文件检索器
FlowHunt 的文件检索器组件让您可以将文件引入工作流,并将其转换为可进一步处理的文档。它支持多文档处理策略,并可对文件中的图像使用 OCR,非常适合从各种文件类型中提取和转换信息。...
1 分钟阅读
Files
Automation
+3
使用 FlowHunt 的文档转文本组件,将结构化数据转换为可读的 markdown 文本,提供可自定义控制,实现高效且相关的 AI 驱动输出。
组件描述
AI 能在几秒钟内分析大量数据,但并非所有数据都适合输出或具有相关性。文档转文本组件让您能够掌控检索器数据的处理和转化方式。
文档转文本组件旨在将输入的知识文档转化为纯文本格式。这对于需要文本数据以便进一步处理、分析或作为语言模型输入的 AI 和数据处理流程尤为有用。
该组件可处理一个或多个结构化文档(如 HTML、Markdown、PDF 或其他支持的格式),提取其中的文本内容。您可以精确指定需要导出的文档部分,选择是否包含元数据,以及如何处理文档的章节或标题。输出为包含提取文本的统一消息对象,可用于后续任务如摘要、分类或问答。
该组件支持多个可配置输入:
| 输入名称 | 类型 | 必填 | 描述 | 默认值 |
|---|---|---|---|---|
| 文档 | List[Document] | 是 | 需要转换为文本的知识文档。 | N/A(用户提供) |
| 从 H1 开始(如存在) | Boolean | 是 | 如有 H1 标题,则从第一个 H1 开始提取。 | true |
| 从指针加载 | Boolean | 是 | 从最匹配输入查询的指针处开始提取,未匹配则全部加载。 | true |
| 最大 Token 数 | Integer | 否 | 输出文本中的最大 token 数。 | 3000 |
| 跳过最后一个标题 | Boolean | 是 | 跳过最后一个标题(通常为页脚),优化输出。 | false |
| 提取策略 | String | 是 | 文本提取策略:合并文档或从每个文档平均提取。 | “从每个文档平均提取” |
