Tự động phân loại
Tự động phân loại tự động hóa việc phân loại nội dung bằng cách phân tích các thuộc tính và gán thẻ nhờ các công nghệ như học máy, xử lý ngôn ngữ tự nhiên (NLP)...
12 phút đọc
AI
Auto-classification
+5
Phân loại văn bản sử dụng NLP và học máy để tự động gán danh mục cho văn bản, cung cấp năng lực cho các ứng dụng như phân tích cảm xúc, phát hiện spam và tổ chức dữ liệu.
Phân loại văn bản, còn gọi là phân loại chủ đề hoặc gắn thẻ văn bản, là một nhiệm vụ quan trọng của Xử lý Ngôn ngữ Tự nhiên (NLP) liên quan đến việc gán các danh mục đã được xác định trước cho các tài liệu văn bản. Phương pháp này giúp tổ chức, cấu trúc và phân loại dữ liệu văn bản phi cấu trúc, tạo điều kiện thuận lợi cho việc phân tích và diễn giải. Phân loại văn bản được ứng dụng trong nhiều lĩnh vực như phân tích cảm xúc, phát hiện spam và phân loại chủ đề.
Theo AWS, phân loại văn bản đóng vai trò là bước đầu tiên trong việc tổ chức, cấu trúc và phân loại dữ liệu để phục vụ cho các phân tích tiếp theo. Nó cho phép tự động gán nhãn và gắn thẻ tài liệu, giúp doanh nghiệp quản lý và phân tích khối lượng lớn dữ liệu văn bản một cách hiệu quả. Khả năng tự động hóa việc gán nhãn này giúp giảm thiểu sự can thiệp thủ công và nâng cao quá trình ra quyết định dựa trên dữ liệu.
Phân loại văn bản được thúc đẩy bởi học máy, trong đó các mô hình AI được huấn luyện trên các tập dữ liệu đã gán nhãn để học các mẫu và mối liên hệ giữa các đặc trưng văn bản với các danh mục tương ứng. Sau khi được huấn luyện, các mô hình này có thể phân loại các tài liệu văn bản mới chưa từng gặp với độ chính xác và hiệu quả cao. Theo Towards Data Science, quá trình này đơn giản hóa việc tổ chức nội dung, giúp người dùng dễ dàng tìm kiếm và điều hướng trong các trang web hoặc ứng dụng.
Mô hình phân loại văn bản là các thuật toán tự động hóa quá trình phân loại dữ liệu văn bản. Những mô hình này học từ các ví dụ trong tập dữ liệu huấn luyện và áp dụng kiến thức đã học để phân loại các đầu vào văn bản mới. Một số mô hình phổ biến gồm:
Máy Hỗ Trợ Vector (SVM): Một thuật toán học có giám sát hiệu quả cho cả các bài toán phân loại nhị phân và đa lớp. SVM xác định siêu phẳng tốt nhất phân tách các điểm dữ liệu thuộc các danh mục khác nhau. Phương pháp này phù hợp với các ứng dụng cần ranh giới phân loại rõ ràng.
Naive Bayes: Một bộ phân loại xác suất áp dụng Định lý Bayes với giả định các đặc trưng độc lập. Nó đặc biệt hiệu quả với các tập dữ liệu lớn nhờ sự đơn giản và hiệu quả tính toán. Naive Bayes thường dùng trong phát hiện spam và phân tích văn bản khi yêu cầu tốc độ xử lý nhanh.
Mô Hình Học Sâu: Gồm Mạng Nơ-ron Tích Chập (CNN) và Mạng Nơ-ron Hồi Quy (RNN), có khả năng nắm bắt các mẫu phức tạp trong dữ liệu văn bản nhờ sử dụng nhiều tầng xử lý. Các mô hình học sâu rất hữu ích với các nhiệm vụ phân loại văn bản quy mô lớn và có thể đạt độ chính xác cao trong phân tích cảm xúc cũng như mô hình hóa ngôn ngữ.
Cây Quyết Định và Rừng Ngẫu Nhiên: Các phương pháp dựa trên cây phân loại văn bản bằng cách học các quy tắc quyết định xuất phát từ các đặc trưng dữ liệu. Những mô hình này dễ diễn giải và có thể ứng dụng trong nhiều lĩnh vực như phân loại phản hồi khách hàng hoặc tài liệu.
