
信息检索
信息检索利用人工智能、自然语言处理和机器学习,能够高效且准确地检索满足用户需求的数据。作为网页搜索引擎、数字图书馆和企业级解决方案的基础,IR应对了诸如歧义、算法偏见和可扩展性等挑战,未来趋势聚焦于生成式人工智能和深度学习。...
1 分钟阅读
Information Retrieval
AI
+4

AI 搜索利用机器学习和向量嵌入理解搜索意图和上下文,带来远超精确关键词匹配的高度相关结果。
AI 搜索通过机器学习理解搜索查询的上下文和意图,将其转化为数值向量,从而获得更准确的结果。与传统关键词搜索不同,AI 搜索能够解释语义关系,适用于多种数据类型和语言。
AI 搜索(常称为语义搜索或向量搜索)是一种利用机器学习模型理解搜索查询意图和上下文含义的搜索方法。不同于传统基于关键词的搜索,AI 搜索将数据和查询转化为被称为向量或嵌入的数值化表示。这样,搜索引擎能够理解不同数据之间的语义关系,即使没有精确关键词,也能提供更相关、更准确的结果。
AI 搜索代表了搜索技术的重要进化。传统搜索引擎主要依赖关键词匹配,通过查询和文档中是否包含特定词语来衡量相关性。而 AI 搜索则通过机器学习模型,理解查询和数据背后的深层含义和语境。
通过将文本、图片、音频等非结构化数据转化为高维向量,AI 搜索能够衡量不同内容之间的相似度。这一方法使搜索引擎即使在结果中不包含完整关键词时,也能返回语境相关的内容。
核心组成:
AI 搜索的核心是向量嵌入。向量嵌入是对数据(如文本、图片等)语义含义的数值化表示。嵌入能将相似的数据定位在多维向量空间的邻近位置。
工作原理:
示例:
传统关键词搜索引擎通过查询与文档中是否包含相同关键词来实现内容匹配,常用倒排索引、词频等技术对结果排序。
关键词搜索的局限:
AI 搜索优势:
| 方面 | 关键词搜索 | AI 搜索(语义/向量) |
|---|---|---|
| 匹配方式 | 精确关键词匹配 | 语义相似度 |
| 上下文感知能力 | 有限 | 很强 |
| 同义词处理 | 需手动维护同义词列表 | 嵌入模型自动识别 |
| 拼写错误容忍度 | 无模糊搜索则易失败 | 语义上下文容忍度高 |
| 意图理解能力 | 很低 | 很强 |
语义搜索是 AI 搜索的核心应用,聚焦于理解用户意图和查询的上下文含义。
流程:
关键技术:
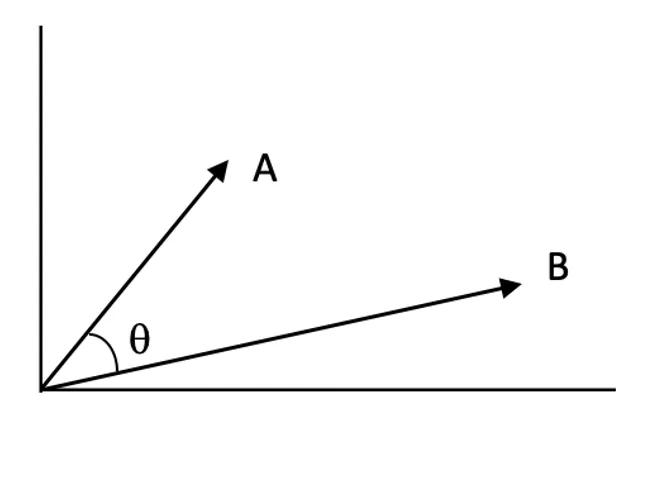
相似度分数:
相似度分数衡量两个向量在向量空间中的相关程度,分数越高表示查询与文档越相关。
近似最近邻(ANN)算法:
在高维空间查找精确最近邻计算量大,ANN 算法可高效给出近似结果。
AI 搜索凭借超越关键词的理解能力,在各行业拥有广泛应用。
描述: 语义搜索通过理解查询意图,提供上下文相关的搜索结果,提升用户体验。
示例:
描述: 通过理解用户偏好和行为,AI 搜索可推荐个性化内容或产品。
示例:
描述: AI 搜索让系统理解并从文档中精准提取信息以回答用户问题。
示例:
描述: AI 搜索可对图片、音频、视频等非结构化数据通过嵌入进行检索。
示例:
将 AI 搜索集成到自动化和聊天机器人中,可大幅提升其能力。
优势:
实现步骤:
用例示例:
尽管 AI 搜索优势显著,但也面临诸多挑战:
应对策略:
AI 领域的语义与向量搜索已成为传统关键词和模糊搜索的强有力替代方案,通过理解查询的上下文和含义,大幅提升了结果的相关性和准确性。
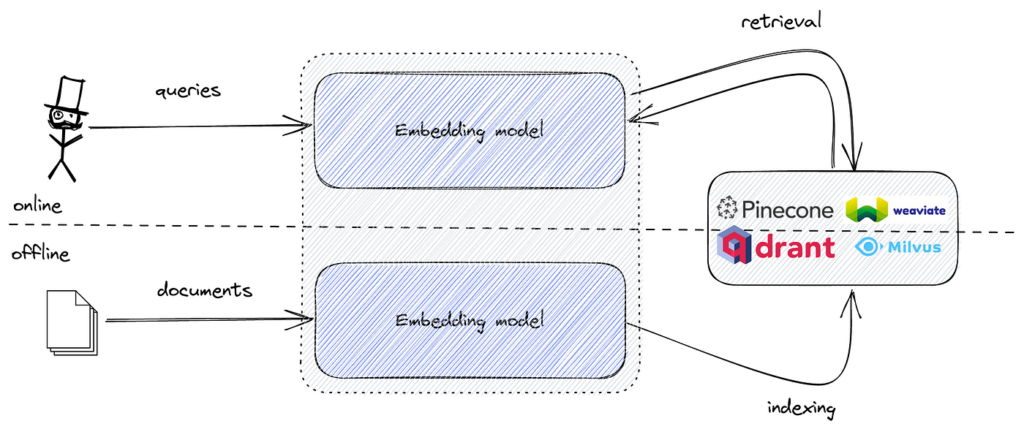
实现语义搜索时,文本数据会被转化为能捕捉语义含义的向量嵌入。这些嵌入是高维数值表示。要高效地检索与查询嵌入最相似的内容,需要专门针对高维空间相似性搜索优化的工具。
FAISS 提供了高效完成此任务的算法与数据结构。结合语义嵌入和 FAISS,可构建处理大规模数据集、延迟极低的强大语义搜索引擎。
用 FAISS 实现语义搜索一般包括以下步骤:
下面详细说明每一步。
准备数据集(如文章、工单、产品描述)。
示例:
documents = [
"How to reset your password on our platform.",
"Troubleshooting network connectivity issues.",
"Guide to installing software updates.",
"Best practices for data backup and recovery.",
"Setting up two-factor authentication for enhanced security."
