大型语言模型(LLM)
大型语言模型(LLM)是一种通过海量文本数据训练的人工智能,能够理解、生成和处理人类语言。LLM 利用深度学习和 Transformer 神经网络,驱动文本生成、摘要、翻译等多种任务,广泛应用于各行各业。...
1 分钟阅读
AI
Large Language Model
+4
大型语言模型(LLMs)文本生成,是指利用先进的机器学习模型,根据输入提示生成类人文本的复杂技术。LLM是一类专门设计用于理解、解释和生成自然语言的AI模型。这些模型采用被称为transformer的特定架构,能够高效处理海量数据,并生成连贯且符合语境的文本。
大型语言模型是通过大规模数据集训练的深度学习模型,能够预测和生成文本。它们的架构通常包含能够处理复杂语言模式和词语关系的编码器和解码器。transformer作为一种神经网络架构,是这类模型的核心,使其能够并行处理输入序列,在效率上大大超越早期的循环神经网络(RNNs)。
大型语言模型利用庞大的数据集,并拥有巨量参数,类似于模型在学习过程中构建的知识库。这些模型不仅能完成语言相关任务,还可扩展到理解蛋白质结构或编写软件代码等复杂任务。它们是众多NLP应用(如翻译、聊天机器人和AI助手)的基础。
文本生成是指通过预测下一个token(文本单元),基于给定输入创作新文本内容。这可以包括补全句子、撰写文章、生成代码或在聊天机器人中创建对话。文本生成是LLM的一项基础任务,展现了模型对语言与语境的理解能力。
transformer通过自注意力等机制,衡量句子中不同单词的重要性。这使其能够捕捉文本中的长距离依赖关系,在语言理解和生成任务中表现出色。
transformer模型通过对输入进行分词,并进行数学运算以发现token间的关系。其自注意力机制让模型能够综合考虑整个句子上下文进行预测,比传统模型学习速度更快,能捕捉输入文本的语义和句法信息。
解码策略在文本生成中至关重要,决定模型在生成过程中如何选择下一个token。常见策略包括:
微调是指在特定数据集上,对预训练LLM进一步训练,使其适应特定任务或领域,如客户服务聊天机器人或医疗诊断系统。这可使模型为特定应用生成更相关、准确的内容。
微调提升模型在特定任务上的表现,增强其在不同场景下生成合适输出的能力。该过程通常结合few-shot或zero-shot提示等技术,引导模型执行任务相关的活动。
自回归模型通过每次预测一个token,并将其作为下一个预测的输入,如此迭代,直到达到预定终止点或生成结束标记。
LLM被广泛用于聊天机器人,实时生成类人回应,提升用户互动体验,提供个性化客户服务。
LLM助力博客、文章和营销文案的生成,帮助内容创作者节省时间精力,保证风格一致性和连贯性。
LLM可实现跨语种文本翻译及长文档的精炼摘要,促进跨语言交流和信息处理。
如OpenAI的Codex等模型可根据自然语言提示生成编程代码,协助开发者自动化重复性编码任务。
LLM可用于诗歌、故事等创意写作,为作者提供灵感和辅助。
确保LLM生成的文本遵循特定安全与伦理规范尤为关键,尤其在新闻生成或客户支持等场景,错误或不当内容可能带来严重后果。
LLM可能无意中学习并传播训练数据中的偏见。解决这些问题需精心策划数据集并进行算法调整。
尽管LLM功能强大,但在处理长文档或对话时存在上下文承载的限制。如何让模型维持长距离上下文仍是一项计算挑战。
训练和部署LLM需消耗大量计算资源,这对中小型组织构成障碍。
随着持续进步,LLM将变得更高效、更强大,准确性提升、偏见减少。研究者正探索将多模态数据(文本、图像、音频)整合入LLM,并提升其可解释性与可扩展性。随着模型演进,必将持续改变人机交互与各行业信息处理方式。
