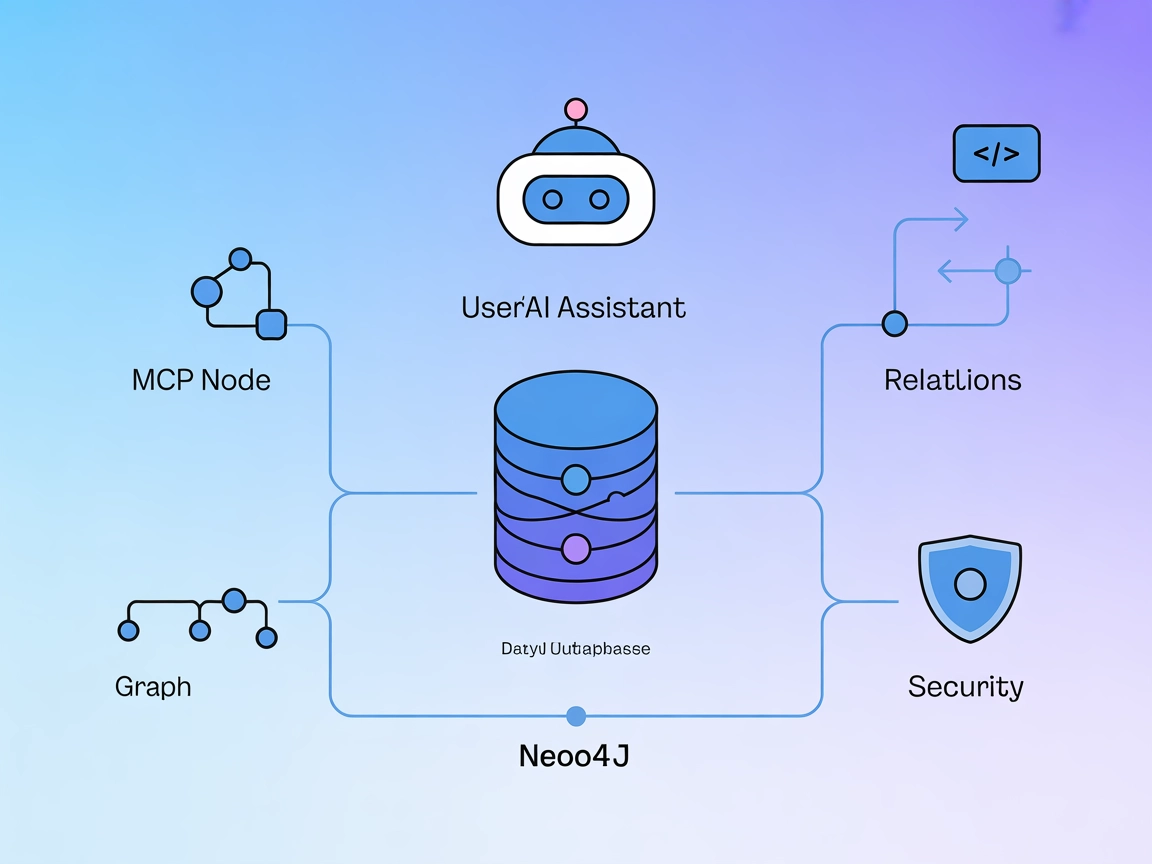
Neo4j MCP 服务器集成
Neo4j MCP 服务器为 AI 助手与 Neo4j 图数据库架起桥梁,实现安全、自然语言驱动的图操作、Cypher 查询以及自动化数据管理,可直接在 FlowHunt 等 AI 驱动环境中使用。...
2 分钟阅读
AI
Graph Database
+5
Neo4j MCP 服务器为 AI 助手与 Neo4j 图数据库架起桥梁,实现安全、自然语言驱动的图操作、Cypher 查询以及自动化数据管理,可直接在 FlowHunt 等 AI 驱动环境中使用。...
NASA MCP服务器为AI模型和开发者提供了一个统一接口,访问超过20个NASA数据源。它标准化了NASA科学和影像数据的检索、处理与管理,实现了科研、教育与探索工作流的无缝集成。...
MCP 代码执行器 MCP 服务器使 FlowHunt 及其他由 LLM 驱动的工具能够在隔离环境中安全地执行 Python 代码,管理依赖,并动态配置代码执行上下文。非常适合自动化代码评估、可复现的数据科学工作流以及在 FlowHunt 流程中动态环境设置。...
Reexpress MCP 服务器为大语言模型(LLM)工作流引入统计验证。通过相似度-距离-幅值(SDM)估算器,提供对 AI 输出结果的稳健置信度估计、自适应验证和安全文件访问——让开发者和数据科学家能够获得可靠、可审计的 LLM 响应。...
