

FlowHunt 2.4.1 引入 Claude、Grok、Llama 等全新模型
FlowHunt 2.4.1 推出了多项全新 AI 模型,包括 Claude、Grok、Llama、Mistral、DALL-E 3 和 Stable Diffusion,为您的 AI 项目带来更多实验、创意和自动化的选择。...
1 分钟阅读
AI
LLM
+7

FlowHunt 全新的开源 CLI 工具包实现了以大语言模型为评审的全流程评估,支持详细报告及 AI 工作流自动化质量检测。
我们非常高兴地宣布推出 FlowHunt CLI 工具包 —— 这是一款全新的开源命令行工具,旨在彻底改变开发者评估和测试 AI 流程的方式。这款强大的工具包将企业级流程评估能力带入开源社区,集成了高级报告和创新的“大语言模型担任评审”功能。
FlowHunt CLI 工具包是 AI 工作流测试与评估领域的重要进步。现已在 GitHub 开源,面向开发者提供全方位的开发利器:
该工具包展现了我们对透明化和社区共建的承诺,让先进的 AI 评估技术惠及全球开发者。
CLI 工具包最具创新性的功能之一,就是“大语言模型担任评审”。这种方式利用人工智能对 AI 生成的响应质量和正确性进行评判——让 AI 以强大的推理能力评判 AI 的表现。
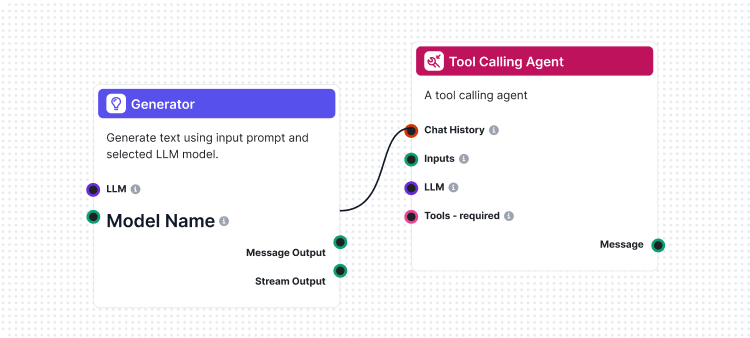
我们的实现独特之处在于,评审流本身也是用 FlowHunt 构建的。这种“元”方法不仅展示了平台的强大和灵活性,也带来了坚实可靠的评估系统。大语言模型评审流包含若干相互联结的组件:
1. 提示模板:根据特定标准生成评估提示
2. 结构化输出生成器:用 LLM 处理评估
3. 数据解析器:为报告格式化结构化输出
4. 聊天输出:呈现最终评估结果
我们的“大语言模型担任评审”体系核心是精心设计的提示词,确保评估一致且可靠。以下是我们使用的核心提示模板:
You will be given an ANSWER and REFERENCE couple.
Your task is to provide the following:
1. a 'total_rating' scoring: how close is the ANSWER to the REFERENCE
2. a binary label 'correctness' which can be either 'correct' or 'incorrect', which defines if the ANSWER is correct or not
3. and 'reasoning', which describes the reason behind your choice of scoring and correctness/incorrectness of ANSWER
An ANSWER is correct when it is the same as the REFERENCE in all facts and details, even if worded differently. the ANSWER is incorrect if it contradicts the REFERENCE, changes or omits details. its ok if the ANSWER has more details comparing to REFERENCE.
'total rating' is a scale of 1 to 4, where 1 means that the ANSWER is not the same as REFERENCE at all, and 4 means that the ANSWER is the same as the REFERENCE in all facts and details even if worded differently.
Here is the scale you should use to build your answer:
1: The ANSWER is contradicts the REFERENCE completely, adds additional claims, changes or omits details
2: The ANSWER points to the same topic but the details are omitted or changed completely comparing to REFERENCE
3: The ANSWER's references are not completely correct, but the details are somewhat close to the details mentioned in the REFERENCE. its ok, if there are added details in ANSWER comparing to REFERENCES.