| 导出内容 | 多选 | 否 | 选择包含哪些内容类型(如 H1、H2、段落)。 | 默认全选 |
| 包含元数据 | 多选 | 否 | 若有可用,选择需包含在输出中的元数据字段。 | Product |
可用内容类型: H1、H2、H3、H4、H5、H6、段落
元数据选项: Author、Product、BreadcrumbList、VideoObject、BlogPosting、FAQPage、WebSite、opengraph
组件将生成如下输出:
| 能力 | 描述 |
|---|---|
| 输入类型 | 文档列表 |
| 输出类型 | 消息(文本 + 元数据) |
| 内容粒度 | 可选需包含的标题/段落 |
| 元数据选项 | 可多选需导出的元数据字段 |
| 输出大小控制 | 可设置最大 token 数 |
| 提取策略 | 可选择合并或多文档均衡提取 |
| 章节选择 | 可从 H1、指针处开始,或跳过最后标题 |
机器人可能需要爬取多份文档以生成文本输出。策略设置用于让您控制在 token 限制下如何智能利用这些文档。
目前支持两种策略:
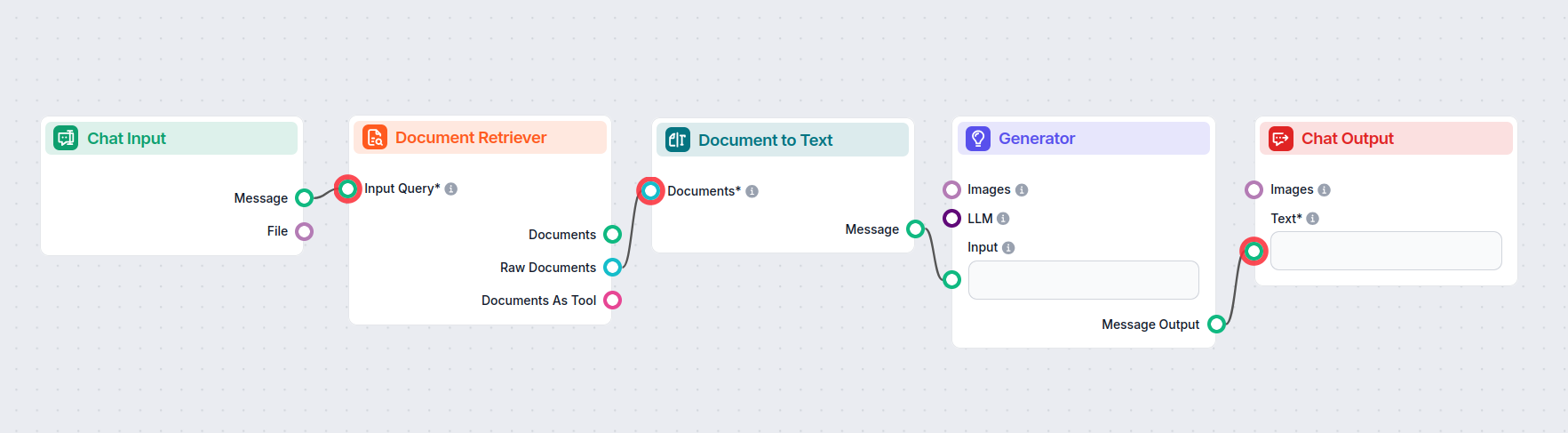
这是一个转换器组件,用于连接两个输出之间的桥梁。文档转文本接收检索器组件输出的文档:
知识在通过转换器时会被转化为可读的 Markdown 文本。该文本随后可连接至需要文本输入的组件,如拆分器、小部件或输出等。
以下是一个使用文档转文本组件,在文档检索器与 AI 生成器之间建立桥梁的流程示例:
该组件从检索器类型组件中获取知识,并将其转换为可读的 markdown 文本,然后可连接至任何以文本为输入的组件。
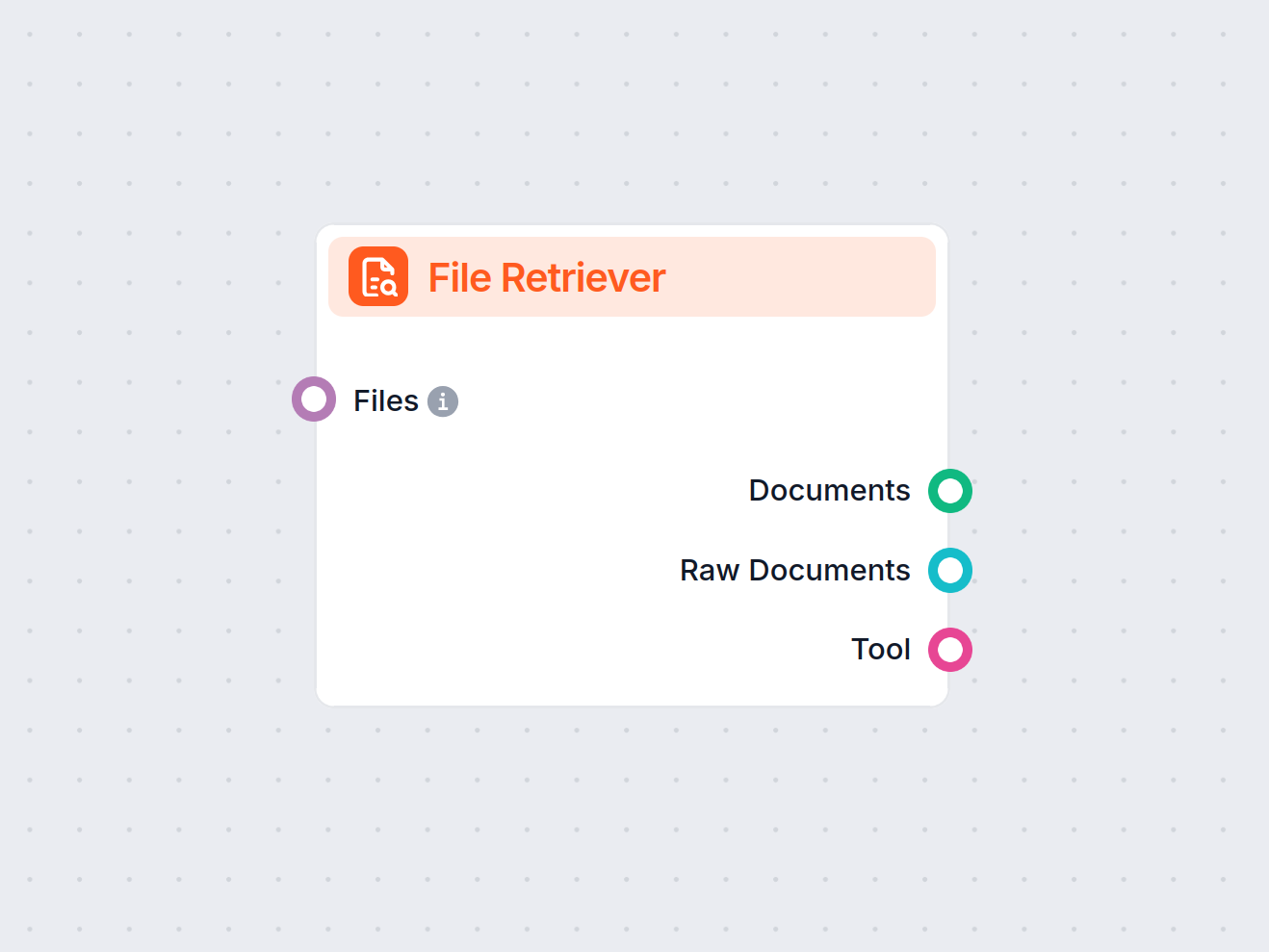
FlowHunt 的文件检索器组件让您可以将文件引入工作流,并将其转换为可进一步处理的文档。它支持多文档处理策略,并可对文件中的图像使用 OCR,非常适合从各种文件类型中提取和转换信息。...