]
根据需求清洗和格式化文本数据。
用 Hugging Face(transformers 或 sentence-transformers)等库的预训练 Transformer 模型生成嵌入。
示例:
from sentence_transformers import SentenceTransformer
import numpy as np
# 加载预训练模型
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
# 生成所有文档的嵌入
embeddings = model.encode(documents, convert_to_tensor=False)
embeddings = np.array(embeddings).astype('float32')
用 FAISS 索引存储嵌入,实现高效相似性搜索。
示例:
import faiss
embedding_dim = embeddings.shape[1]
index = faiss.IndexFlatL2(embedding_dim)
index.add(embeddings)
IndexFlatL2 用 L2(欧氏距离)执行暴力搜索。将用户查询转为嵌入,查找最近邻。
示例:
query = "How do I change my account password?"
query_embedding = model.encode([query], convert_to_tensor=False)
query_embedding = np.array(query_embedding).astype('float32')
k = 3
distances, indices = index.search(query_embedding, k)
利用返回的索引展示最相关文档。
示例:
print("Top results for your query:")
for idx in indices[0]:
print(documents[idx])
期望输出:
Top results for your query:
How to reset your password on our platform.
Setting up two-factor authentication for enhanced security.
Best practices for data backup and recovery.
FAISS 提供多种索引类型:
倒排文件(IndexIVFFlat)示例:
nlist = 100
quantizer = faiss.IndexFlatL2(embedding_dim)
index = faiss.IndexIVFFlat(quantizer, embedding_dim, nlist, faiss.METRIC_L2)
index.train(embeddings)
index.add(embeddings)
归一化与内积检索:
对文本数据,使用余弦相似度通常更有效。
AI 搜索是一种现代搜索方法,利用机器学习和向量嵌入理解查询的意图和上下文含义,带来比传统基于关键词的搜索更准确、更相关的结果。
与依赖精确匹配的关键词搜索不同,AI 搜索能够解释查询背后的语义关系和意图,使其适用于自然语言和含糊不清的输入。
向量嵌入是文本、图片或其他数据类型的数值化表示,能够捕捉其语义含义,使搜索引擎能够衡量不同数据之间的相似性和上下文。
AI 搜索驱动了电商中的语义搜索、流媒体的个性化推荐、客户支持中的问答系统、非结构化数据浏览,以及科研和企业文档检索等。
常用工具包括用于高效向量相似性搜索的 FAISS,以及如 Pinecone、Milvus、Qdrant、Weaviate、Elasticsearch 和 Pgvector 等可扩展存储和检索嵌入的向量数据库。
通过集成 AI 搜索,聊天机器人和自动化系统能够更深入理解用户查询,检索上下文相关答案,提供动态且个性化的响应。
主要挑战包括高计算资源需求、模型可解释性的复杂性、高质量数据的需求,以及敏感信息的数据隐私与安全保障。
FAISS 是一个开源库,用于高维向量嵌入的高效相似性搜索,被广泛用于构建能够处理大规模数据集的语义搜索引擎。
信息检索利用人工智能、自然语言处理和机器学习,能够高效且准确地检索满足用户需求的数据。作为网页搜索引擎、数字图书馆和企业级解决方案的基础,IR应对了诸如歧义、算法偏见和可扩展性等挑战,未来趋势聚焦于生成式人工智能和深度学习。...