数据探索 MCP 服务器将 AI 助手与外部数据集连接,实现交互式分析。它使用户能够探索 CSV 和 Kaggle 数据集,生成分析报告并创建可视化图表,从而简化数据驱动的决策过程。...
Databricks Genie MCP 服务器通过 Genie API 让大语言模型能够与 Databricks 环境交互,支持对话式数据探索、自动 SQL 生成,以及通过标准化的 Model Context Protocol (MCP) 工具获取工作区元数据。...
JupyterMCP 通过模型上下文协议(MCP)实现 Jupyter Notebook(6.x)与 AI 助手的无缝集成。利用 LLM 自动执行代码、管理单元格和获取输出,简化数据科学工作流程并提升生产力。...
AI数据分析师将传统数据分析技能与人工智能(AI)和机器学习(ML)相结合,以提取洞见、预测趋势,并提升各行业决策效率。...
Anaconda 是一个全面的开源 Python 和 R 发行版,旨在简化科学计算、数据科学和机器学习的包管理与部署。由 Anaconda, Inc. 开发,它为数据科学家、开发者和 IT 团队提供了一个强大的平台和工具集。...
BigML 是一个旨在简化预测模型创建和部署的机器学习平台。自 2011 年成立以来,其使命是让机器学习变得人人可及、易于理解且经济实惠,提供用户友好的界面和强大的工具,以实现机器学习工作流的自动化。...
Google Colaboratory(Google Colab)是谷歌推出的基于云的 Jupyter 笔记本平台,使用户能够在浏览器中编写和执行 Python 代码,并免费访问 GPU/TPU,非常适合机器学习和数据科学。...
Jupyter Notebook 是一个开源的网页应用程序,使用户能够创建和分享包含实时代码、公式、可视化和叙述性文本的文档。它被广泛应用于数据科学、机器学习、教育和科研,支持 40 多种编程语言,并可无缝集成 AI 工具。...
k-近邻算法(KNN)是一种非参数、监督学习算法,广泛应用于机器学习中的分类和回归任务。它通过寻找距离最近的‘k’个数据点,利用距离度量和多数投票来预测结果,以其简单性和多功能性而著称。...
Kaggle 是一个在线社区和平台,供数据科学家和机器学习工程师协作、学习、竞赛和分享见解。2017 年被谷歌收购,Kaggle 成为竞赛、数据集、笔记本和教育资源的中心,推动了 AI 创新与技能发展。...
K均值聚类是一种流行的无监督机器学习算法,通过最小化数据点与其聚类中心之间的平方距离之和,将数据集划分为预定义数量的不同且不重叠的聚类。...
NumPy 是一个开源的 Python 库,对于数值计算至关重要,提供高效的数组操作和数学函数。它支持科学计算、数据科学和机器学习流程,通过实现快速、大规模的数据处理。...
Pandas 是一个开源的 Python 数据处理与分析库,以其多功能性、强大的数据结构和在处理复杂数据集时的易用性而著称。它是数据分析师和数据科学家的基石,支持高效的数据清洗、转换与分析。...
Scikit-learn 是一个功能强大的开源 Python 机器学习库,提供简单高效的工具用于预测性数据分析。被数据科学家和机器学习实践者广泛使用,它涵盖分类、回归、聚类等多种算法,并且能够无缝集成到 Python 生态系统中。...
半监督学习(SSL)是一种机器学习技术,结合有标签和无标签数据来训练模型,非常适用于全部数据都难以或成本高昂进行标注的场景。它融合了监督学习和无监督学习的优势,提高了模型的准确性和泛化能力。...
调整后的R平方是一种用于评估回归模型拟合优度的统计量,通过考虑预测变量的数量来避免过拟合,并提供对模型性能更准确的评估。...
AI分类器是一种机器学习算法,它根据从历史数据中学习到的模式,将输入数据分配到类别标签中,将信息分类到预定义的类别。分类器是AI和数据科学中的基础工具,推动着各行业的决策过程。...
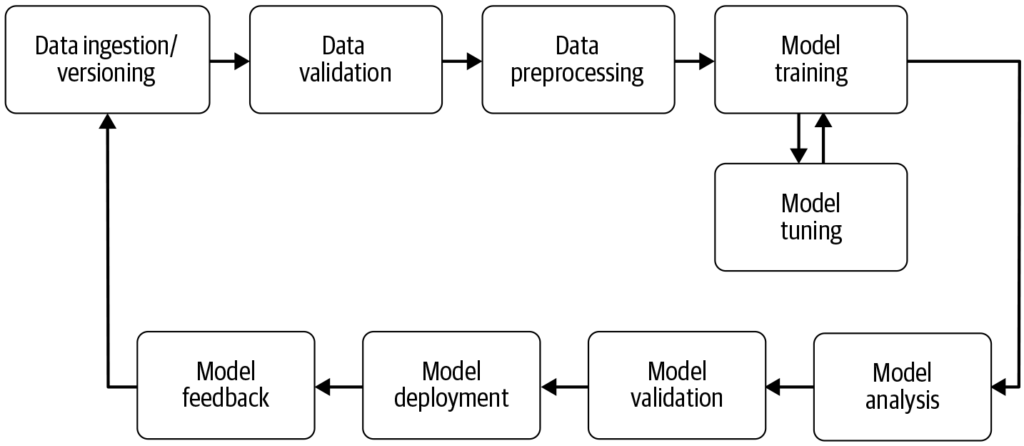
机器学习流水线是一种自动化工作流程,可高效且大规模地简化和标准化机器学习模型的开发、训练、评估与部署流程,将原始数据转化为可执行洞察。...