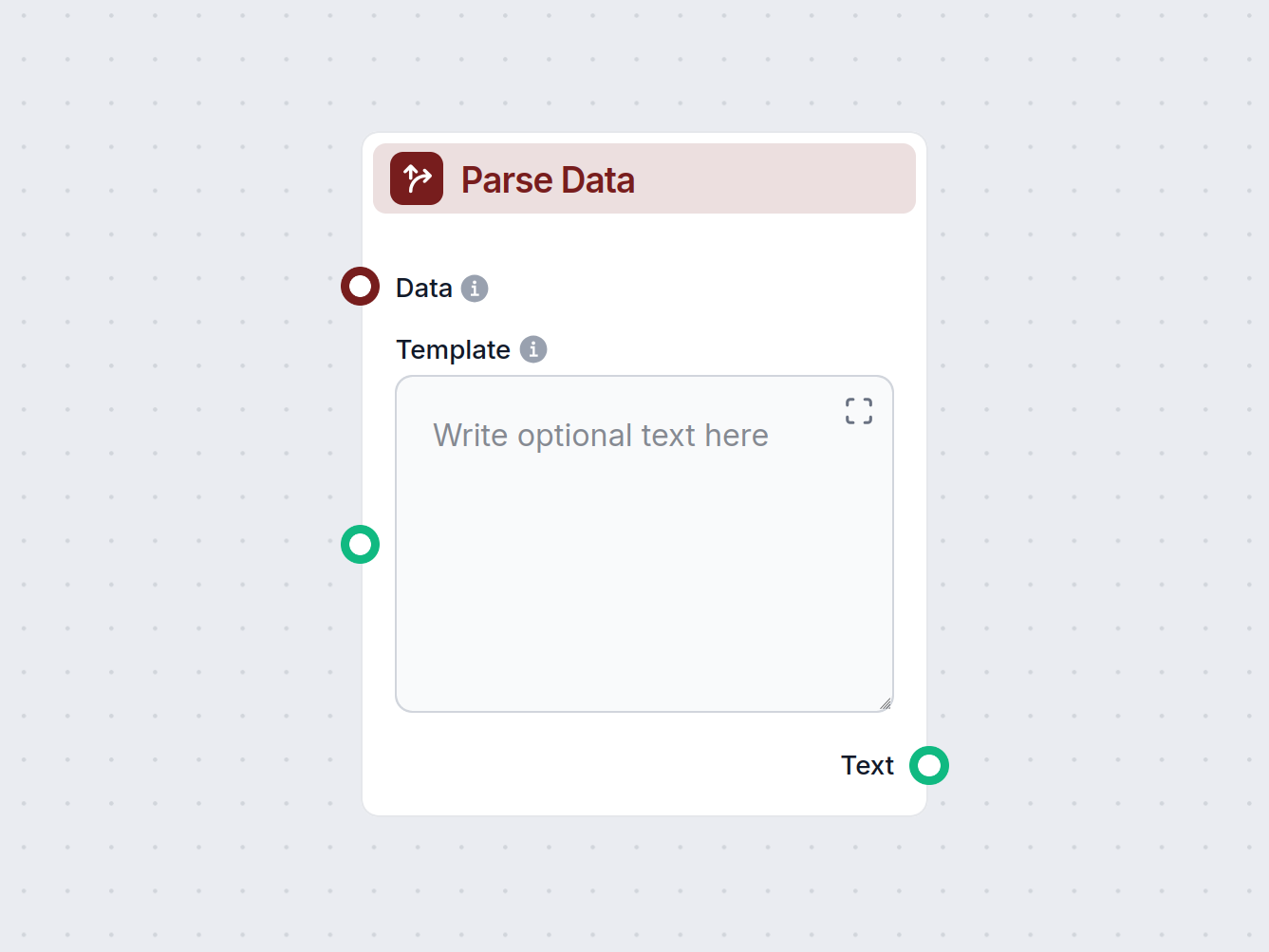
解析数据组件使用可自定义的模板将结构化数据转换为纯文本。它能够灵活地格式化和转换数据输入,以用于工作流的后续环节,帮助标准化或准备信息供下游组件使用。...