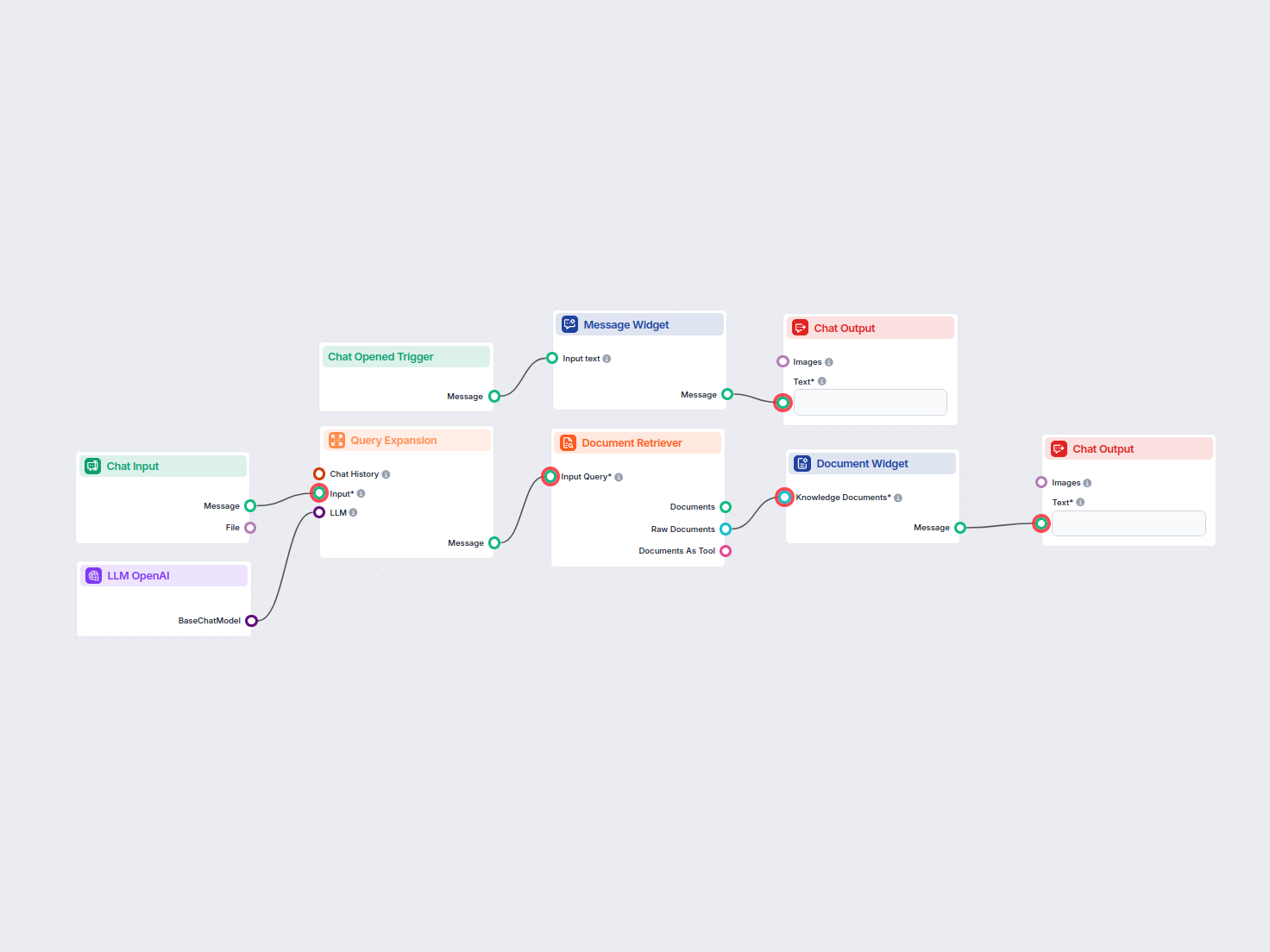
利用 AI 驱动的语义搜索,轻松检索和查找私人知识库文档中的信息。该流程会扩展用户查询,跨多个知识源进行搜索,并以用户友好的聊天界面呈现相关结果。...
将 FlowHunt 与 Azure Wiki 搜索集成,利用 AI 驱动的索引、语义搜索和即时知识检索,覆盖您的企业 Wiki。简化知识管理,提高生产力,为团队提供快速、具备上下文感知的答案。...