实时领域专属RAG聊天机器人
一个实时聊天机器人,使用仅限于您自有域名的Google搜索,检索相关的网页内容,并利用OpenAI LLM为用户提供最新的信息答案。非常适合在客户支持或信息门户中提供准确、特定领域的响应。...
1 分钟阅读
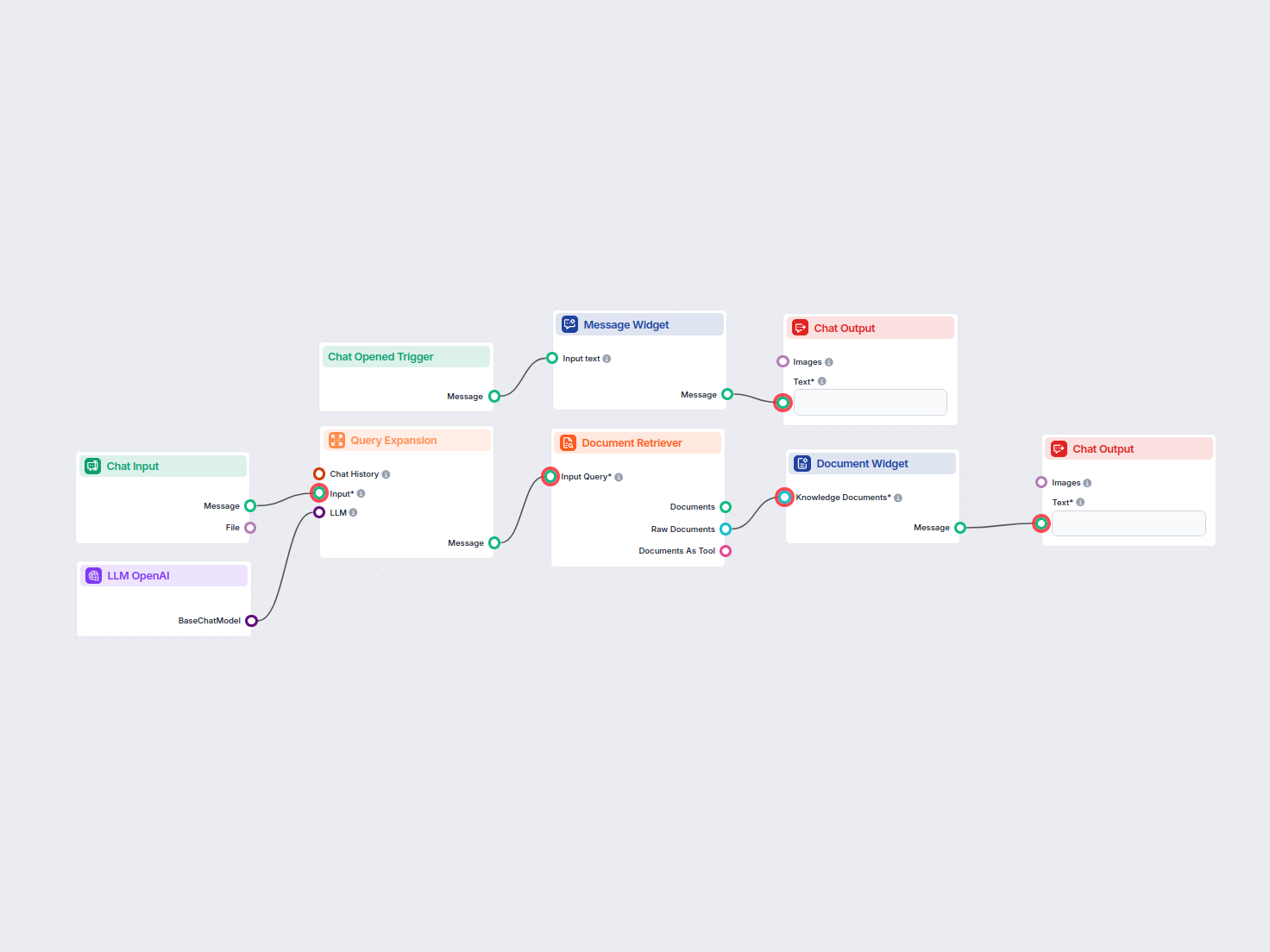
聊天机器人的检索管道,是指一套技术架构和流程,使聊天机器人能够根据用户提问,获取、处理并检索相关信息。不像仅依赖预训练语言模型的简单问答系统,检索管道引入了外部知识库或数据源,即便相关数据不在语言模型本身内,也能让机器人提供准确、具备上下文、并且最新的回复。
检索管道通常由多个组件构成,包括数据摄取、嵌入创建、向量存储、上下文检索和回复生成。它的实现常常借助检索增强生成(RAG),结合了数据检索系统和**大语言模型(LLM)**的优势来生成回复。
检索管道通过以下方式提升聊天机器人的能力:
文档摄取
收集并预处理原始数据,可包括 PDF、文本文件、数据库或 API。LangChain 或 LlamaIndex 等工具常用于无缝数据摄取。
示例:将客户服务常见问题或产品参数导入系统。
文档预处理
长文档被拆分为更小、语义相关的片段。这样便于嵌入模型处理,因其往往有 token 限制(如 512 tokens)。
示例代码片段:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(document_list)
嵌入生成
文本数据通过嵌入模型转化为高维向量,数值化编码其语义含义。
示例嵌入模型:OpenAI 的 text-embedding-ada-002 或 Hugging Face 的 e5-large-v2。
向量存储
嵌入向量存储在向量数据库中,便于高效的相似度检索。常用工具有 Milvus、Chroma 或 PGVector。
示例:将产品描述及其嵌入向量存储以便高效检索。
查询处理
用户提问收到后,同样通过嵌入模型转为查询向量,实现与已存嵌入的语义相似度匹配。
示例代码片段:
query_vector = embedding_model.encode("What are the specifications of Product X?")
