跳过内容索引
通过 FlowHunt 的跳过索引功能提升您的 AI 聊天机器人的准确性。排除不适合的内容,确保互动相关且安全。使用 flowhunt-skip 类控制哪些内容被索引,提升机器人可靠性和性能。...
1 分钟阅读
AI
Chatbot
+4
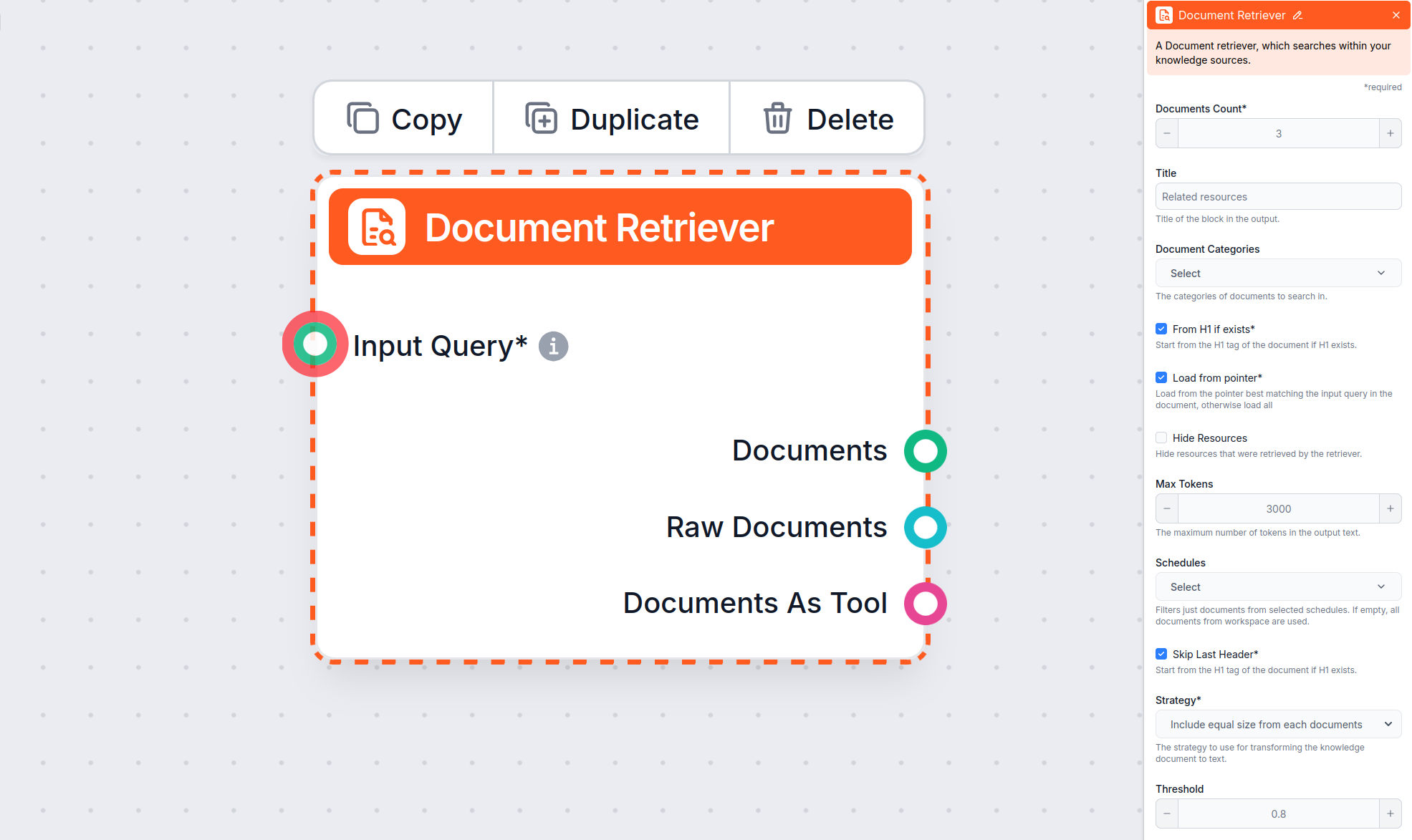
了解如何设置“如有则从 H1 开始”、“从指针加载”和“跳过最后一个标题”参数。
文档检索器组件 允许聊天机器人从您在文档和计划中指定的来源检索知识。该组件的作用是控制检索过程,多个参数会影响组件如何从这些文档中获取信息。
如有则从 H1 开始选项会指示检索器从它找到的 H1 标题(通常是文章的主标题)开始提取内容。
会发生什么?
