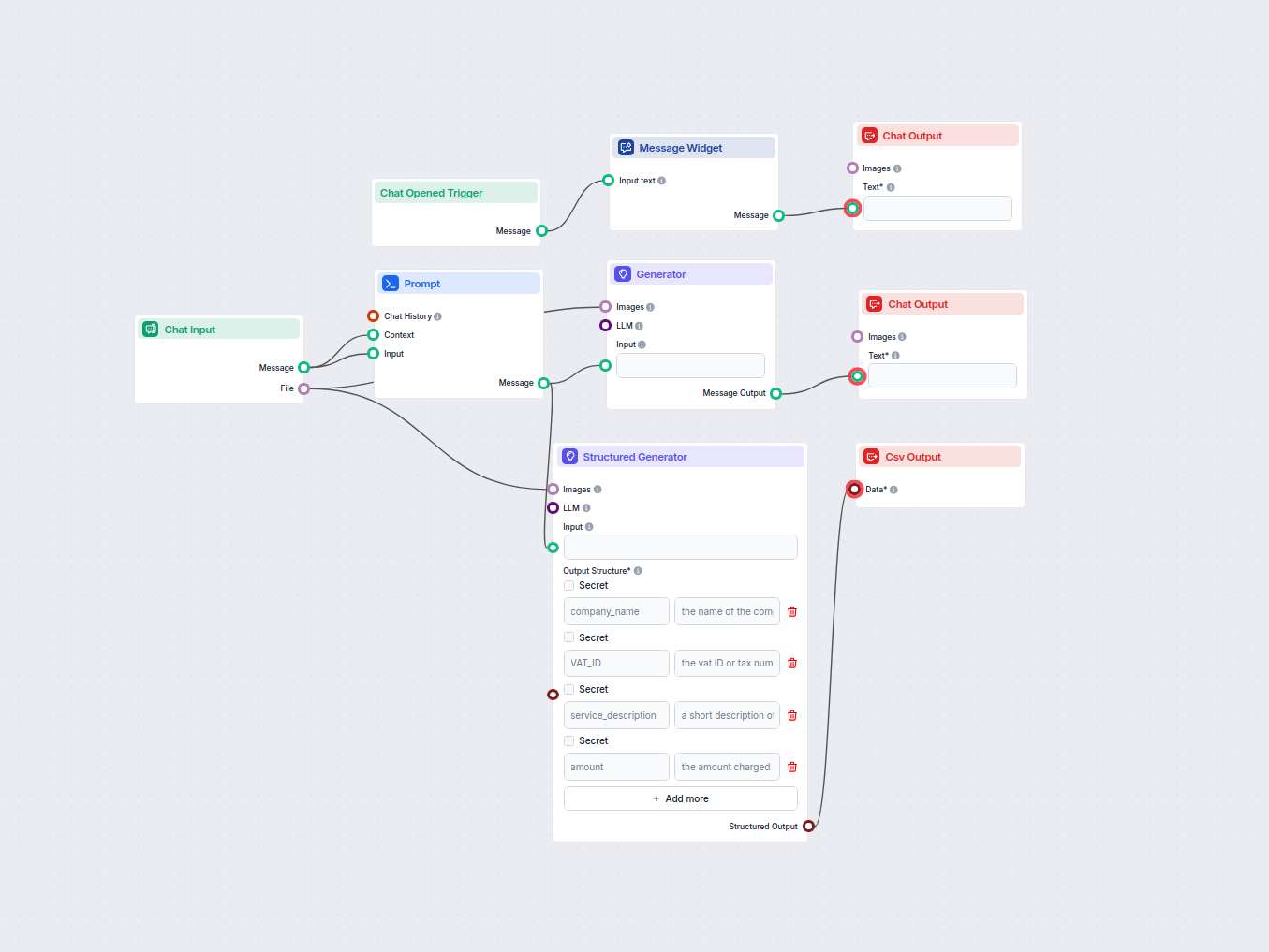
发票数据提取器
了解发票数据提取器OCR流程如何通过自动化提取和整理发票数据来优化您的财务流程。了解其功能、优势,以及它如何提升各类企业的效率与准确性。更多精彩内容尽在FlowHunt。...