retrieved_docs = vector_db.similarity_search(query_vector, k=5)
数据检索
系统根据相似度分数(如余弦相似度)检索到最相关的数据片段。多模态检索系统还可结合 SQL 数据库、知识图谱和向量检索,以获得更强结果。
回复生成
检索到的数据与用户提问结合,输入大语言模型(LLM),生成最终的自然语言回复。这一步通常称为增强生成。
示例提示模板:
prompt_template = """
Context: {context}
Question: {question}
Please provide a detailed response using the context above.
"""
后处理与验证
高级检索管道包括幻觉检测、相关性检查或回复评分,确保结果真实且相关。
客户支持
聊天机器人可检索产品手册、故障排查指南或 FAQ,快速响应客户问题。
示例:机器人检索用户手册相关章节,指导客户重置路由器。
企业知识管理
企业内部机器人可访问公司专有数据,如人力资源政策、IT 支持文档或合规指南。
示例:员工询问内部机器人有关病假政策。
电商
聊天机器人帮助用户检索产品详情、评价或库存情况。
示例:“Product Y 的主要功能有哪些?”
医疗健康
聊天机器人检索医学文献、指南或患者数据,为医疗专业人士或患者提供帮助。
示例:机器人从药品数据库中检索药物相互作用警告。
教育与科研
学术机器人通过 RAG 管道检索学术论文、回答问题或总结研究成果。
示例:“你能总结一下这篇 2023 年气候变化研究的结论吗?”
法律与合规
聊天机器人检索法律文档、案例法或合规要求,辅助法律专业人士。
示例:“关于 GDPR 法规的最新进展是什么?”
构建一个能够回答公司年度财报 PDF 问题的聊天机器人。
结合 SQL、向量检索和知识图谱的聊天机器人,用于回答员工问题。
通过检索管道,聊天机器人突破了静态训练数据的限制,实现动态、精准且具备丰富上下文的交互。
检索管道在现代聊天机器人系统中发挥着关键作用,赋能智能且具备上下文感知的交互。
Pengfei Zhu 等人(2018)《Lingke: A Fine-grained Multi-turn Chatbot for Customer Service》
介绍了 Lingke 聊天机器人,集成信息检索以支持多轮对话。该系统利用细粒度管道处理,从非结构化文档中提取回复,并采用注意力上下文-回复匹配,有效提升了机器人应对复杂用户问题的能力。
点击阅读论文。
Rama Akkiraju 等人(2024)《FACTS About Building Retrieval Augmented Generation-based Chatbots》
探讨了用检索增强生成(RAG)管道和大语言模型(LLM)开发企业级聊天机器人的挑战与方法。作者提出了 FACTS 框架,强调 RAG 管道工程中的实时性、架构、成本、测试和安全性。经验研究指出,LLM 扩展时准确性与延迟之间的权衡,为构建安全高性能机器人提供了有益见解。点击阅读论文。
Subash Neupane 等人(2024)《From Questions to Insightful Answers: Building an Informed Chatbot for University Resources》
介绍了 BARKPLUG V.2 聊天机器人,专为高校场景设计。系统通过 RAG 管道为用户提供准确、领域相关的校园资源解答,提升了信息获取效率。研究通过 RAG Assessment(RAGAS)等方法评估了机器人的有效性,展示了其在学术环境下的可用性。点击阅读论文。
检索管道是一种技术架构,使聊天机器人能够根据用户提问,从外部来源获取、处理和检索相关信息。它融合了数据摄取、嵌入生成、向量存储和大语言模型(LLM)回复生成,实现动态、具备上下文感知的回答。
RAG 结合了数据检索系统和大型语言模型(LLM)的优势,使聊天机器人能够以真实、最新的外部数据为基础生成回复,从而减少幻觉、提升准确性。
关键组成包括文档摄取、预处理、嵌入生成、向量存储、查询处理、数据检索、回复生成以及后处理验证。
应用场景包括客户支持、企业知识管理、电商产品信息、医疗健康指导、教育与科研,以及法律合规协助等。
挑战包括实时检索带来的延迟、运营成本高、数据隐私问题,以及应对大规模数据需求的可扩展性。
一个实时聊天机器人,使用仅限于您自有域名的Google搜索,检索相关的网页内容,并利用OpenAI LLM为用户提供最新的信息答案。非常适合在客户支持或信息门户中提供准确、特定领域的响应。...
