提升法(Boosting)
提升法是一种机器学习技术,通过结合多个弱学习器的预测结果来构建一个强学习器,从而提升准确率并处理复杂数据。了解主要算法、优势、挑战及实际应用场景。...
1 分钟阅读
Boosting
Machine Learning
+3
Bagging,全称为自助聚合(Bootstrap Aggregating),是一种人工智能和机器学习中用于提升预测模型准确性与鲁棒性的基础集成学习方法。其核心思想是通过有放回地对训练集进行随机采样(自助采样),构建多个训练数据子集。每个子集用于独立训练一个基础模型(亦称弱学习器)。随后,将这些模型的预测结果进行聚合:回归任务通常采用平均法,分类任务则采用多数投票法,从而得到方差更小、稳定性更强的最终预测结果。
集成学习是一种通过组合多个模型来构建更强大模型的机器学习范式。其核心思想是:一组模型协同工作能够优于单一模型,就像专家团队集思广益获得更准确的判断。集成学习方法(如bagging、boosting和stacking)通过结合单个模型的优势,解决方差或偏差带来的误差。在单个模型易出现高方差或高偏差(导致过拟合或欠拟合)的任务中,集成学习尤为有效。
自助采样是一种统计技术,通过有放回地从数据集中产生多个随机样本。在bagging中,自助采样让每个模型都能见到数据的不同视角,样本中还可能包含重复数据点。这种训练数据的多样性有助于降低过拟合风险,使每个模型都能捕捉数据的不同特征。自助采样是bagging构建模型集成的基础,保证模型能够在不同样本上训练,从而增强整体模型的鲁棒性与泛化能力。
基础学习器是bagging过程中在不同数据子集上训练得到的单个模型。这些模型通常较为简单或为弱学习器,如决策树,其单独预测能力有限。但结合起来后,可以构建出强大的集成模型。基础学习器的选择会显著影响集成效果,决策树因其结构简单且能捕捉数据的非线性关系而常被采用。由于每个基础学习器都在不同的自助采样集上训练,模型间的多样性也是bagging成功的关键。
聚合是bagging的最后一步,即将各基础学习器的预测结果结合为最终输出。回归任务中,通常取预测值的平均;分类任务中,则采用多数投票确定最终类别。聚合过程能够减少模型预测的方差,提高模型的稳定性和准确性。通过汇总多个模型的输出,聚合能有效减弱单个模型错误的影响,从而获得更为鲁棒的集成预测。
Bagging通过如下结构化流程提升模型性能:
Bagging的典型应用是随机森林算法,其以决策树为基础学习器实现bagging。每棵树在不同的自助采样样本上训练,最终通过聚合所有树的预测结果给出最终输出。随机森林广泛用于分类和回归任务,能够处理高维大数据集,并具备极强的抗过拟合能力。
Bagging可通过scikit-learn等Python库轻松实现。以下为使用BaggingClassifier和决策树基础学习器的基本示例:
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import BaggingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化基础分类器
base_classifier = DecisionTreeClassifier(random_state=42)
# 初始化Bagging分类器
bagging_classifier = BaggingClassifier(base_estimator=base_classifier, n_estimators=10, random_state=42)
# 训练Bagging分类器
bagging_classifier.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = bagging_classifier.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Bagging分类器的准确率:", accuracy)
Bagging(自助聚合)是一种集成技术,通过在数据的随机子集上训练多个基础模型,将它们的预测结果聚合起来,从而降低方差并提升最终模型的准确性和鲁棒性。
通过在不同自助采样样本上训练每个基础模型,bagging增加了模型间的多样性。聚合它们的预测结果能够平滑个体误差,从而减少过拟合并增强泛化能力。
由于决策树简单且方差较高,通常作为bagging中的基础学习器,但也可根据实际问题选择其他算法。
Bagging被应用于医疗健康中的预测建模、金融中的欺诈检测、环境领域的生态预测,以及IT安全中的网络入侵检测等。
Bagging独立训练基础模型并聚合其输出以降低方差,而Boosting则按顺序训练模型,重点纠正前一轮的错误,以同时降低偏差和方差。
提升法是一种机器学习技术,通过结合多个弱学习器的预测结果来构建一个强学习器,从而提升准确率并处理复杂数据。了解主要算法、优势、挑战及实际应用场景。...
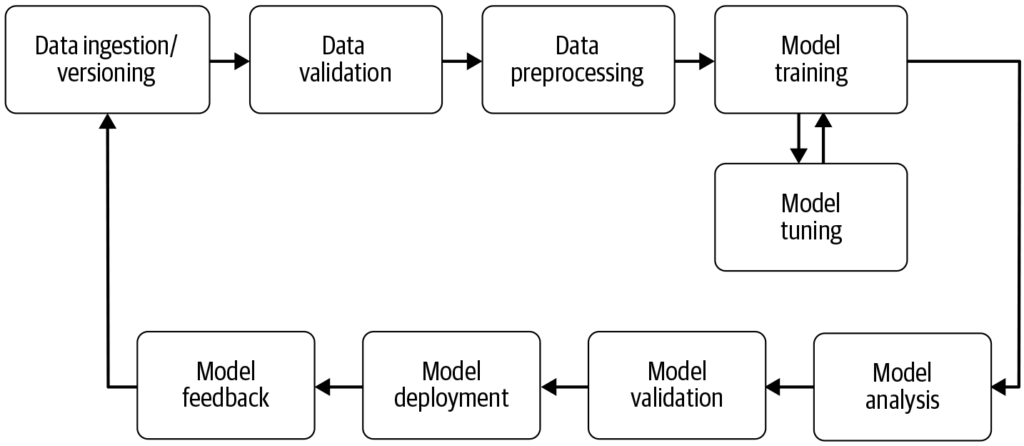
机器学习流水线是一种自动化工作流程,可高效且大规模地简化和标准化机器学习模型的开发、训练、评估与部署流程,将原始数据转化为可执行洞察。...
基于检索增强生成(RAG)的问答系统结合了信息检索与自然语言生成,通过从外部来源补充相关、最新的数据,提升大语言模型(LLM)的回答能力。该混合方法提高了准确性、相关性和在动态领域的适应性。...