用例示例:
您只想检索实际的指南内容,而不包括网站存在的任何导航或页面头部杂乱内容。
注意:
文档检索器组件默认启用如有则从 H1 开始。
从指针加载选项让您可以更精确地让文档检索器仅从长文章中的一个指针开始加载数据。
会发生什么?
什么是“指针”?
指针通常是文档中存在的唯一字符串或标题(例如,一个 H2 或特定短语或章节标题)。
用例示例:
您想跳过引言部分,只检索某个相关章节的信息(例如,在设置指南中从“步骤 4:添加实时聊天按钮”开始)。
跳过最后一个标题选项可用于忽略文档中的最后一个标题,这通常是重复出现或用于导航或页脚的标题。
会发生什么?
用例示例:
您希望文档检索器不要加载页脚导航标题(如帮助页面末尾的“其他文章”),确保只处理主要内容。
注意:
跳过最后一个标题有助于处理自动生成页脚或重复导航元素的文档。但如果您的文档没有这些部分,使用该参数可能导致包含有效信息的文章部分未被检索。因此,建议在有合理理由启用时再勾选此选项。
最大 tokens参数允许您控制文档检索器从提取文本中输出的最大 token(单词和标点符号,由底层 AI 模型计数)数量。
会发生什么?
默认值:
默认通常为 3000 tokens,如有需要可以调整。
用例示例:
如果您正在处理较长文档,设置较低的最大 tokens 值有助于保持回答简洁。但为了获得最佳效果,建议同时启用“从指针加载”参数。这样可确保提取的文本从文档中最相关的部分开始,而不是从开头,从而在您指定的 token 限制内获得聚焦且易于管理的信息片段。这种组合在需要从大型来源获得简洁且有上下文的输出时尤其有用。
注意:
如果发现信息被截断,可以尝试增加最大 tokens 值。相反,如需更短、更聚焦的输出,则可减少最大 tokens 参数。
免费获取最新提示、趋势和优惠。
当文档检索器找到多个相关文档时,策略参数决定如何将它们合并为您的聊天机器人的单个文本输出,同时遵循“最大 tokens”限制。
两种策略选项:
每个文档均等分配 token:
token 限制会被平均分配。例如,3 个文档、3000 token 限制下,每个可获得最多 1000 token。这确保所有来源均有贡献,当您希望答案均衡地来自多个文档时很有用。