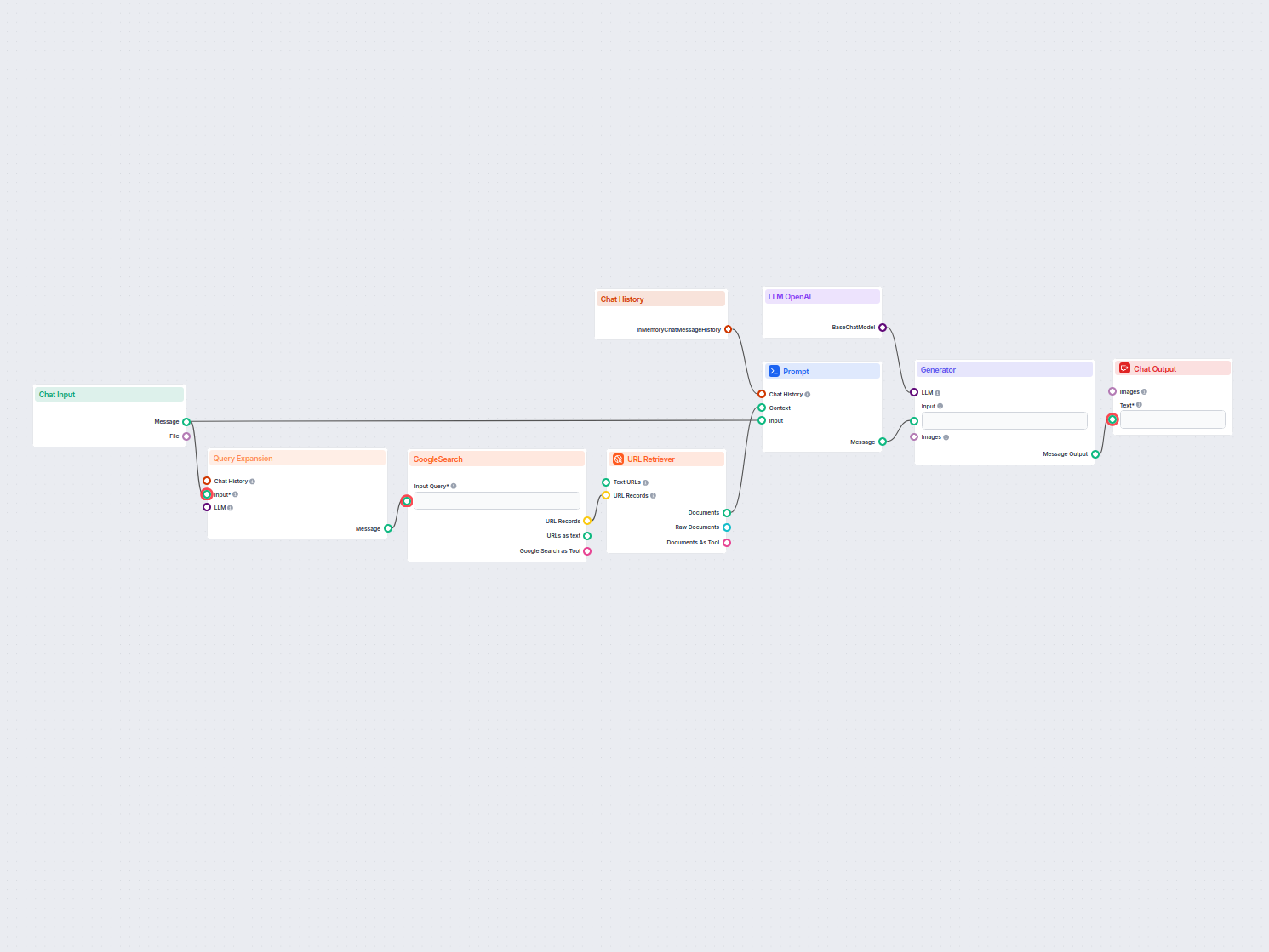
利用 AI 驱动的语义搜索,轻松检索和查找私人知识库文档中的信息。该流程会扩展用户查询,跨多个知识源进行搜索,并以用户友好的聊天界面呈现相关结果。...