Quy trình phân loại văn bản gồm nhiều bước:
Thu Thập và Chuẩn Bị Dữ Liệu: Dữ liệu văn bản được thu thập và tiền xử lý. Bước này có thể bao gồm tách từ, loại bỏ từ dừng và chuẩn hóa để làm sạch dữ liệu. Theo Levity AI, dữ liệu văn bản là tài sản quý giá để hiểu hành vi người tiêu dùng và việc tiền xử lý đúng cách là rất quan trọng để rút ra các thông tin hữu ích.
Trích Xuất Đặc Trưng: Chuyển đổi văn bản thành các biểu diễn số mà các thuật toán học máy có thể xử lý. Các kỹ thuật bao gồm:
Huấn Luyện Mô Hình: Mô hình học máy được huấn luyện trên tập dữ liệu đã gán nhãn. Mô hình học cách liên kết các đặc trưng với các danh mục tương ứng.
Đánh Giá Mô Hình: Hiệu suất của mô hình được đánh giá bằng các chỉ số như độ chính xác, độ thu hồi, độ chính xác và điểm F1. Cross-validation thường được sử dụng để đảm bảo khả năng tổng quát với dữ liệu chưa từng gặp. AWS nhấn mạnh tầm quan trọng của việc đánh giá hiệu suất phân loại văn bản để đảm bảo mô hình đạt độ chính xác và độ tin cậy mong muốn.
Dự Đoán và Triển Khai: Khi mô hình đã được kiểm định, có thể triển khai để phân loại các văn bản mới.
Phân loại văn bản được sử dụng rộng rãi trong nhiều lĩnh vực:
Phân Tích Cảm Xúc: Phát hiện cảm xúc thể hiện trong văn bản, thường dùng với phản hồi khách hàng và phân tích mạng xã hội để đánh giá ý kiến dư luận. Levity AI nhấn mạnh vai trò của phân loại văn bản trong social listening, giúp doanh nghiệp hiểu rõ cảm xúc đằng sau bình luận và phản hồi của khách hàng.
Phát Hiện Spam: Lọc các email không mong muốn hoặc có hại bằng cách phân loại chúng là spam hoặc hợp lệ. Việc lọc và gán nhãn tự động, như trong Gmail, là ví dụ điển hình về ứng dụng phân loại văn bản cho phát hiện spam.
Phân Loại Chủ Đề: Sắp xếp nội dung vào các chủ đề xác định trước, hữu ích cho bài báo, blog và tài liệu nghiên cứu. Ứng dụng này giúp đơn giản hóa việc quản lý và truy xuất nội dung, nâng cao trải nghiệm người dùng.
Phân Loại Phiếu Hỗ Trợ Khách Hàng: Tự động điều phối các phiếu hỗ trợ đến bộ phận phù hợp dựa trên nội dung. Quá trình tự động hóa này tăng hiệu quả xử lý yêu cầu khách hàng và giảm tải cho đội ngũ hỗ trợ.
Nhận Diện Ngôn Ngữ: Xác định ngôn ngữ của tài liệu văn bản cho các ứng dụng đa ngôn ngữ. Khả năng này rất cần thiết cho các doanh nghiệp hoạt động toàn cầu, phục vụ nhiều khu vực và ngôn ngữ khác nhau.
Phân loại văn bản cũng đối mặt với nhiều thách thức:
Chất Lượng và Số Lượng Dữ Liệu: Hiệu suất của mô hình phân loại văn bản phụ thuộc lớn vào chất lượng và số lượng dữ liệu huấn luyện. Dữ liệu không đủ hoặc nhiễu có thể làm giảm hiệu quả mô hình. AWS lưu ý rằng các tổ chức cần đảm bảo thu thập và gán nhãn dữ liệu chất lượng cao để đạt kết quả phân loại chính xác.
Lựa Chọn Đặc Trưng: Việc chọn các đặc trưng phù hợp là rất quan trọng cho độ chính xác của mô hình. Nếu huấn luyện trên các đặc trưng không liên quan, mô hình có thể bị quá khớp.
Khả Năng Giải Thích Mô Hình: Các mô hình học sâu, dù mạnh mẽ, thường hoạt động như các hộp đen, gây khó khăn trong việc giải thích quyết định. Sự thiếu minh bạch này có thể là rào cản trong một số ngành cần khả năng giải thích rõ ràng.
