

Gemini 2.0 Flash-Lite:谷歌最新AI速度与能力的结合
了解谷歌Gemini 2.0 Flash-Lite在内容创作、计算、摘要和创意任务等方面的表现。我们的深入分析揭示了该AI模型在速度与能力之间的卓越平衡,并为开发者和企业用户提供了实用见解。...
1 分钟阅读
AI
Google
+5

对 Google 实验性 AI 模型 Gemini 2.0 Thinking 的全面评估,聚焦其性能、推理透明性,以及在各类核心任务中的实际应用。
我们的评测方法涵盖了对 Gemini 2.0 Thinking 在五类代表性任务上的测试:
每项任务我们都衡量了:
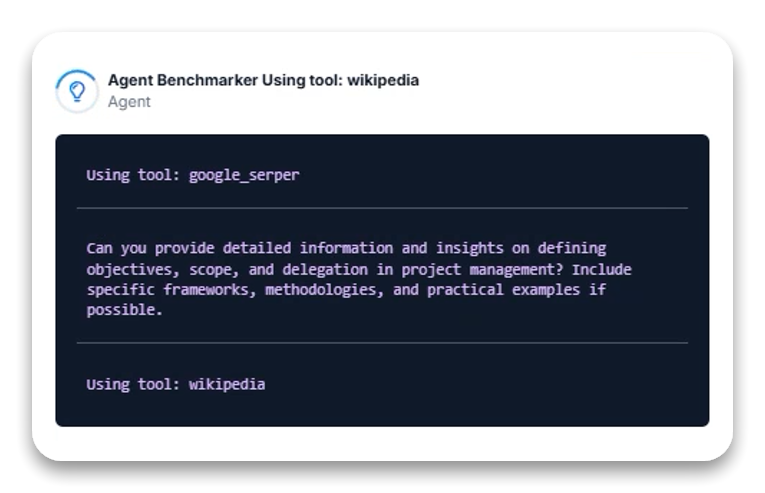
任务描述: 生成一篇关于项目管理基础的综合性文章,重点阐述目标、范围和分工的定义。
性能分析:
Gemini 2.0 Thinking 的可见推理过程颇具亮点。模型展现了系统化的多阶段调研与综合方法,涵盖两种任务变体:
信息处理优势:
效率指标:
性能评分: 9/10
内容生成表现获得高分,因其能够:
Thinking 版本的主要优势在于其调研过程的可视化,明确展示每一步使用的工具,但显性推理语句的展现仍不够一致。
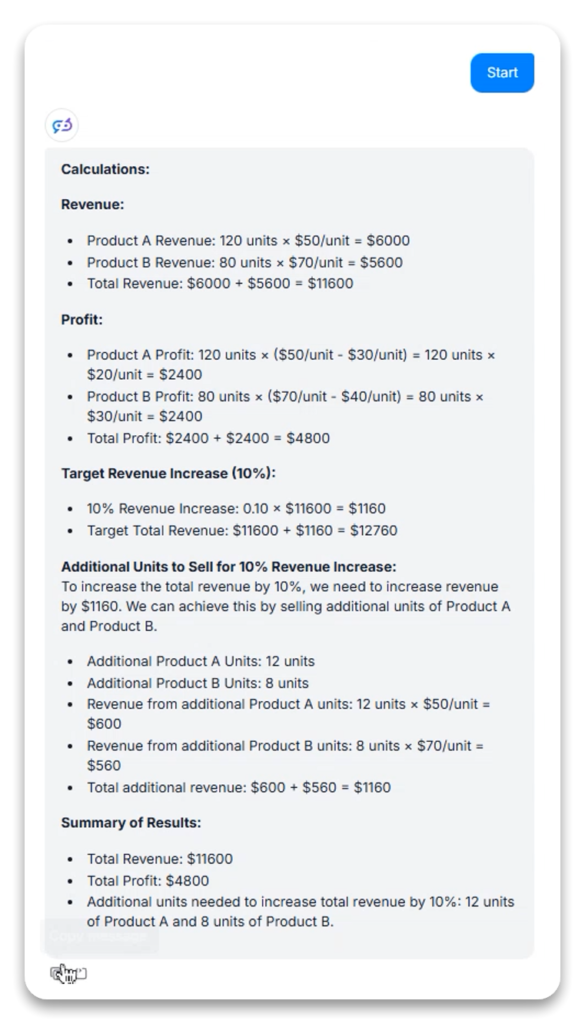
任务描述: 解决一个涉及营收、利润和优化的多部分商业计算问题。
性能分析:
在两种变体下,模型展现了强大的数学推理能力:
数学处理优势:
效率指标:
性能评分: 9.5/10
计算表现获得极高评价,基于以下原因:
“Thinking”能力在第一变体尤为突出,模型明确列示了假设与优化策略,展现了标准模型所不具备的决策透明性。
任务描述: 用100字总结一篇关于 AI 推理的文章要点。
性能分析:
模型在两种变体下均展现了卓越的文本摘要效率:
摘要优势:
效率指标:
性能评分: 10/10
摘要表现获得满分,因其:
有趣的是,本任务中“Thinking”功能未显示显性推理,暗示模型针对不同任务可能采用不同的认知路径,摘要处理可能更为直觉化而非逐步推理。
任务描述: 从多维度对比电动车与氢燃料车的环境影响。
性能分析:
模型在两种变体下表现出不同的信息处理方式,处理时间和来源利用均有明显差异:
对比分析优势:
信息处理差异:
性能评分: 8.5/10
对比任务表现获高分,因其:
“Thinking”能力体现在工具使用记录中,模型先广泛检索后精准爬取,展现了信息采集的顺序与透明性,有助于用户理解对比结论的来源。
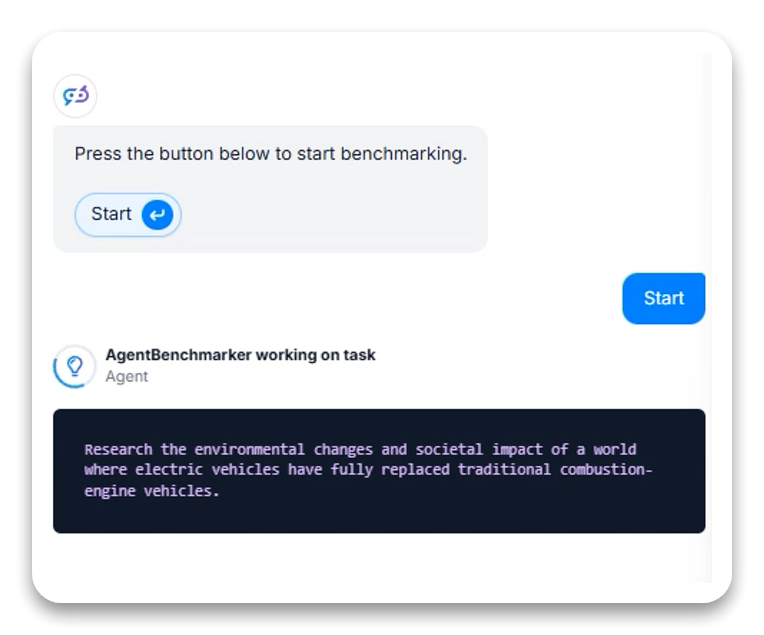
任务描述: 分析在电动车完全取代内燃机的世界中,环境变化及社会影响。
性能分析:
两种变体下,模型展现了强大的分析能力,未显示工具调用记录:
内容生成优势:
效率指标:
性能评分: 9/10
创意/分析性写作表现获优秀评价,因其:
本任务中,“Thinking”特性在可见日志中表现较少,表明模型在创意/分析型任务中更多依赖内部知识整合,而非外部工具调动。
根据全面评测,Gemini 2.0 Thinking 在多样任务类型中展现出卓越能力,其显著特点是问题解决过程的可视化:
| 任务类型 | 评分 | 主要优势 | 待提升方向 |
