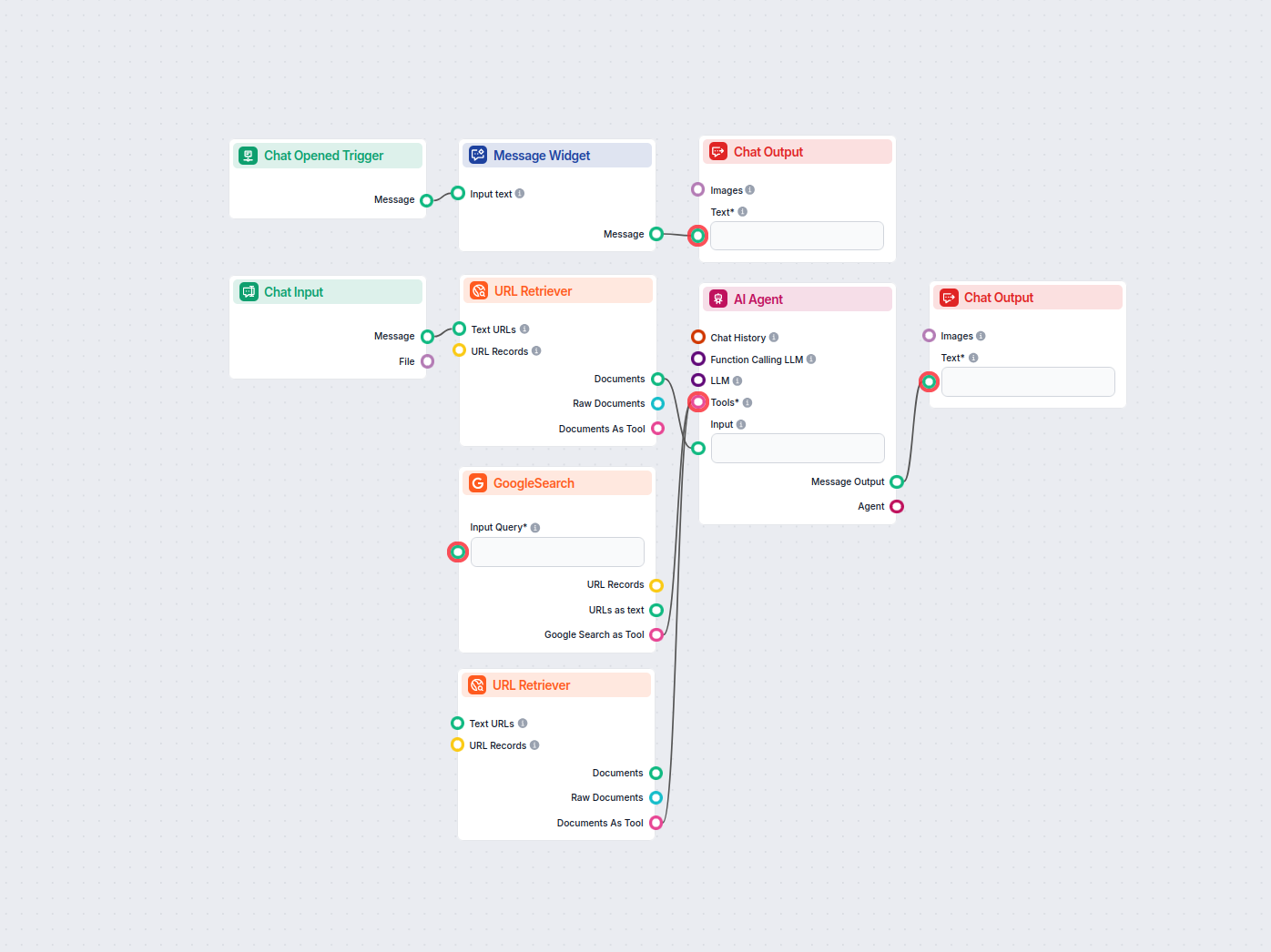
Sitemap 到 llms.txt AI 转换器
使用 AI 将任意 sitemap.xml 转换为结构良好的 llms.txt 格式。此工作流从 sitemap 中获取 URL,提取和处理其内容,并利用 AI 智能体生成适合 AI 训练或知识摄取的优化 llms.txt 文件。...