4: The ANSWER is the same as the REFERENCE in all facts and details, even if worded differently. its ok, if there are added details in ANSWER comparing to REFERENCES. if there are sources available in REFERENCE, its exactly the same as ANSWER and is for sure mentioned in ANSWER
REFERENCE
===
{target_response}
===
ANSWER
===
{actual_response}
===
该提示词确保我们的 LLM 评审员能够:
“大语言模型担任评审”流程展示了 FlowHunt 可视化流程构建器的强大设计能力。其各组件协同如下:
流程以 聊天输入 组件开始,接收包含实际响应和参考答案的评估请求。
提示模板 组件动态构建评估提示词:
{target_response} 占位符{actual_response} 占位符结构化输出生成器 用选定的 LLM 处理提示词,生成结构化输出,包括:
total_rating:1-4 的数值评分correctness:正误二元分类reasoning:详细评估解释数据解析 组件将结构化输出格式化为可读内容,聊天输出 组件则呈现最终评估结果。
“大语言模型担任评审”系统具备多项先进能力,使其在 AI 流程评估中独具优势:
相比简单的字符串比对,我们的 LLM 评审员能够理解:
四分制评分体系实现细致评估:
每次评估都包含详细理由,便于:
CLI 工具包可生成详尽的报告,助力流程改进:
准备好用专业工具评估你的 AI 流程了吗?速览如下:
一行命令安装(推荐,支持 macOS 和 Linux):
curl -sSL https://raw.githubusercontent.com/yasha-dev1/flowhunt-toolkit/main/install.sh | bash
此命令将自动:
flowhunt 命令加入 PATH手动安装:
# 克隆仓库
git clone https://github.com/yasha-dev1/flowhunt-toolkit.git
cd flowhunt-toolkit
# 用 pip 安装
pip install -e .
验证安装:
flowhunt --help
flowhunt --version
1. 认证登录 首先用 FlowHunt API 认证身份:
flowhunt auth
2. 列出你的流程
flowhunt flows list
3. 评估某个流程 准备测试数据 CSV 文件:
flow_input,expected_output
"What is 2+2?","4"
"What is the capital of France?","Paris"
调用大语言模型评审流进行评估:
flowhunt evaluate your-flow-id path/to/test-data.csv --judge-flow-id your-judge-flow-id
4. 批量执行流程
flowhunt batch-run your-flow-id input.csv --output-dir results/