Khả Năng Mở Rộng: Khi khối lượng dữ liệu văn bản tăng lên, các mô hình cần mở rộng hiệu quả để xử lý tập dữ liệu lớn. Cần có các kỹ thuật xử lý và hạ tầng mở rộng để quản lý lượng dữ liệu ngày càng tăng.
Phân loại văn bản là thành phần trọng yếu của tự động hóa dựa trên AI và [chatbot. Bằng cách tự động phân loại và diễn giải các đầu vào văn bản, chatbot có thể đưa ra phản hồi phù hợp, nâng cao trải nghiệm khách hàng và tối ưu hóa quy trình kinh doanh. Trong tự động hóa AI, phân loại văn bản giúp hệ thống xử lý và phân tích khối lượng lớn dữ liệu với sự can thiệp tối thiểu của con người, nâng cao hiệu quả và khả năng ra quyết định.
Bên cạnh đó, những tiến bộ trong NLP và học sâu đã trang bị cho chatbot các năng lực phân loại văn bản tinh vi, cho phép hiểu ngữ cảnh, cảm xúc và ý định, từ đó mang lại tương tác cá nhân hóa và chính xác hơn với người dùng. AWS cho rằng tích hợp phân loại văn bản vào các ứng dụng AI có thể nâng cao đáng kể trải nghiệm của người dùng nhờ cung cấp thông tin kịp thời và phù hợp.
Nghiên Cứu Về Phân Loại Văn Bản
Phân loại văn bản là một nhiệm vụ then chốt trong xử lý ngôn ngữ tự nhiên, tự động gán nhãn cho văn bản theo các nhãn định trước. Dưới đây là tóm tắt các bài báo khoa học gần đây cung cấp cái nhìn về các phương pháp và thách thức trong phân loại văn bản:
Model and Evaluation: Towards Fairness in Multilingual Text Classification
Tác giả: Nankai Lin, Junheng He, Zhenghang Tang, Dong Zhou, Aimin Yang
Xuất bản: 2023-03-28
Bài báo này giải quyết thách thức về độ thiên lệch trong các mô hình phân loại văn bản đa ngôn ngữ. Nhóm tác giả đề xuất một khung loại bỏ thiên lệch dựa trên học tương phản mà không phụ thuộc vào nguồn lực ngôn ngữ bên ngoài. Khung này gồm các module biểu diễn văn bản đa ngôn ngữ, kết hợp ngôn ngữ, loại bỏ thiên lệch và phân loại. Ngoài ra, nhóm còn giới thiệu một khung đánh giá độ công bằng đa chiều mới, nhằm nâng cao độ công bằng giữa các ngôn ngữ. Công trình này có ý nghĩa trong việc cải thiện độ công bằng và chính xác của các mô hình phân loại văn bản đa ngôn ngữ. Đọc thêm
Text Classification using Association Rule with a Hybrid Concept of Naive Bayes Classifier and Genetic Algorithm
Tác giả: S. M. Kamruzzaman, Farhana Haider, Ahmed Ryadh Hasan
Xuất bản: 2010-09-25
Nghiên cứu này giới thiệu một phương pháp mới trong phân loại văn bản bằng cách kết hợp luật kết hợp với Naive Bayes và Thuật toán Di truyền. Phương pháp trích xuất đặc trưng từ các tài liệu đã phân loại thông qua mối quan hệ giữa các từ thay vì riêng lẻ từng từ. Sự kết hợp với thuật toán di truyền đã cải thiện hiệu quả phân loại cuối cùng. Kết quả cho thấy phương pháp lai này hiệu quả trong phân loại văn bản. Đọc thêm
Text Classification: A Perspective of Deep Learning Methods
Tác giả: Zhongwei Wan
Xuất bản: 2023-09-24
Trước sự bùng nổ dữ liệu internet, bài báo này nhấn mạnh tầm quan trọng của các phương pháp học sâu trong phân loại văn bản. Tác giả bàn về các kỹ thuật học sâu khác nhau giúp cải thiện độ chính xác và hiệu quả khi phân loại các văn bản phức tạp. Nghiên cứu nhấn mạnh vai trò ngày càng tăng của học sâu trong xử lý các tập dữ liệu lớn và mang lại kết quả phân loại chính xác. Đọc thêm
Phân loại văn bản là một nhiệm vụ của Xử lý Ngôn ngữ Tự nhiên (NLP) trong đó các danh mục được xác định trước được gán cho các tài liệu văn bản, cho phép tự động tổ chức, phân tích và diễn giải dữ liệu phi cấu trúc.