1 分钟阅读
OCR
Invoice Automation
+3

学习如何结合FlowHunt API,使用基于AI的OCR与Python自动提取发票数据,实现快速、准确且可扩展的文档处理。
AI驱动的OCR超越了传统OCR的能力,它利用人工智能理解文档上下文,能处理多种布局类型,即使是最复杂的文档也能高质量提取结构化数据。传统OCR只能处理固定格式文本,而AI OCR则适用于发票及各类商业文档中常见的多种布局和配置。
无论是财务、物流还是采购部门,发票都需高效且高精度地处理。AI OCR自动提取数据,优化流程,提高数据准确性。
大多数传统企业仍通过人工方式手动从发票中提取数据,这既耗时又成本高。税务、法律、金融等众多领域和公司都可以自动化这项工作。
该流程仅需5到15秒,费用为0.01–0.02积分,而人工处理同样任务的时薪通常为$15–$30。
| 处理方式 | 年成本 | 年处理发票数量 | 单张发票成本 |
|---|---|---|---|
| 人工 | $30,000 | 12,000 | $2.50 |
| FlowHunt | $162 | 12,000 | $0.013 |
| FlowHunt($30,000预算) | $30,000 | 2,250,000 | $0.0133 |
可以说,FlowHunt的效率高出极大幅度。
虽然OCR非常有用,但也面临一些挑战:
为应对这些挑战,必须选用强大灵活的OCR工具。FlowHunt API可处理复杂文档结构,是大规模OCR项目的理想选择。
为了自动化流程,需安装以下Python库:
pip install requests pdf2image git+https://github.com/QualityUnit/flowhunt-python-sdk.git
该命令会安装:
本代码会将PDF转为图片,逐页发送至FlowHunt进行OCR处理,并将结果保存为CSV。
导入依赖库
import json
import os
import re
import time
import requests
import flowhunt
from flowhunt.rest import ApiException
from pprint import pprint
from pdf2image import convert_from_path
json、os、re、time 负责JSON处理、文件管理、正则表达式和时间间隔。requests:用于处理HTTP请求,如下载OCR结果。flowhunt:FlowHunt SDK,用于鉴权及与OCR API通信。pdf2image:将PDF每页转为图片,便于逐页OCR。PDF转图片函数
def convert_pdf_to_image(path: str) -> None:
"""
Convert a PDF file to images, storing each page as a JPEG.
"""
images = convert_from_path(path)
for i in range(len(images)):
images[i].save('data/images/' + 'page' + str(i) + '.jpg', 'JPEG')
convert_from_path:将PDF每页转为一张图片。images[i].save:保存每页为独立JPEG图片,便于后续OCR。提取OCR输出文件URL的函数
def extract_attachment_url(data_string):
pattern = r'```flowhunt\n({.*})\n```'
match = re.search(pattern, data_string, re.DOTALL)
if match:
json_string = match.group(1)
try:
json_data = json.loads(json_string)
return json_data.get('download_link', None)
except json.JSONDecodeError:
print("Error: Failed to decode JSON.")
return None
return None
API配置及鉴权
convert_pdf_to_image("data/test.pdf")
FLOW_ID = "<FLOW_ID_HERE>"
configuration = flowhunt.Configuration(
host="https://api.flowhunt.io",
api_key={"APIKeyHeader": "<API_KEY_HERE>"}
)
初始化API客户端
with flowhunt.ApiClient(configuration) as api_client:
auth_api = flowhunt.AuthApi(api_client)
api_response = auth_api.get_user()
workspace_id = api_response.api_key_workspace_id
workspace_id,后续API调用需用到。启动流程会话(Flow Session)
flows_api = flowhunt.FlowsApi(api_client)
from_flow_create_session_req = flowhunt.FlowSessionCreateFromFlowRequest(flow_id=FLOW_ID)
create_session_rsp = flows_api.create_flow_session(workspace_id, from_flow_create_session_req)
上传图片进行OCR处理
for image in os.listdir("data/images"):
image_name, image_extension = os.path.splitext(image)
with open("data/images/" + image, "rb") as file:
try:
flow_sess_attachment = flows_api.upload_attachments(
create_session_rsp.session_id,
file.read()
)
触发OCR处理并轮询结果
invoke_rsp = flows_api.invoke_flow_response(
create_session_rsp.session_id,
flowhunt.FlowSessionInvokeRequest(message="")
)
while True:
get_flow_rsp = flows_api.poll_flow_response(
create_session_rsp.session_id, invoke_rsp.message_id
)
print("Flow response: ", get_flow_rsp)
if get_flow_rsp.response_status == "S":
print("done OCR")
break
time.sleep(3)
下载并保存OCR输出
attachment_url = extract_attachment_url(get_flow_rsp.final_response[0])
if attachment_url:
response = requests.get(attachment_url)
with open("data/results/" + image_name + ".csv", "wb") as file:
file.write(response.content)
执行流程如下:
data/文件夹。<FLOW_ID_HERE>和<API_KEY_HERE>。本Python脚本为大规模OCR流程提供高效解决方案,适用于高文档处理需求的行业。结合FlowHunt API,轻松实现文档到CSV的转换,优化流程、提升生产力。
import json
import os
import re
import time
import requests
import flowhunt
from flowhunt.rest import ApiException
from pprint import pprint
from pdf2image import convert_from_path
def convert_pdf_to_image(path: str) -> None:
"""
Convert a pdf file to an image
:return:
"""
images = convert_from_path(path)
for i in range(len(images)):
images[i].save('data/images/' + 'page'+ str(i) +'.jpg', 'JPEG')
def extract_attachment_url(data_string):
pattern = r'```flowhunt\n({.*})\n```'
match = re.search(pattern, data_string, re.DOTALL)
if match:
json_string = match.group(1)
try:
json_data = json.loads(json_string)
return json_data.get('download_link', None)
except json.JSONDecodeError:
print("Error: Failed to decode JSON.")
