AI 能在几秒钟内分析大量数据,但并非所有数据都适合输出或具有相关性。文档转文本组件让您能够掌控检索器数据的处理和转化方式。
文档转文本组件旨在将输入的知识文档转化为纯文本格式。这对于需要文本数据以便进一步处理、分析或作为语言模型输入的 AI 和数据处理流程尤为有用。
组件作用
该组件可处理一个或多个结构化文档(如 HTML、Markdown、PDF 或其他支持的格式),提取其中的文本内容。您可以精确指定需要导出的文档部分,选择是否包含元数据,以及如何处理文档的章节或标题。输出为包含提取文本的统一消息对象,可用于后续任务如摘要、分类或问答。
输入项
该组件支持多个可配置输入:
| 输入名称 | 类型 | 必填 | 描述 | 默认值 |
|---|---|---|---|---|
| 文档 | List[Document] | 是 | 需要转换为文本的知识文档。 | N/A(用户提供) |
| 从 H1 开始(如存在) | Boolean | 是 | 如有 H1 标题,则从第一个 H1 开始提取。 | true |
| 从指针加载 | Boolean | 是 | 从最匹配输入查询的指针处开始提取,未匹配则全部加载。 | true |
| 最大 Token 数 | Integer | 否 | 输出文本中的最大 token 数。 | 3000 |
| 跳过最后一个标题 | Boolean | 是 | 跳过最后一个标题(通常为页脚),优化输出。 | false |
| 提取策略 | String | 是 | 文本提取策略:合并文档或从每个文档平均提取。 | “从每个文档平均提取” |
| 导出内容 | 多选 | 否 | 选择包含哪些内容类型(如 H1、H2、段落)。 | 默认全选 |
| 包含元数据 | 多选 | 否 | 若有可用,选择需包含在输出中的元数据字段。 | Product |
可用内容类型: H1、H2、H3、H4、H5、H6、段落
元数据选项: Author、Product、BreadcrumbList、VideoObject、BlogPosting、FAQPage、WebSite、opengraph
输出项
组件将生成如下输出:
- 消息:包含已转换文本及所选元数据的消息对象。
主要特性与优势
- 灵活内容提取:精准控制文档提取部分(如仅主标题与段落,或全部内容)。
- 可选元数据:可将丰富元数据(如作者、产品或结构化数据)包含于输出,便于后续上下文处理。
- Token 限制管理:可设置最大 token 数,确保输出符合下游模型要求。
- 自定义提取策略:
- 合并文档,优先从第一个文档填充至 token 限制:按顺序从首文档填充。
- 从每个文档平均提取:在 token 限制范围内平衡多文档内容。
- 智能章节处理:可跳过页脚或从最相关部分开始提取,提升文本相关性。
典型用例
- 为 AI 模型预处理知识库(如在嵌入或索引前)。
- 对大型文档进行摘要或精简,仅提取相关章节。
- 为聊天机器人、搜索引擎或其他自然语言处理管道提供结构化内容。
- 构建结合文本与元数据的混合检索系统,增强上下文。
总览表
| 能力 | 描述 |
|---|---|
| 输入类型 | 文档列表 |
| 输出类型 | 消息(文本 + 元数据) |
| 内容粒度 | 可选需包含的标题/段落 |
| 元数据选项 | 可多选需导出的元数据字段 |
| 输出大小控制 | 可设置最大 token 数 |
| 提取策略 | 可选择合并或多文档均衡提取 |
| 章节选择 | 可从 H1、指针处开始,或跳过最后标题 |
策略
机器人可能需要爬取多份文档以生成文本输出。策略设置用于让您控制在 token 限制下如何智能利用这些文档。
目前支持两种策略:
- 从每个文档平均提取: 所有找到的文档均等利用。
- 合并文档,优先从第一个文档填充至 token 限制: 将文档顺序拼接,优先考虑与查询最相关的内容。
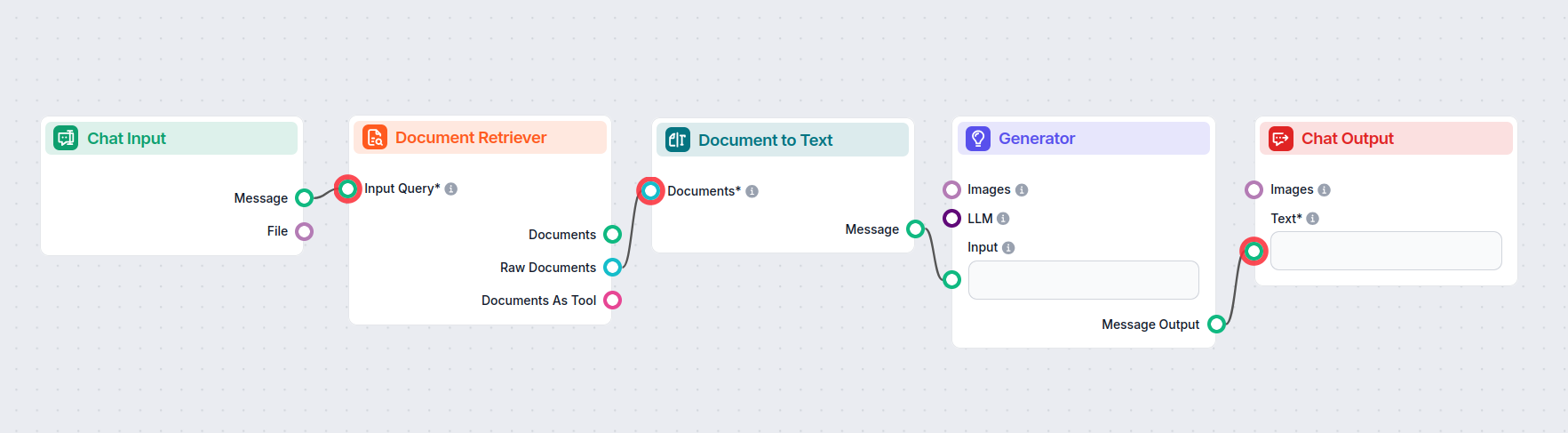
如何将文档转文本组件接入您的流程
这是一个转换器组件,用于连接两个输出之间的桥梁。文档转文本接收检索器组件输出的文档:
- 文档检索器 – 从已连接的知识源(页面、文档等)获取知识。
- URL 检索器 – 允许您指定机器人应获取知识的 URL。
- GoogleSearch – 赋予机器人搜索网络知识的能力。
知识在通过转换器时会被转化为可读的 Markdown 文本。该文本随后可连接至需要文本输入的组件,如拆分器、小部件或输出等。
以下是一个使用文档转文本组件,在文档检索器与 AI 生成器之间建立桥梁的流程示例: