LLM 作为 AI 评估的裁判
全面指南,介绍如何使用大型语言模型作为裁判来评估 AI 智能体和聊天机器人。了解 LLM 作为裁判的方法论、编写裁判提示的最佳实践、评估指标,以及如何通过 FlowHunt 工具包结合实际案例进行实践操作。...
2 分钟阅读
AI
LLM
+10
全面指南,介绍如何使用大型语言模型作为裁判来评估 AI 智能体和聊天机器人。了解 LLM 作为裁判的方法论、编写裁判提示的最佳实践、评估指标,以及如何通过 FlowHunt 工具包结合实际案例进行实践操作。...
Patronus MCP 服务器为开发者和研究人员简化了大语言模型(LLM)的评估与实验,提供自动化、批量处理和强大的 AI 系统基准测试环境,可集成于 FlowHunt。...
Root Signals MCP 服务器作为 AI 助手与 Root Signals 评估平台的桥梁,为 LLM 提供先进的自动化、遥测和工作流编排能力。集成此 MCP 可实现模型评估自动化、工作流监控和实时指标采集,提升 AI 开发的生产力与可复现性。...
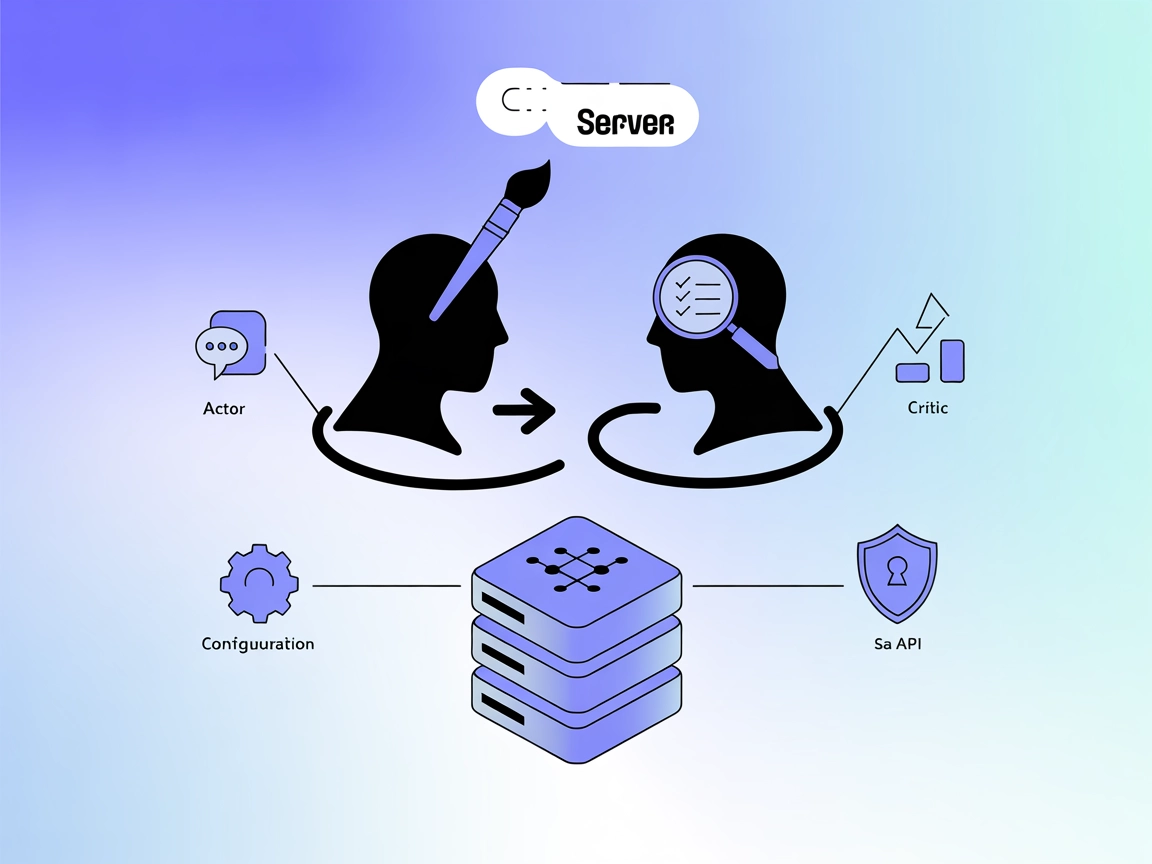
演员-评论家思维 MCP 服务器通过在“演员”(创作者)和“评论家”(评估者)角色之间切换,实现双视角绩效评估,为创意、技术和开发流程提供平衡且可执行的反馈。...
探索使用AI优缺点生成器进行内容创作、决策和产品评估的好处。了解该工具如何通过列举优点和缺点,提供平衡的视角,帮助做出明智决策。在FlowHunt上探索这款用户友好型工具的功能和优势。...
探索 Llama 3.3 70B Versatile 128k 作为 AI Agent 的高级能力。本详细评测通过多样的真实任务,考察其推理、解决问题和创造力。