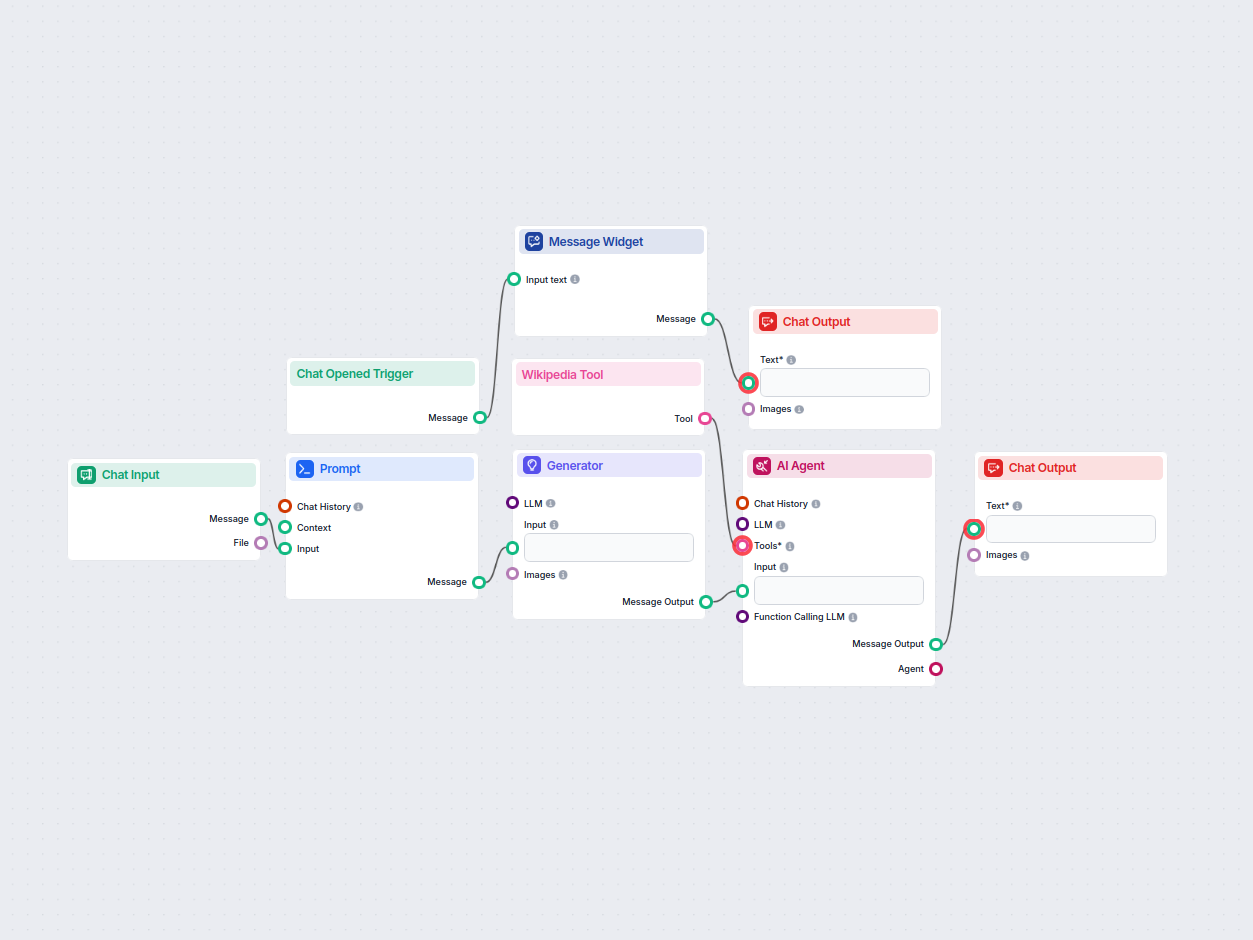

提示词
创建初始 LLM 提示词,用于生成带有虚拟数据和来源指示的样例答案,便于后续完善。引导 LLM 明确指定每个部分应使用的来源。...
Gived is user's query. Based on the User's query generate best possible answer with fake data or percentage. After each of different sections of your answer, include data which source to use in order to fetch the correct data and refine that section with correct data. you can either specify to choose Internal knowledge source to fetch data from in case there is custom data to user's product or service or use wikipedia to use as general knowledge source.
---
Example Input: Which countries are top in terms of renewable energy and what is the best metric for measuring this and what is that measure for top country?
Example output: The top countries in renewable energy are Norway, Sweden, Portugal, USA [Search in Wikipedia with query "Top Countries in renewable Energy"], the usual metric for renewable energy is Capacity factor [Search in Wikipedia with query "metric for renewable energy"] and number one country has 20% capacity factor [search in Wikipedia "biggest capacity factor"]
---
Let's begin now!
User Input: {input} 