2 分钟阅读
llms.txt 是一个简化网站内容供 LLMs 使用的 Markdown 文件,通过提供结构化、机器可读的索引,增强 AI 驱动的互动。
llms.txt 文件是一种标准化的 Markdown 格式文本文件,旨在改善大型语言模型(LLMs)访问、理解和处理网站信息的方式。该文件托管在网站根目录(如 /llms.txt),作为一个经过筛选的索引,专为推理时机器处理而结构化和摘要内容。其主要目标是绕过传统 HTML 内容的复杂性——如导航菜单、广告和 JavaScript——以提供清晰、便于人类和机器阅读的数据。
与 robots.txt 或 sitemap.xml 等其他 Web 标准不同,llms.txt 明确为推理引擎(如 ChatGPT、Claude 或 Google Gemini)而设计,而非搜索引擎。它帮助 AI 系统在有限的上下文窗口内,仅获取最相关和有价值的信息,而这些窗口通常不足以处理整个网站的全部内容。
该概念由 Answer.AI 联合创始人 Jeremy Howard 于 2024 年 9 月提出。它作为解决 LLM 在与复杂网站交互时效率低下的方案应运而生。传统的 HTML 页面处理方式常常导致计算资源浪费和内容误解。通过制定 llms.txt 这样的标准,网站所有者可确保其内容被 AI 系统准确、高效地解析。
llms.txt 文件服务于人工智能和 LLM 驱动交互的多个实际用途。其结构化格式使 LLM 能高效检索和处理网站内容,克服上下文窗口大小和处理效率的限制。
llms.txt 文件遵循特定的 Markdown 架构,确保兼容人类和机器。结构包括:
示例:
# 示例网站
> 一个分享人工智能知识与资源的平台。
## 文档
- [快速入门指南](https://example.com/docs/quickstart.md):适合初学者的上手指南。
- [API 参考](https://example.com/docs/api.md):详细的 API 文档。
## 政策
- [服务条款](https://example.com/terms.md):平台使用的法律准则。
- [隐私政策](https://example.com/privacy.md):数据处理与用户隐私信息。
## Optional
- [公司历史](https://example.com/history.md):主要里程碑与成就时间线。
llms.txt 指引 AI 获取产品分类、退换货政策和尺码指南等信息。FastHTML 是一个用于构建服务器端渲染 Web 应用的 Python 库,其 llms.txt 文件简化了文档的访问。文件内包含快速入门、HTMX 参考和示例应用的链接,方便开发者快速定位所需资源。
示例片段:
# FastHTML
> 一个用于创建服务器端渲染超媒体应用的 Python 库。
## 文档
- [快速入门](https://fastht.ml/docs/quickstart.md):主要功能概览。
- [HTMX 参考](https://github.com/bigskysoftware/htmx/blob/master/www/content/reference.md):HTMX 属性和方法大全。
像 Nike 这样的电商巨头可通过 llms.txt 文件,为 AI 系统提供产品线、可持续发展举措和客户支持政策等信息。
示例片段:
# Nike
> 全球领先的运动鞋服企业,注重可持续发展与创新。
## 产品线
- [跑步鞋](https://nike.com/products/running.md):React 泡棉与 Vaporweave 技术详情。
- [可持续发展举措](https://nike.com/sustainability.md):2025 年目标与环保材料。
## 客户支持
- [退货政策](https://nike.com/returns.md):60 天退货窗口及例外说明。
- [尺码指南](https://nike.com/sizing.md):鞋服尺码对照表。
三者虽均为自动化系统设计,但目的和目标用户差异明显。
llms.txt:
robots.txt:
sitemap.xml:
robots.txt 与 sitemap.xml,llms.txt 针对推理引擎,而非传统搜索引擎。llms.txt 和 llms-full.txt,适用于托管文档。llms.txt。https://example.com/llms.txt)。llms_txt2ctx 等工具验证文件是否符合标准。llms.txt 或 llms-full.txt 文件(如 Claude 或 ChatGPT)。llms.txt 在开发者和部分平台中逐渐流行,但尚未被 OpenAI、Google 等主流 LLM 提供商官方支持。llms-full.txt 文件可能超出部分 LLM 的上下文窗口。尽管存在这些挑战,llms.txt 仍代表着为 AI 驱动系统优化内容的前瞻性思路。采用此标准,能确保组织内容在 AI 优先的时代更易获取、更准确、更具优先级。
研究:大型语言模型(LLMs)
大型语言模型(LLMs)已成为自然语言处理领域的主流技术,广泛应用于聊天机器人、内容审核和搜索引擎等场景。在 Nicholas 和 Bhatia(2023)的《迷失在翻译中:大型语言模型在非英语内容分析中的应用》中,作者清晰解释了 LLM 的工作原理,指出英语与其他语言在数据可用性上的差距,并讨论了通过多语言模型弥合这一差距的努力。论文详细分析了使用 LLM 进行内容分析时面临的挑战,特别是在多语种环境下,并为研究者、企业和政策制定者在部署与开发 LLM 方面提出了建议。作者强调,尽管取得了进展,但非英语语言领域仍面临重大限制。阅读全文
Müller 和 Laurent(2022)的论文《Cedille:一个大型自回归法语语言模型》介绍了 Cedille —— 一个大规模、专为法语设计的语言模型。Cedille 为开源项目,在法语零样本基准测试中表现优越,甚至在多项任务上可与 GPT-3 媲美。研究还评估了 Cedille 的安全性,通过数据集过滤降低了有害内容。该成果凸显了为特定语言开发 LLM 的重要性和影响力,并强调了 LLM 生态中语言专用资源的必要性。阅读全文
在 Ojo 和 Ogueji(2023)的《商用大型语言模型在非洲语言上的表现如何?》中,作者评估了商用 LLM 在非洲语言的翻译和文本分类任务中的表现。结果显示,这些模型在非洲语言上普遍表现不佳,且分类效果优于翻译。分析涵盖了来自不同语系和地区的八种非洲语言。作者呼吁商用 LLM 应给予非洲语言更多代表性,以应对其日益增长的应用需求。该研究揭示了当前的差距及更具包容性的语言模型开发需求。阅读全文
Chang 等(2024)的《Goldfish:350 种语言的单语语言模型》探讨了低资源语言中单语与多语模型的性能。研究表明,在许多语言上,大型多语模型甚至不如简单的二元模型,FLORES 困惑度表现较差。Goldfish 项目推出了针对 350 种语言训练的单语模型,大幅提升了低资源语言表现。作者倡导针对弱势语言开展更有针对性的模型开发。该成果为当前多语 LLM 的局限与单语替代方案的潜力提供了宝贵见解。阅读全文
llms.txt 是一个托管在网站根目录(如 /llms.txt)的标准化 Markdown 文件,提供为大型语言模型优化的精选内容索引,使 AI 驱动的交互更高效。
与 robots.txt(用于搜索引擎抓取)或 sitemap.xml(用于索引)不同,llms.txt 专为 LLMs 设计,采用简化的 Markdown 结构,为 AI 推理优先提供高价值内容。
它包括 H1 标题(网站名称)、引用块摘要、用于上下文的详细部分、用 H2 分隔的资源列表(含链接和描述),以及可选的次要资源部分。
llms.txt 由 Answer.AI 联合创始人 Jeremy Howard 于 2024 年 9 月提出,旨在解决 LLMs 处理复杂网站内容时的低效问题。
llms.txt 通过减少噪声(如广告、JavaScript)、优化内容以适应上下文窗口,并实现准确解析,提升 LLM 的效率,适用于技术文档、电商等场景。
可手动用 Markdown 编写,也可通过 Mintlify 或 Firecrawl 等工具自动生成。使用 llms_txt2ctx 等验证工具可确保标准合规。
使用 AI 将任意 sitemap.xml 转换为结构良好的 llms.txt 格式。此工作流从 sitemap 中获取 URL,提取和处理其内容,并利用 AI 智能体生成适合 AI 训练或知识摄取的优化 llms.txt 文件。...
文本摘要是人工智能中的一项重要过程,可将冗长的文档提炼为简明扼要的摘要,同时保留关键信息和意义。通过利用 GPT-4 和 BERT 等大型语言模型,实现了通过抽象、抽取及混合方法对海量数字内容的高效管理与理解。...
自动将您网站的 sitemap.xml 转换为适合 LLM 的文档格式。此 AI 驱动的转换器可提取、处理并将您的网页内容结构化为标准化的 llms.txt 格式,非常适合 AI 训练和 LLM 应用。...