Các mô hình phổ biến gồm Máy Hỗ Trợ Vector (SVM), Naive Bayes, các mô hình học sâu như CNN và RNN, cùng các phương pháp dựa trên cây như Cây Quyết Định và Rừng Ngẫu Nhiên.
Phân loại văn bản được sử dụng rộng rãi trong phân tích cảm xúc, phát hiện spam, phân loại chủ đề, điều phối phiếu hỗ trợ khách hàng, và nhận diện ngôn ngữ.
Các thách thức bao gồm đảm bảo chất lượng và số lượng dữ liệu, lựa chọn đặc trưng phù hợp, khả năng giải thích của mô hình, và khả năng mở rộng để xử lý khối lượng dữ liệu lớn.
Phân loại văn bản cho phép tự động hóa dựa trên AI và chatbot diễn giải, phân loại và phản hồi các đầu vào của người dùng một cách hiệu quả, nâng cao tương tác khách hàng và quy trình kinh doanh.
Bắt đầu xây dựng chatbot thông minh và công cụ AI tận dụng phân loại văn bản tự động để tăng hiệu quả và độ sâu phân tích.
Tự động phân loại tự động hóa việc phân loại nội dung bằng cách phân tích các thuộc tính và gán thẻ nhờ các công nghệ như học máy, xử lý ngôn ngữ tự nhiên (NLP)...
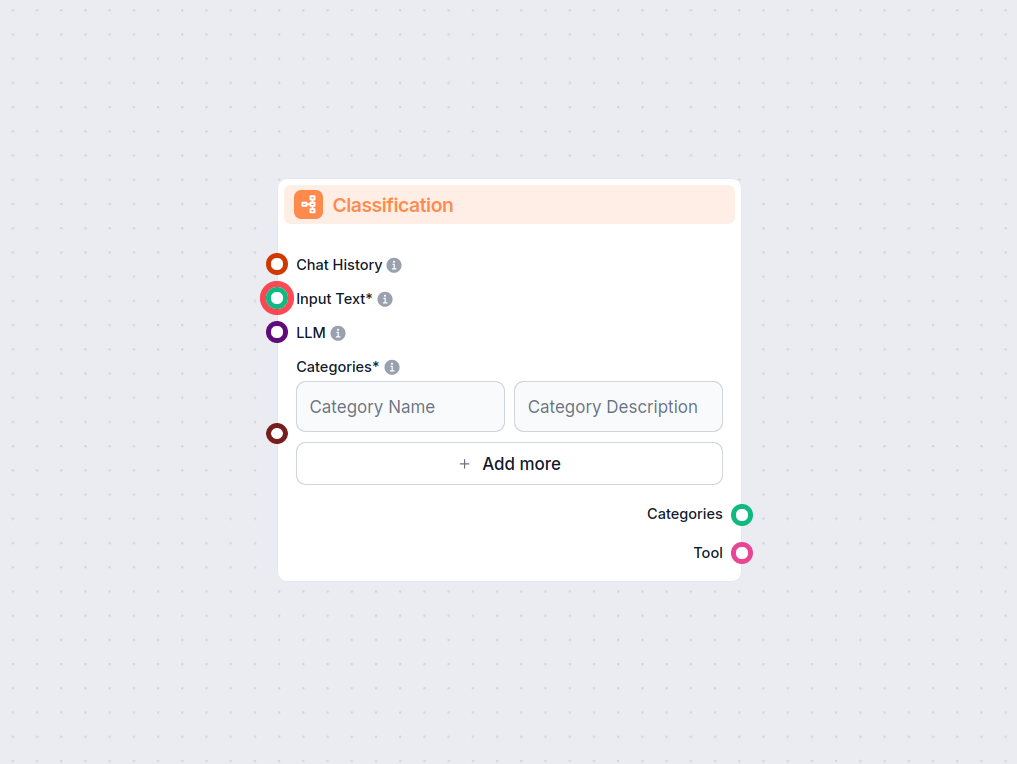
Mở khóa khả năng phân loại văn bản tự động trong quy trình làm việc của bạn với thành phần Phân Loại Văn Bản cho FlowHunt. Dễ dàng phân loại văn bản đầu vào vào...