return None
return None
convert_pdf_to_image("data/test.pdf")
FLOW_ID = "<FLOW_ID_HERE>"
configuration = flowhunt.Configuration(host = "https://api.flowhunt.io",
api_key = {"APIKeyHeader": "<API_KEY_HERE>"})
with flowhunt.ApiClient(configuration) as api_client:
auth_api = flowhunt.AuthApi(api_client)
api_response = auth_api.get_user()
workspace_id = api_response.api_key_workspace_id
flows_api = flowhunt.FlowsApi(api_client)
from_flow_create_session_req = flowhunt.FlowSessionCreateFromFlowRequest(
flow_id=FLOW_ID
)
create_session_rsp = flows_api.create_flow_session(workspace_id, from_flow_create_session_req)
for image in os.listdir("data/images"):
image_name, image_extension = os.path.splitext(image)
with open("data/images/" + image, "rb") as file:
try:
flow_sess_attachment = flows_api.upload_attachments(
create_session_rsp.session_id,
file.read()
)
invoke_rsp = flows_api.invoke_flow_response(create_session_rsp.session_id, flowhunt.FlowSessionInvokeRequest(
message="",
))
while True:
get_flow_rsp = flows_api.poll_flow_response(create_session_rsp.session_id, invoke_rsp.message_id)
print("Flow response: ", get_flow_rsp)
if get_flow_rsp.response_status == "S":
print("done OCR")
attachment_url = extract_attachment_url(get_flow_rsp.final_response[0])
if attachment_url:
print("Attachment URL: ", attachment_url, "\n Downloading the file...")
response = requests.get(attachment_url)
with open("data/results/" + image_name + ".csv", "wb") as file:
file.write(response.content)
break
time.sleep(3)
except ApiException as e:
print("error for file ", image)
print(e)
基于AI的OCR利用机器学习和自然语言处理理解文档上下文,处理复杂布局,从发票中提取结构化数据;而传统OCR依赖固定格式识别文本。
AI OCR具备速度快、准确率高、易扩展并能输出结构化数据的优势,减少人工操作和错误,实现与企业系统的无缝集成。
通过使用FlowHunt的Python SDK,可将PDF转为图片,发送至API进行OCR并获取CSV格式的结构化数据,实现全流程自动化提取。
常见挑战包括图像质量差、文档布局复杂、语言多样等。FlowHunt API通过先进AI模型和灵活处理能力,有效应对这些问题。
FlowHunt的AI OCR能以极低的人力成本在数秒内处理发票,大幅提升效率,实现企业大规模扩展。
阿尔西亚是 FlowHunt 的一名 AI 工作流程工程师。拥有计算机科学背景并热衷于人工智能,他专注于创建高效的工作流程,将 AI 工具整合到日常任务中,从而提升生产力和创造力。
了解发票数据提取器OCR流程如何通过自动化提取和整理发票数据来优化您的财务流程。了解其功能、优势,以及它如何提升各类企业的效率与准确性。更多精彩内容尽在FlowHunt。...
通过上传发票图片并提取关键发票数据(如发票号码、类型、语言、项目、价格和总金额)来实现发票处理自动化。结果以markdown表格和结构化CSV文件输出,助力高效的财务工作流程。...
了解由AI驱动的OCR如何变革数据提取,自动化文档处理,并在金融、医疗和零售等行业提升效率。探索OCR的发展历程、实际应用案例,以及OpenAI Sora等前沿解决方案。...