|---|---|---|---|
| 内容生成 | 9/10 | 多源调研,结构化组织 | 推理过程展现一致性 |
| 计算 | 9.5/10 | 精准、可验证、步骤清晰 | 所有变体均显示完整推理 |
| 摘要 | 10/10 | 快速、约束遵守、信息优先级处理 | 信息选取过程透明性 |
| 对比 | 8.5/10 | 框架结构、分析均衡 | 方法一致性、处理时长 |
| 创意/分析性写作 | 9/10 | 覆盖广度、细节深度、跨学科联系 | 工具使用透明性 |
| 综合 | 9.2/10 | 处理高效、输出优质、过程可见性 | 推理一致性、工具选择透明性 |
Gemini 2.0 Thinking 有别于标准 AI 模型之处在于其对内部流程的实验性公开。主要优势包括:
这种透明性的好处:
Gemini 2.0 Thinking 尤其适合以下需求场景:
其速度、质量与过程可见性,使其特别适合专业领域——对“为何如此”与“结果本身”同样重视的应用情境。
Gemini 2.0 Thinking 代表了 AI 发展的有趣实验方向,关注的不仅是结果质量,更是过程透明。其在我们测试套件中的表现显示出在调研、计算、摘要、对比和创意/分析性写作方面的强大能力,尤其是在摘要任务中表现卓越(10/10)。
“Thinking”方法为模型如何解决不同问题提供了宝贵洞见,尽管不同任务间透明性差异较大。这种不一致性正是其主要改进空间——如果推理展现更统一,将极大提升其教育与协作价值。
总体而言,以 9.2/10 的综合评分,Gemini 2.0 Thinking 不仅是一款能力突出的 AI 系统,还具备流程可见性的独特优势,非常适合那些既重视推理路径又重视最终结果的应用场景。
Gemini 2.0 Thinking 是 Google 推出的实验性 AI 模型,能够展示其推理过程,在内容生成、计算、摘要、分析性写作等多种任务中提供问题解决的透明度。
其独特的“思考”透明性让用户能够看到工具使用、推理步骤和解决策略,提升信任和教育价值,尤其适用于科研和协作场景。
该模型在五种关键任务类型上进行了基准测试:内容生成、计算、摘要、对比和创意/分析性写作,评估指标包括处理时间、输出质量和推理可视化。
优势包括多源调研、高精度计算、快速摘要、结构化对比、全面分析以及卓越的流程可视化能力。
模型应在所有任务类型中更加一致地展现推理过程,并在各种场景下提供更清晰的工具使用记录。
阿尔西亚是 FlowHunt 的一名 AI 工作流程工程师。拥有计算机科学背景并热衷于人工智能,他专注于创建高效的工作流程,将 AI 工具整合到日常任务中,从而提升生产力和创造力。
了解谷歌Gemini 2.0 Flash-Lite在内容创作、计算、摘要和创意任务等方面的表现。我们的深入分析揭示了该AI模型在速度与能力之间的卓越平衡,并为开发者和企业用户提供了实用见解。...
对 Google Gemini 2.5 Pro 预览版的全面评测,从内容生成、业务计算、摘要、研究对比、创意写作五大关键任务,评估其真实世界表现。了解其优势、局限性以及在商业与创意应用中的多面性。...
通过实际任务和对Gemini 1.5 Pro这一多功能AI智能体的推理与适应性进行深入分析,探索其思维过程、架构和决策机制。