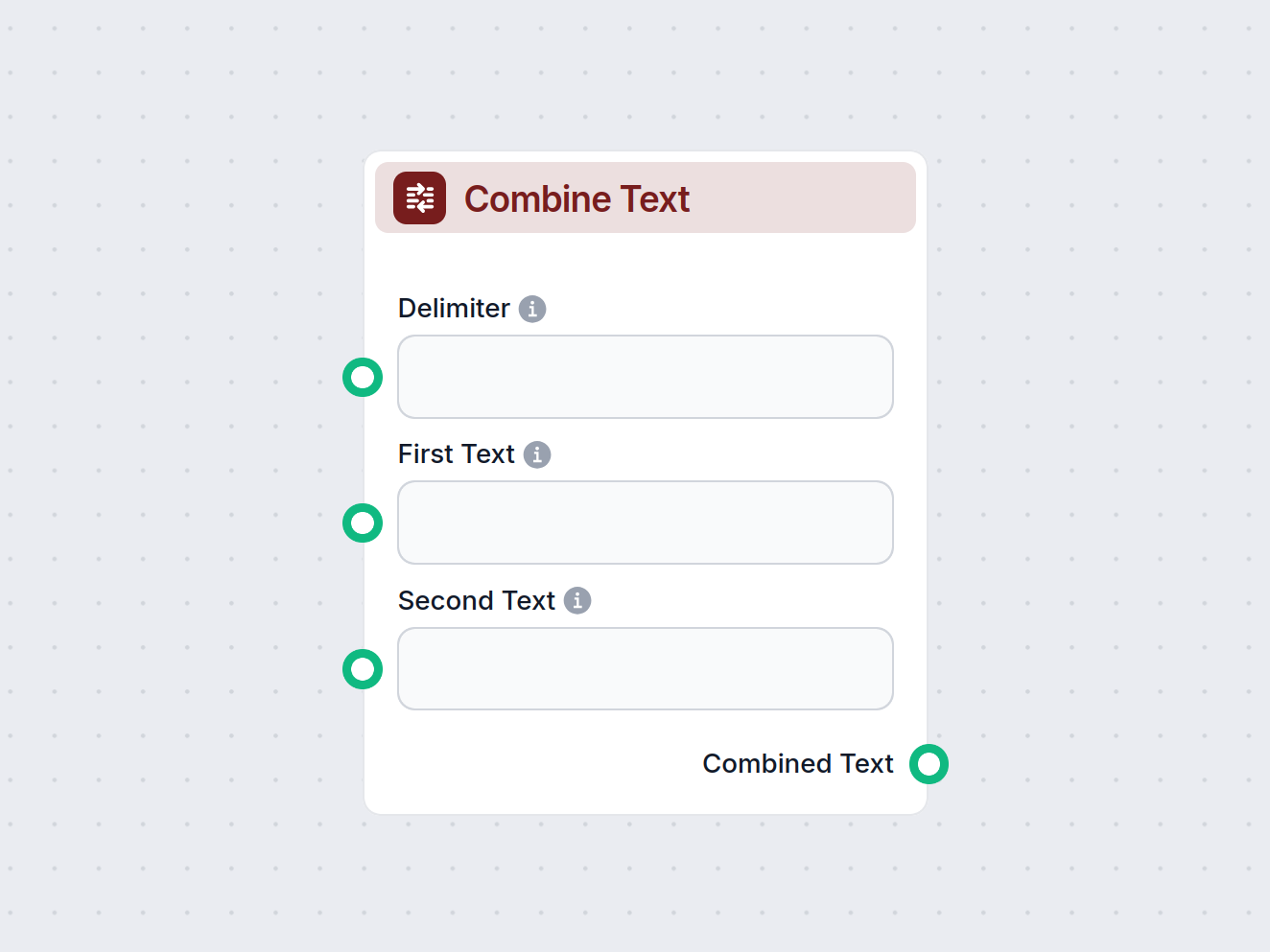
FlowHunt 中的合并文本组件允许你将两个独立的文本输入合并为一个输出,并可选择使用分隔符。非常适合需要将多个来源或步骤的信息整合成一条连贯消息的工作流。...