệu vector tối ưu cho tìm kiếm theo độ tương đồng. Các công cụ như Milvus, Chroma hoặc PGVector thường được sử dụng.
Ví dụ: Lưu thông tin sản phẩm và embedding của chúng để truy xuất nhanh.
Xử Lý Truy Vấn
Khi nhận truy vấn từ người dùng, truy vấn được chuyển thành vector bằng cùng mô hình embedding. Điều này giúp so khớp ngữ nghĩa với các embedding đã lưu.
Ví dụ đoạn mã:
query_vector = embedding_model.encode("What are the specifications of Product X?")
retrieved_docs = vector_db.similarity_search(query_vector, k=5)
Truy Xuất Dữ Liệu
Hệ thống lấy ra các đoạn dữ liệu phù hợp nhất dựa trên điểm tương đồng (ví dụ: cosine similarity). Hệ thống truy xuất đa phương tiện có thể kết hợp cơ sở dữ liệu SQL, đồ thị tri thức và tìm kiếm vector để tăng độ tin cậy.
Sinh Phản Hồi
Dữ liệu truy xuất được kết hợp với truy vấn người dùng và đưa vào mô hình ngôn ngữ lớn (LLM) để sinh ra phản hồi cuối cùng bằng ngôn ngữ tự nhiên. Bước này thường gọi là augmented generation.
Ví dụ mẫu prompt:
prompt_template = """
Context: {context}
Question: {question}
Please provide a detailed response using the context above.
"""
Hậu Xử Lý Và Kiểm Tra
Các quy trình truy xuất nâng cao có thể phát hiện ảo giác, kiểm tra tính liên quan hoặc chấm điểm phản hồi để đảm bảo đầu ra chính xác, phù hợp.
Hỗ Trợ Khách Hàng
Chatbot có thể truy xuất hướng dẫn sử dụng sản phẩm, tài liệu hướng dẫn xử lý sự cố hoặc FAQ để trả lời khách hàng ngay lập tức.
Ví dụ: Chatbot giúp khách hàng đặt lại modem bằng cách truy xuất đúng phần hướng dẫn trong tài liệu sử dụng.
Quản Lý Tri Thức Doanh Nghiệp
Chatbot nội bộ truy cập dữ liệu doanh nghiệp như chính sách nhân sự, tài liệu hỗ trợ IT hoặc quy định tuân thủ.
Ví dụ: Nhân viên hỏi chatbot nội bộ về chính sách nghỉ ốm.
Thương Mại Điện Tử
Chatbot hỗ trợ người dùng truy xuất thông tin sản phẩm, đánh giá hoặc tình trạng kho hàng.
Ví dụ: “Những tính năng nổi bật của Sản phẩm Y là gì?”
Y Tế
Chatbot truy xuất tài liệu y khoa, hướng dẫn hoặc dữ liệu bệnh nhân hỗ trợ bác sĩ và bệnh nhân.
Ví dụ: Chatbot lấy cảnh báo tương tác thuốc từ cơ sở dữ liệu dược phẩm.
Giáo Dục & Nghiên Cứu
Chatbot học thuật dùng RAG để lấy bài báo khoa học, trả lời câu hỏi hoặc tóm tắt kết quả nghiên cứu.
Ví dụ: “Bạn có thể tóm tắt kết quả nghiên cứu về biến đổi khí hậu năm 2023 này không?”
Pháp Lý & Tuân Thủ
Chatbot truy xuất văn bản pháp luật, án lệ hoặc yêu cầu tuân thủ hỗ trợ chuyên gia pháp lý.
Ví dụ: “Cập nhật mới nhất về quy định GDPR là gì?”
Một chatbot được xây dựng để trả lời câu hỏi từ báo cáo tài chính thường niên của công ty ở định dạng PDF.
Một chatbot kết hợp truy vấn SQL, tìm kiếm vector và đồ thị tri thức để trả lời câu hỏi của nhân viên.
Nhờ tận dụng quy trình truy xuất, chatbot không còn giới hạn bởi dữ liệu đào tạo tĩnh, từ đó mang lại những tương tác động, chính xác và giàu ngữ cảnh.
Quy trình truy xuất thông tin đóng vai trò then chốt trong hệ thống chatbot hiện đại, giúp mang lại các tương tác thông minh và theo ngữ cảnh.