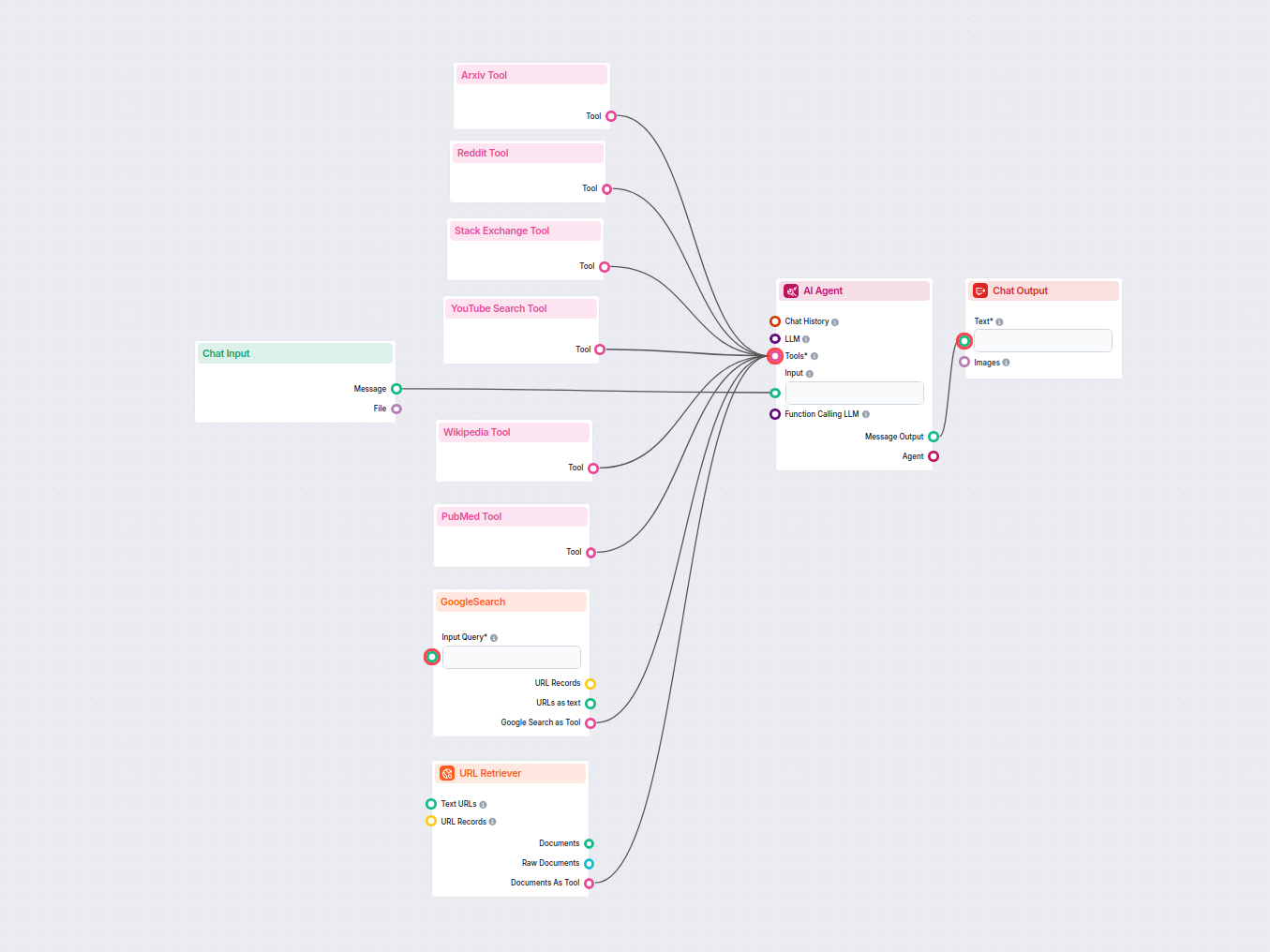
一款强大的AI聊天机器人,可通过检索和整合来自Google、Reddit、Wikipedia、Arxiv、Stack Exchange、YouTube、PubMed及网站URL的信息,实时解答用户问题,并提供有来源支持的答案,适用于科研、学习或一般查询。...