拼接文档,按相关性依次填满 token 限制:
文档会按相关性顺序添加,直到 token 限制用尽。最相关的文档优先填充空间;如有剩余,则依次添加相关性较低的文档。如果第一个文档很长,可能会独占所有 token 限制。
如何选择?
注意:
这些策略只影响将检索到的文档内容如何构建为文本(在传递到下一步如 AI 生成前)。它们不会改变检索哪些文档——仅影响其内容如何合并与修剪以适应最大 token 设置。
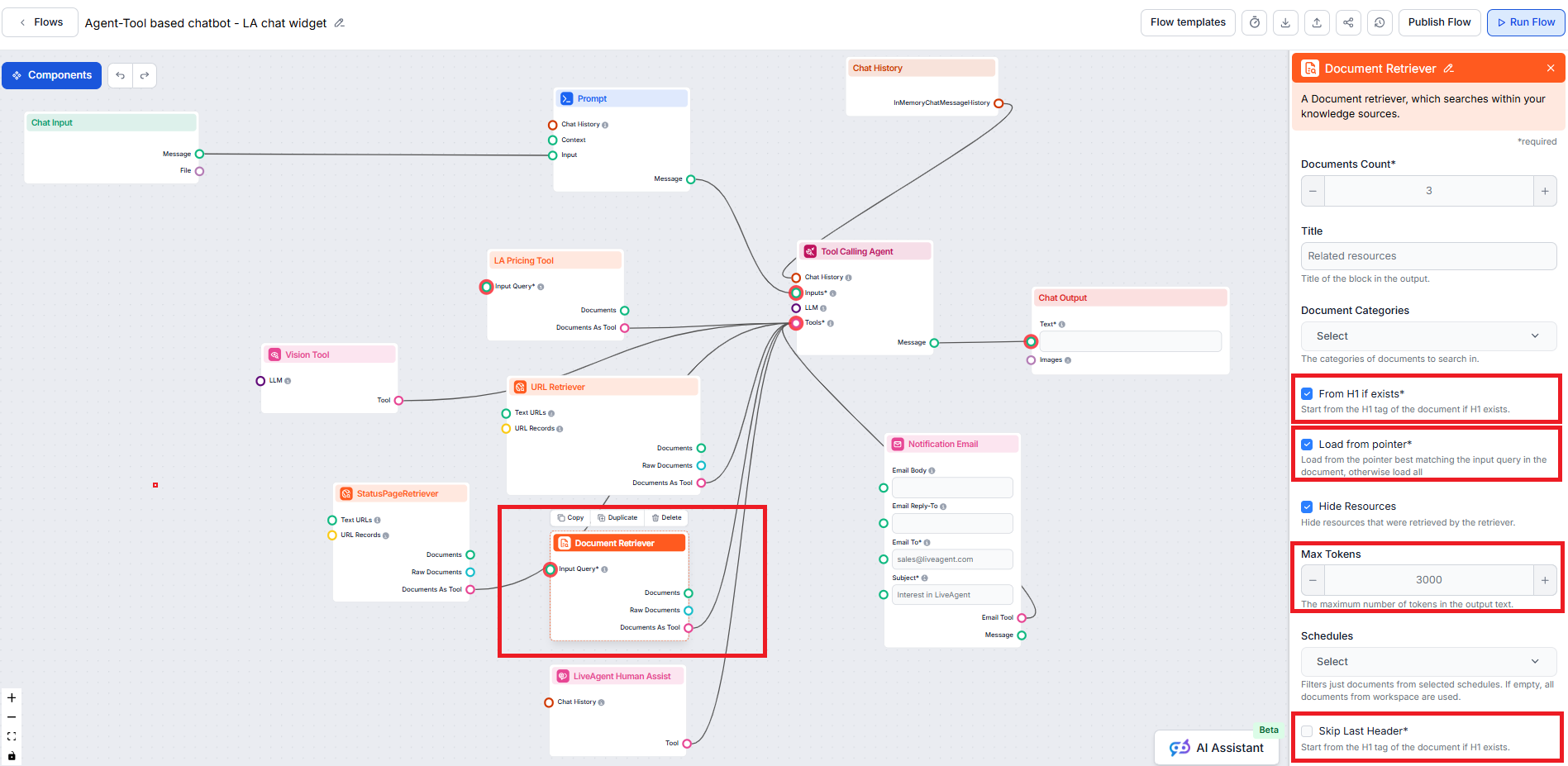
本文重点讲解了“如有则从 H1 开始”、“从指针加载”、“跳过最后一个标题”以及“最大 tokens”参数,文档检索器还提供了其他有助于控制文档选择和检索的参数:
此设置限制流程应检索的文档数量,确保结果相关且响应快速生成。
此可选设置允许您将检索范围限制在知识源的文档部分创建的一个或多个类别内。
允许您在实际聊天机器人答案前,包含或隐藏一个单独的部分,列出检索器检索到的资源。与 LiveAgent 集成时必须勾选此项,因为该部分不受支持且不会在 LiveAgent 聊天机器人小部件中正确显示。
允许您将检索限制在已为知识源内容爬取或更新而指定的一个或多个计划内。
控制检索到的文档与输入查询的匹配度,使用相关性分数(0 到 1)。例如,建议将阈值设置在 0.7–0.8 以获得高度相关的答案。阈值越高,匹配越精确,阈值越低,可能包含相关性较低的文档。
示例:
如果您将阈值设为 0.6,且有四篇文章相关性分数分别为 0.8、0.65、0.5 和 0.9,则只有高于 0.6 的(即 0.8、0.65 和 0.9)会被用于提取。
如果聊天机器人给出的答案没有包含您确定已在文档或计划中的信息,请尝试在会话历史中勾选“详细”选项,以查看文档检索器是否被使用以及检索了哪些文档的详细日志。如有需要,请根据这些日志调整您的设置和提示词。
通过 FlowHunt 的跳过索引功能提升您的 AI 聊天机器人的准确性。排除不适合的内容,确保互动相关且安全。使用 flowhunt-skip 类控制哪些内容被索引,提升机器人可靠性和性能。...