“Lingke: A Fine-grained Multi-turn Chatbot for Customer Service” của Pengfei Zhu và cộng sự (2018)
Giới thiệu Lingke, chatbot tích hợp truy xuất thông tin để xử lý hội thoại nhiều lượt. Hệ thống tận dụng quy trình xử lý chi tiết để trích xuất phản hồi từ tài liệu phi cấu trúc, kết hợp so khớp ngữ cảnh-chuỗi phản hồi, cải thiện đáng kể khả năng xử lý các truy vấn phức tạp của người dùng.
Đọc bài báo tại đây.
“FACTS About Building Retrieval Augmented Generation-based Chatbots” của Rama Akkiraju và cộng sự (2024)
Phân tích thách thức và phương pháp xây dựng chatbot doanh nghiệp dựa trên quy trình RAG và LLM. Nhóm tác giả đề xuất khung FACTS, nhấn mạnh các yếu tố Freshness (Tính mới), Architectures (Kiến trúc), Cost (Chi phí), Testing (Kiểm thử) và Security (Bảo mật) trong thiết kế quy trình RAG. Kết quả thực nghiệm làm rõ sự đánh đổi giữa độ chính xác và độ trễ khi mở rộng LLM, mang lại góc nhìn giá trị cho việc xây dựng chatbot hiệu suất cao và an toàn. Đọc bài báo tại đây.
“From Questions to Insightful Answers: Building an Informed Chatbot for University Resources” của Subash Neupane và cộng sự (2024)
Trình bày BARKPLUG V.2, hệ thống chatbot dành cho môi trường đại học. Sử dụng quy trình RAG, hệ thống cung cấp câu trả lời chính xác, chuyên ngành cho các câu hỏi về tài nguyên trong trường, nâng cao khả năng tiếp cận thông tin. Nghiên cứu đánh giá hiệu quả chatbot bằng các khung như RAG Assessment (RAGAS), chứng minh tính ứng dụng trong môi trường học thuật. Đọc bài báo tại đây.
Quy trình truy xuất thông tin là một kiến trúc kỹ thuật cho phép chatbot lấy, xử lý và truy xuất thông tin phù hợp từ các nguồn bên ngoài để trả lời câu hỏi của người dùng. Quy trình này kết hợp thu thập dữ liệu, tạo embedding, lưu trữ vector và sinh phản hồi bằng LLM để mang lại câu trả lời động, theo ngữ cảnh.
RAG kết hợp điểm mạnh của hệ thống truy xuất dữ liệu và các mô hình ngôn ngữ lớn (LLMs), cho phép chatbot dựa vào dữ liệu bên ngoài thực tế, mới nhất để trả lời, từ đó giảm hiện tượng 'ảo giác' và tăng độ chính xác.
Các thành phần chính gồm thu thập tài liệu, tiền xử lý, tạo embedding, lưu trữ vector, xử lý truy vấn, truy xuất dữ liệu, sinh phản hồi và kiểm tra sau xử lý.
Các trường hợp sử dụng gồm hỗ trợ khách hàng, quản lý tri thức doanh nghiệp, thông tin sản phẩm thương mại điện tử, tư vấn y tế, giáo dục & nghiên cứu, và hỗ trợ tuân thủ pháp lý.
Các thách thức bao gồm độ trễ do truy xuất thời gian thực, chi phí vận hành, lo ngại về bảo mật dữ liệu và yêu cầu mở rộng quy mô để xử lý lượng dữ liệu lớn.
Khai phá sức mạnh của Retrieval-Augmented Generation (RAG) và tích hợp dữ liệu bên ngoài để mang lại phản hồi thông minh, chính xác cho chatbot. Trải nghiệm nền tảng no-code FlowHunt ngay hôm nay.
Một chatbot thời gian thực sử dụng Google Search giới hạn trong miền của bạn, truy xuất nội dung web liên quan và tận dụng OpenAI LLM để trả lời truy vấn của ng...
Chatbot sử dụng AI này cung cấp ngay lập tức thông tin chi tiết về bất kỳ địa chỉ IP nào, bao gồm thành phố, quốc gia, múi giờ và nhà cung cấp dịch vụ Internet,...
Trợ lý chatbot AI sử dụng OpenAI GPT-4o, tự động tìm kiếm và khai thác các tài liệu nội bộ của công ty để trả lời câu hỏi của người dùng. Đưa ra phản hồi chính ...