评估系统支持全面分析:
flowhunt evaluate FLOW_ID TEST_DATA.csv \
--judge-flow-id JUDGE_FLOW_ID \
--output-dir eval_results/ \
--batch-size 10 \
--verbose
功能包括:
CLI 工具包可无缝集成 FlowHunt 平台,实现:
CLI 工具包的发布不仅仅是一个新工具,更代表了 AI 开发未来的愿景:
质量可衡量:先进评估技术让 AI 表现可量化、可对比。
测试自动化:完善的测试框架降低人工成本,提升可靠性。
透明标准化:详尽理由与报告让 AI 行为可理解、可调试。
社区驱动创新:开源工具推动协作进步与知识共享。
开源 FlowHunt CLI 工具包,体现了我们的承诺:
FlowHunt CLI 工具包及“大语言模型担任评审”功能是 AI 流程评估领域的重要突破。它结合了先进的评估逻辑、全面的报告系统与开源易用性,助力开发者构建更优质、更可靠的 AI 系统。
用 FlowHunt 评估 FlowHunt 流程的“元”方案,展现了平台的成熟与灵活,也为更广泛的 AI 开发社区提供了强大工具。
无论你在开发简单聊天机器人还是复杂多智能体系统,FlowHunt CLI 工具包都能为你的流程评估保驾护航,实现质量、可靠性和持续优化。
准备好提升你的 AI 流程评估了吗? 访问我们的 GitHub 仓库,立即体验 FlowHunt CLI 工具包,亲身感受大语言模型担任评审的强大。
AI 开发的未来已来——而且是开源的。
FlowHunt CLI 工具包是一款开源命令行工具,用于对 AI 流程进行评估并生成详尽报告。其功能包括:大语言模型担任评审、正误结果分析及详细性能指标。
大语言模型担任评审,利用 FlowHunt 内部构建的智能流程对其它流程进行评估。它将实际响应与参考答案进行比对,给出评分、正误判定及详细理由。
FlowHunt CLI 工具包是开源的,可在 GitHub(https://github.com/yasha-dev1/flowhunt-toolkit)获取。你可以自由克隆、贡献及用于 AI 流程评估需求。
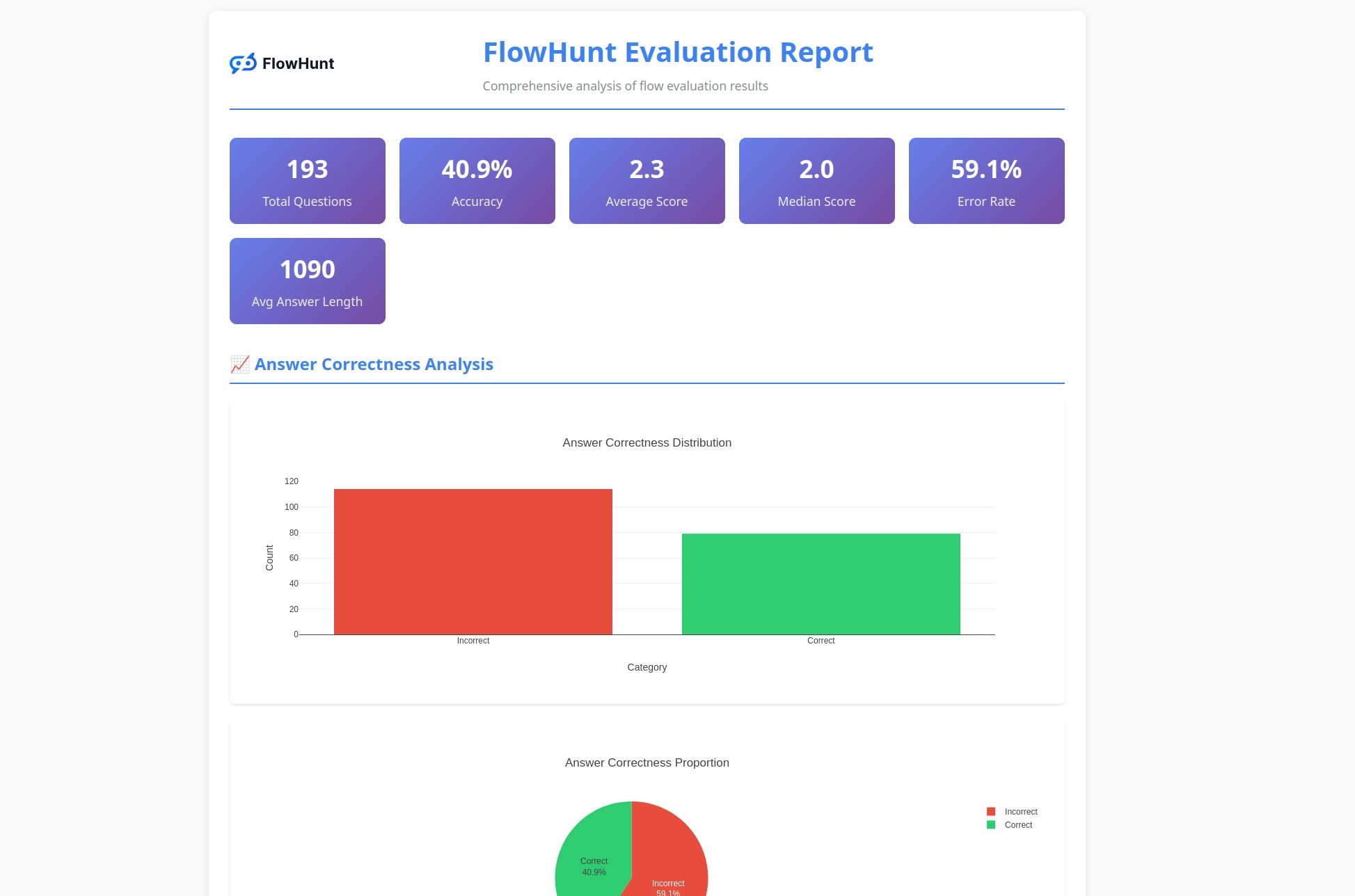
该工具包会生成全面的报告,包括正误结果分布、大语言模型评审评分与理由、性能指标,以及针对不同测试用例的流程行为详细分析。
可以!大语言模型评审流是基于 FlowHunt 平台构建的,可灵活适配各种评估场景。你可以根据自身需求修改提示模板和评估标准。
Yasha 是一位才华横溢的软件开发者,专攻 Python、Java 以及机器学习。Yasha 撰写关于人工智能、提示工程和聊天机器人开发的技术文章。
FlowHunt 2.4.1 推出了多项全新 AI 模型,包括 Claude、Grok、Llama、Mistral、DALL-E 3 和 Stable Diffusion,为您的 AI 项目带来更多实验、创意和自动化的选择。...
FlowHunt 2.6.12引入了Slack集成、意图分类和Gemini模型,增强了AI聊天机器人的功能、客户洞察和团队工作流程。
在 FlowHunt 中,流程是一切的核心。了解如何通过零代码可视化搭建器从放置第一个组件到网站集成、部署聊天机器人,以及利用预制模板来构建流程。...