Tích hợp Máy chủ MCP cho Neo4j
Máy chủ Neo4j MCP là cầu nối giữa trợ lý AI và cơ sở dữ liệu đồ thị Neo4j, cho phép thực hiện các thao tác đồ thị, truy vấn Cypher và quản lý dữ liệu tự động bằ...
6 phút đọc
AI
Graph Database
+5
Máy chủ Neo4j MCP là cầu nối giữa trợ lý AI và cơ sở dữ liệu đồ thị Neo4j, cho phép thực hiện các thao tác đồ thị, truy vấn Cypher và quản lý dữ liệu tự động bằ...
Máy chủ NASA MCP cung cấp một giao diện thống nhất cho các mô hình AI và nhà phát triển truy cập hơn 20 nguồn dữ liệu của NASA. Nó chuẩn hóa việc truy xuất, xử ...
Máy chủ MCP Code Executor MCP cho phép FlowHunt và các công cụ dựa trên LLM khác thực thi mã Python một cách an toàn trong các môi trường biệt lập, quản lý phụ ...
Máy chủ MCP Khám Phá Dữ Liệu kết nối các trợ lý AI với bộ dữ liệu bên ngoài để phân tích tương tác. Nó giúp người dùng khám phá các bộ dữ liệu CSV và Kaggle, tạ...
Reexpress MCP Server mang đến xác minh thống kê cho quy trình làm việc LLM. Sử dụng bộ ước lượng Similarity-Distance-Magnitude (SDM), nó cung cấp ước lượng độ t...
Máy chủ Databricks Genie MCP cho phép các mô hình ngôn ngữ lớn tương tác với môi trường Databricks thông qua API Genie, hỗ trợ khám phá dữ liệu hội thoại, tự độ...
JupyterMCP cho phép tích hợp liền mạch Jupyter Notebook (6.x) với các trợ lý AI thông qua Giao Thức Mô Hình Ngữ Cảnh (Model Context Protocol). Tự động hóa thực ...
BigML là một nền tảng học máy được thiết kế nhằm đơn giản hóa việc tạo và triển khai các mô hình dự đoán. Được thành lập vào năm 2011, sứ mệnh của BigML là giúp...
Bộ phân loại AI là một thuật toán học máy gán nhãn lớp cho dữ liệu đầu vào, phân loại thông tin vào các lớp đã được xác định trước dựa trên các mẫu đã học từ dữ...
Cây quyết định là một công cụ mạnh mẽ và trực quan để ra quyết định và phân tích dự đoán, được sử dụng trong cả bài toán phân loại và hồi quy. Cấu trúc dạng cây...
Chuỗi Mô Hình là một kỹ thuật học máy trong đó nhiều mô hình được liên kết tuần tự, với đầu ra của mỗi mô hình trở thành đầu vào của mô hình tiếp theo. Phương p...
Chuyên viên Phân tích Dữ liệu AI kết hợp kỹ năng phân tích dữ liệu truyền thống với trí tuệ nhân tạo (AI) và học máy (ML) để khai thác thông tin, dự đoán xu hướ...
Diện Tích Dưới Đường Cong (AUC) là một chỉ số quan trọng trong học máy dùng để đánh giá hiệu quả của các mô hình phân loại nhị phân. AUC định lượng khả năng tổn...
Giảm số chiều là một kỹ thuật then chốt trong xử lý dữ liệu và học máy, giúp giảm số lượng biến đầu vào trong một bộ dữ liệu đồng thời vẫn giữ được thông tin th...
Google Colaboratory (Google Colab) là một nền tảng Jupyter notebook dựa trên đám mây của Google, cho phép người dùng viết và thực thi mã Python ngay trên trình ...
Gradient Boosting là một kỹ thuật học máy mạnh mẽ dùng để tổng hợp các mô hình dự đoán cho bài toán hồi quy và phân loại. Phương pháp này xây dựng các mô hình m...
Hệ số R bình phương hiệu chỉnh là một thước đo thống kê được sử dụng để đánh giá mức độ phù hợp của mô hình hồi quy, có tính đến số lượng biến dự báo nhằm tránh...
Học bán giám sát (SSL) là một kỹ thuật học máy tận dụng cả dữ liệu đã gán nhãn và chưa gán nhãn để huấn luyện mô hình, lý tưởng khi việc gán nhãn toàn bộ dữ liệ...
Hồi quy tuyến tính là một kỹ thuật phân tích nền tảng trong thống kê và học máy, mô hình hóa mối quan hệ giữa biến phụ thuộc và các biến độc lập. Nổi tiếng với ...
Jupyter Notebook là một ứng dụng web mã nguồn mở cho phép người dùng tạo và chia sẻ tài liệu với mã nguồn trực tiếp, phương trình, trực quan hóa và văn bản thuy...
Thuật toán k-láng giềng gần nhất (KNN) là một thuật toán học máy có giám sát, không tham số, được sử dụng cho các bài toán phân loại và hồi quy trong học máy. T...
Kaggle là một cộng đồng trực tuyến và nền tảng dành cho các nhà khoa học dữ liệu và kỹ sư học máy hợp tác, học hỏi, thi đấu và chia sẻ kiến thức. Được Google mu...
Khai phá dữ liệu là một quá trình tinh vi để phân tích các tập dữ liệu thô lớn nhằm khám phá ra các mẫu, mối quan hệ và nhận định giúp định hướng chiến lược kin...