凭借LLM的能力,各行业可创新并提升服务水准,在自动化、内容创作和人机交互等方面取得显著进步。
关于大型语言模型文本生成的研究
大型语言模型(LLMs)文本生成是自然语言处理领域快速发展的分支,推动了人机交互的进步。了解其关键要素、工作原理与应用现状!以下是该领域部分重要研究成果:
基于逻辑图的大型语言模型指令生成规划(发表于:2024-07-05)——Fan Zhang等人探讨了使用LLM生成逻辑连贯文本的挑战。作者提出Logical-GLM,一种新型基于图的语言模型,将逻辑推理融入文本生成。通过从自然语言指令构建逻辑Bayes图并指导模型训练,该方法提升了生成文本的逻辑有效性和可解释性。研究表明,Logical-GLM即使在训练数据有限时,也能生成逻辑严谨且高效的指令文本。阅读全文。
面向手语词汇翻译的领域文本生成扩展反向翻译(发表于:2023-02-07)——Jinhui Ye等探讨了手语词汇翻译中的数据稀缺问题,提出基于Prompt的领域文本生成(PGEN)方法。PGEN利用如GPT-2等预训练语言模型,生成大规模领域内口语文本,增强反向翻译过程。结果显示,翻译质量显著提升,证明了生成文本在突破数据瓶颈方面的有效性。阅读全文。
利用大型语言模型实现文本复述(发表于:2019-11-21)——Sam Witteveen与Martin Andrews提出了利用GPT-2等LLM进行文本复述的技术。该方法支持对句子、段落等不同长度文本生成高质量复述,无需将文本拆分为更小单元。研究突显了LLM在内容优化与表达多样化方面的灵活性。阅读全文。
大型语言模型增强的Text-to-SQL生成综述(发表于:2024-10-08)——Xiaohu Zhu等综述了LLM在自然语言查询到SQL指令翻译中的应用。该能力让用户通过自然语言与数据库交互,简化了复杂数据检索过程。论文回顾了利用LLM提升Text-to-SQL生成的最新进展,强调其对数据库交互方式的变革潜力。阅读全文。
大型语言模型(LLMs)文本生成是指利用先进的机器学习模型,从提示中生成类人文本。这些模型借助transformer架构,能够理解、解释并生成连贯的语言,用于多种应用场景。
文本生成用于聊天机器人、虚拟助手、博客及营销内容创作、翻译、摘要、代码生成和创意写作等领域。
挑战包括对模型输出的安全与伦理控制,缓解训练数据中的偏见,管理上下文限制,以及处理高计算资源需求。
transformer通过自注意力机制捕捉词语间关系,实现大规模数据集的高效处理,并生成语境相关、连贯的文本。
微调是指在特定数据集或任务上对预训练的LLM进行进一步训练,使其能为专业应用生成更相关、更准确的内容。
大型语言模型(LLM)是一种通过海量文本数据训练的人工智能,能够理解、生成和处理人类语言。LLM 利用深度学习和 Transformer 神经网络,驱动文本生成、摘要、翻译等多种任务,广泛应用于各行各业。...
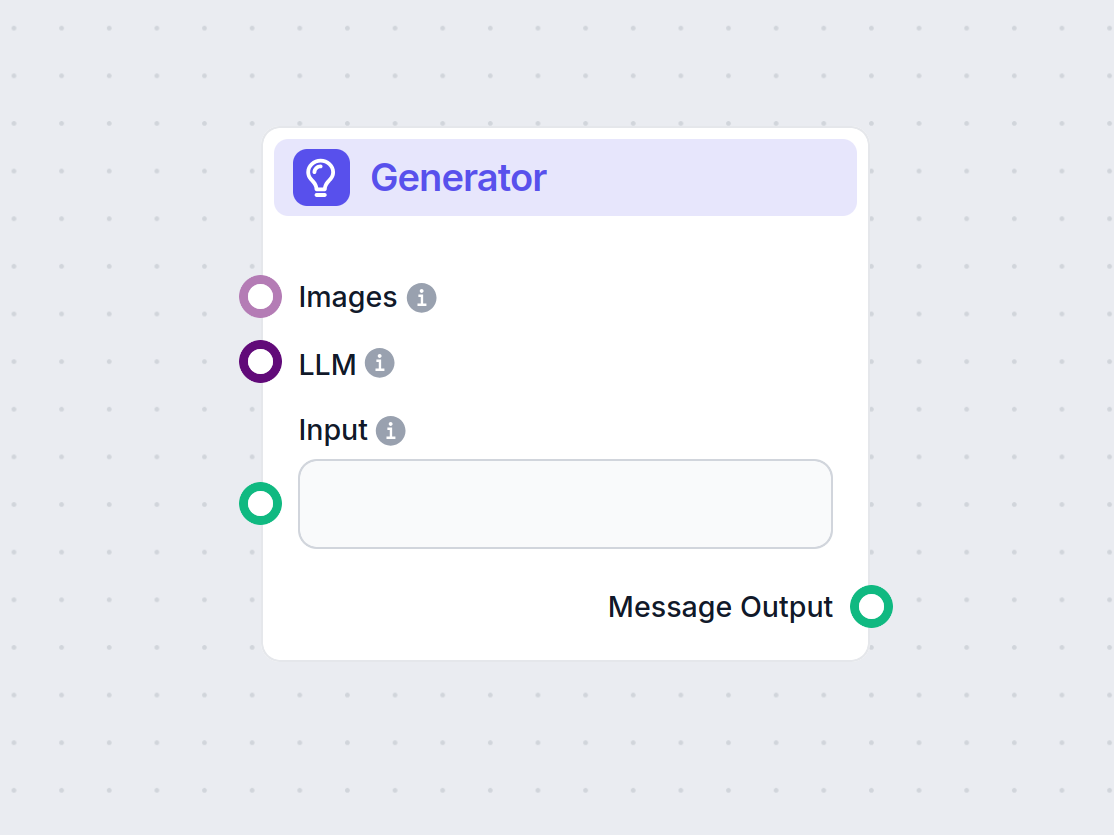
探索 FlowHunt 的生成器组件——利用您选择的 LLM 模型进行强大的 AI 驱动文本生成。通过结合提示词、可选的系统指令,甚至图片作为输入,轻松创建动态聊天机器人回复,使其成为构建智能对话流程的核心工具。...
文本摘要是人工智能中的一项重要过程,可将冗长的文档提炼为简明扼要的摘要,同时保留关键信息和意义。通过利用 GPT-4 和 BERT 等大型语言模型,实现了通过抽象、抽取及混合方法对海量数字内容的高效管理与理解。...