详细指南,教你如何仅将 docs.cpanel.net 的指定部分导入 FlowHunt 聊天机器人,让其专注于特定 cPanel 主题,而无需导入整个文档门户。...
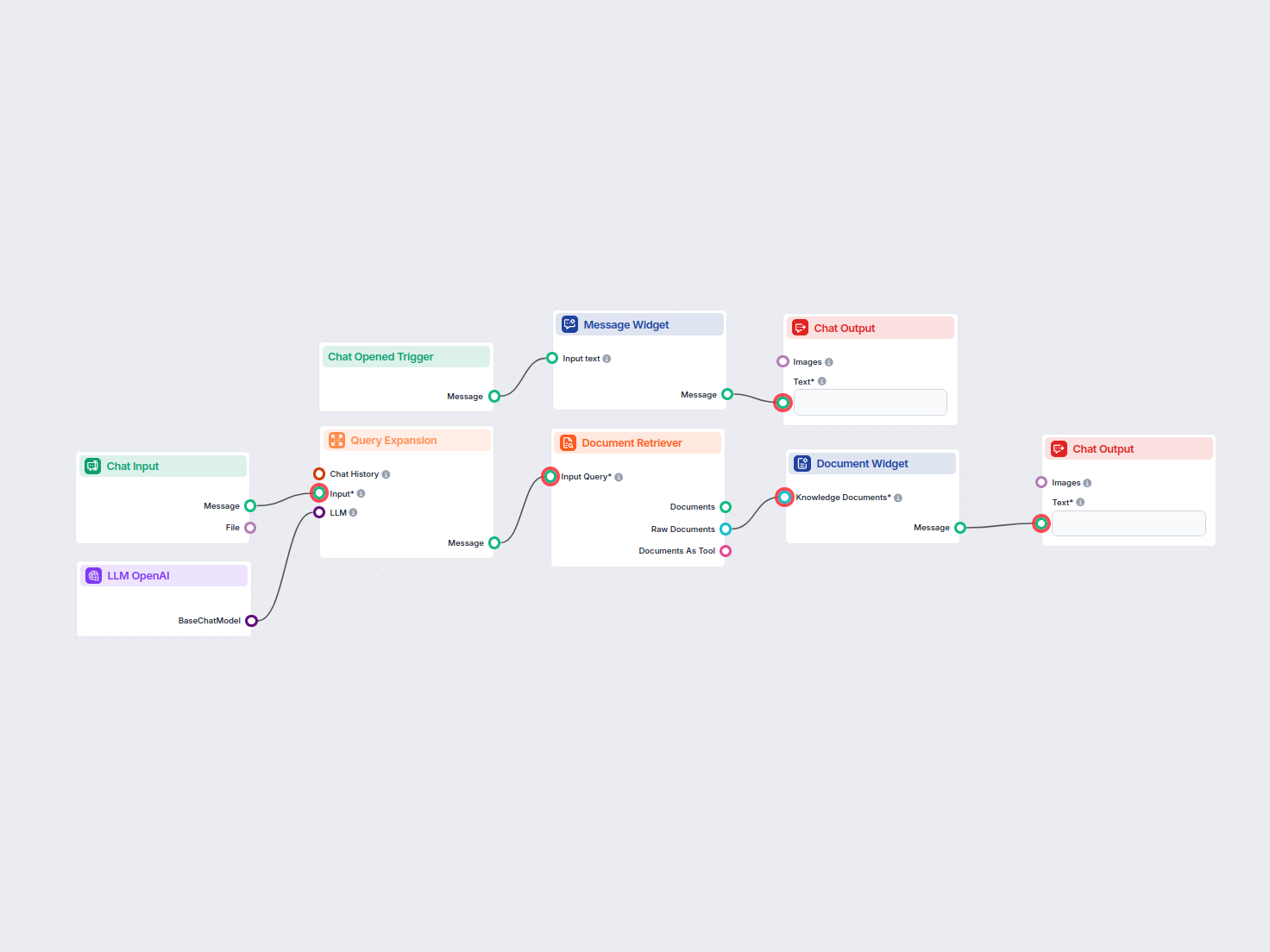
利用 AI 驱动的语义搜索,轻松检索和查找私人知识库文档中的信息。该流程会扩展用户查询,跨多个知识源进行搜索,并以用户友好的聊天界面呈现相关结果。...