Khám phá cách Kỹ Thuật và Trích Xuất Đặc Trưng nâng cao hiệu suất mô hình AI bằng cách chuyển đổi dữ liệu thô thành những thông tin giá trị. Tìm hiểu các kỹ thu...
Làm sạch dữ liệu là quá trình quan trọng nhằm phát hiện và sửa các lỗi hoặc sự không nhất quán trong dữ liệu để nâng cao chất lượng, đảm bảo độ chính xác, tính ...
Mô hình dự báo là một quy trình tinh vi trong khoa học dữ liệu và thống kê nhằm dự đoán kết quả tương lai bằng cách phân tích các mẫu dữ liệu lịch sử. Nó sử dụn...
NumPy là một thư viện Python mã nguồn mở quan trọng cho tính toán số, cung cấp các thao tác mảng hiệu quả và các hàm toán học. Nó là nền tảng cho tính toán khoa...
Pandas là một thư viện mã nguồn mở dùng để thao tác và phân tích dữ liệu cho Python, nổi tiếng với tính linh hoạt, cấu trúc dữ liệu mạnh mẽ và dễ sử dụng khi xử...
Phân cụm K-Means là một thuật toán học máy không giám sát phổ biến dùng để phân chia tập dữ liệu thành một số cụm xác định trước, riêng biệt, không chồng lấn bằ...
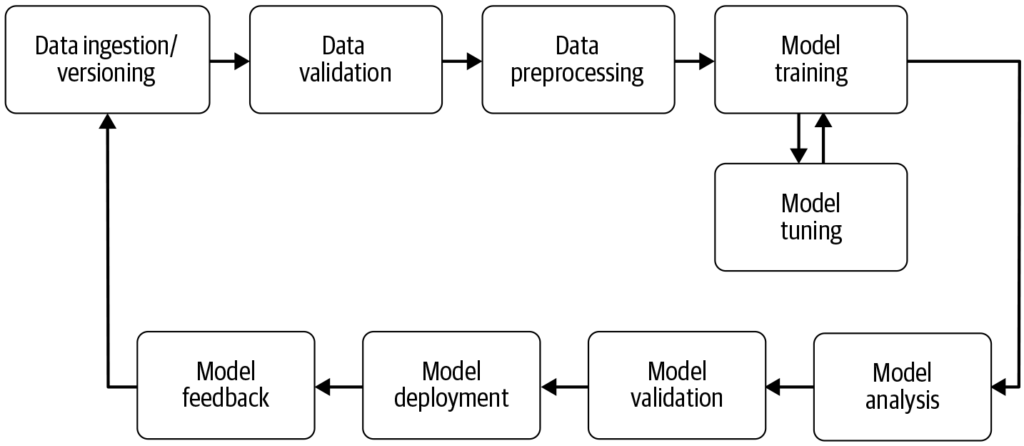
Quy trình máy học là một quy trình làm việc tự động giúp hợp lý hóa và chuẩn hóa việc phát triển, huấn luyện, đánh giá và triển khai các mô hình máy học, chuyển...
Scikit-learn là một thư viện mã nguồn mở mạnh mẽ về học máy cho Python, cung cấp các công cụ đơn giản và hiệu quả cho phân tích dữ liệu dự đoán. Được sử dụng rộ...
Suy luận nhân quả là một phương pháp luận dùng để xác định các mối quan hệ nhân quả giữa các biến số, đóng vai trò quan trọng trong khoa học nhằm hiểu rõ các cơ...
Khám phá thiên vị trong AI: hiểu nguồn gốc, tác động đến học máy, ví dụ thực tế và các chiến lược giảm thiểu để xây dựng hệ thống AI công bằng và đáng tin cậy....
Anaconda là một bản phân phối mã nguồn mở toàn diện của Python và R, được thiết kế để đơn giản hóa việc quản lý gói và triển khai cho tính toán khoa học, khoa h...
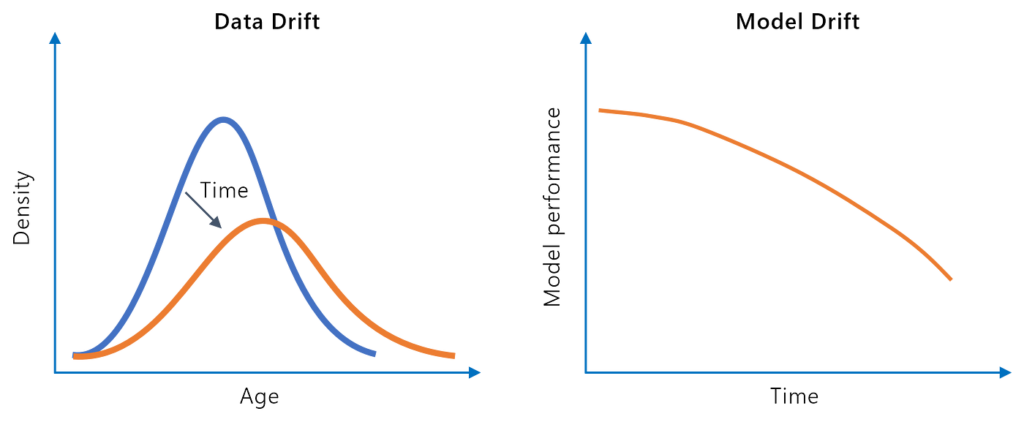
Trôi dạt mô hình, hay còn gọi là suy giảm mô hình, đề cập đến sự suy giảm hiệu suất dự đoán của mô hình học máy theo thời gian do những thay đổi trong môi trườn...