降维是数据处理和机器学习中的关键技术,通过减少数据集中的输入变量数量,同时保留关键信息,从而简化模型并提升性能。...
决策树是一种功能强大且直观的决策和预测分析工具,可用于分类和回归任务。其树状结构便于解释,广泛应用于机器学习、金融、医疗等领域。...
模型链是一种机器学习技术,将多个模型顺序连接,每个模型的输出作为下一个模型的输入。这种方法提升了 AI、大型语言模型(LLM)和企业应用中复杂任务的模块化、灵活性与可扩展性。...
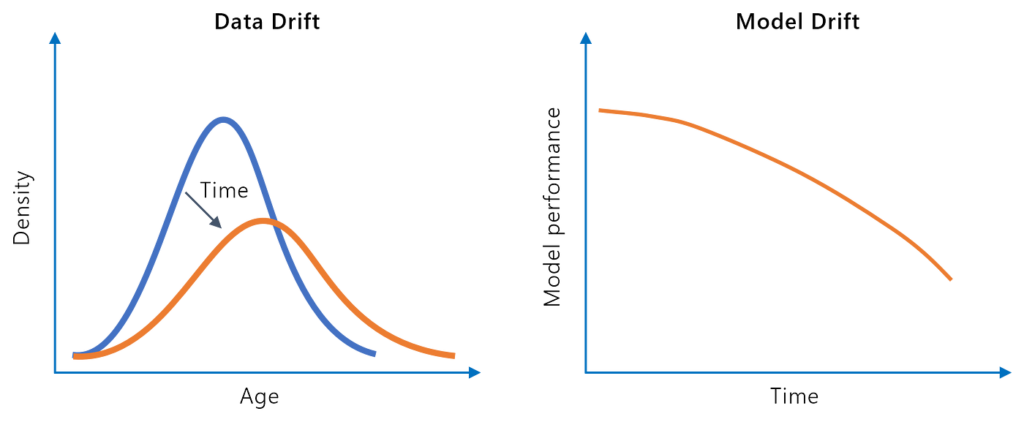
模型漂移(或称模型衰减)指的是由于现实环境变化导致机器学习模型预测性能随时间下降的现象。了解 AI 和机器学习中模型漂移的类型、成因、检测方法及解决方案。...
探索人工智能中的偏见:了解其来源、对机器学习的影响、现实案例以及缓解策略,从而构建公平且可靠的AI系统。
曲线下面积(AUC)是机器学习中用于评估二元分类模型性能的基本指标。它通过计算接收者操作特征(ROC)曲线下的面积,量化模型区分正负类别的整体能力。...
数据清洗是发现并修复数据中的错误或不一致性以提升数据质量的重要过程,确保分析和决策的准确性、一致性与可靠性。探索关键流程、挑战、工具,以及人工智能和自动化在高效数据清洗中的作用。...
数据挖掘是一种复杂的过程,通过分析大量原始数据,发掘其中的模式、关系和洞见,从而为企业战略和决策提供参考。利用先进的分析技术,它帮助组织预测趋势、提升客户体验并提高运营效率。...
探讨特征工程与特征提取如何通过将原始数据转化为有价值的洞察力来提升AI模型表现。了解特征创建、转换、主成分分析(PCA)和自编码器等关键技术,提高机器学习模型的准确性与效率。...
梯度提升是一种功能强大的机器学习集成技术,广泛应用于回归和分类任务。它通过顺序地构建模型(通常为决策树),以优化预测、提升准确率并防止过拟合。该方法在数据科学竞赛和商业解决方案中被广泛采用。...
线性回归是统计学和机器学习中最基础的分析技术之一,用于建模因变量与自变量之间的关系。因其简单性和可解释性而广受推崇,是预测分析和数据建模的基础方法。...
因果推断是一种方法论,用于确定变量之间的因果关系,在科学领域中至关重要,有助于超越相关性理解因果机制,同时应对混杂变量等挑战。...
预测建模是数据科学和统计学中一种复杂的流程,通过分析历史数据模式来预测未来结果。它利用统计技术和机器学习算法,创建用于预测金融、医疗和营销等行业趋势和行为的模型。...