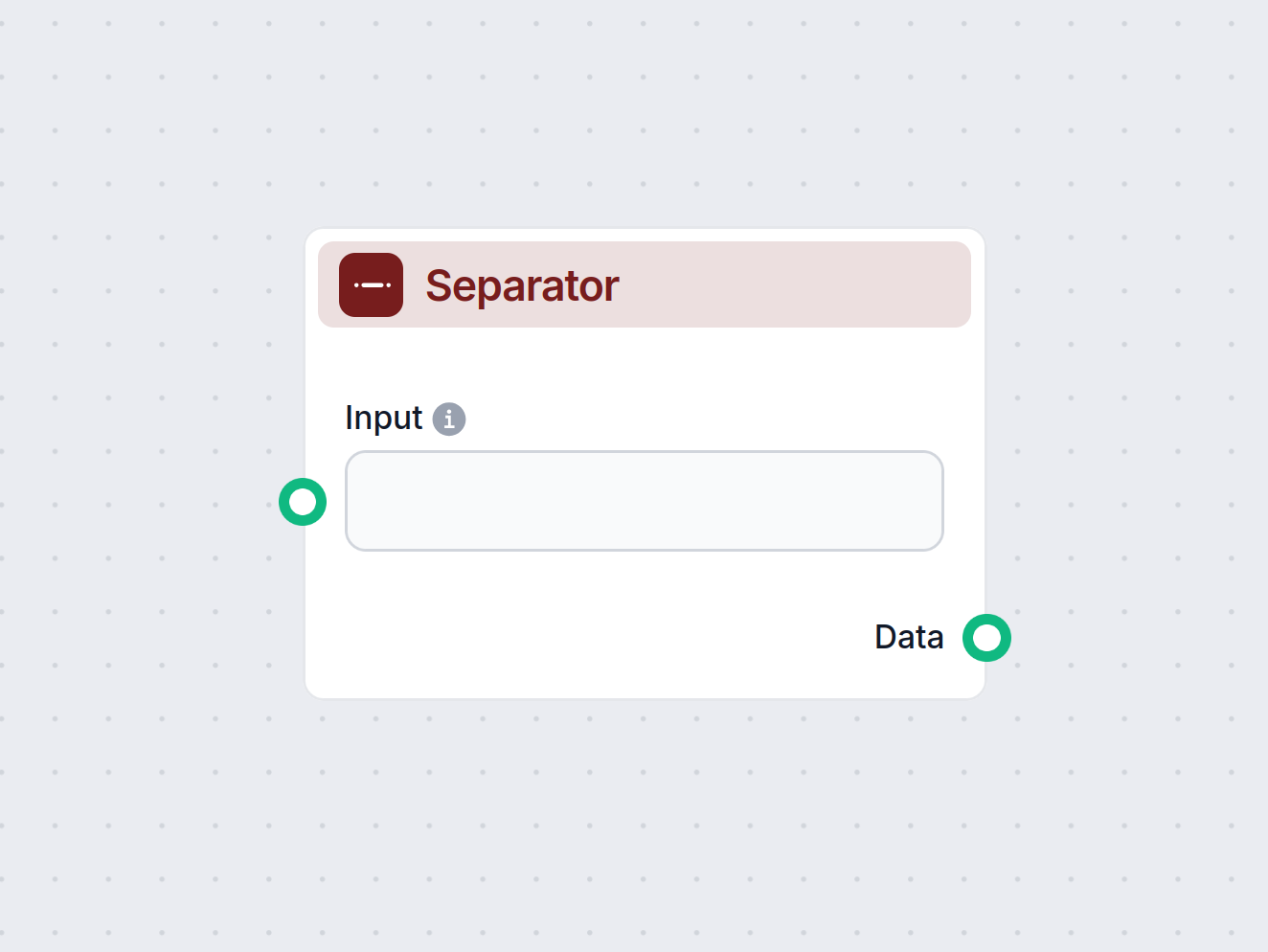
Thành phần Bộ phân tách chia nhỏ văn bản thuần thành danh sách các đoạn văn bản bằng dấu phân tách xác định. Nó rất cần thiết cho các quy trình làm việc yêu cầu...