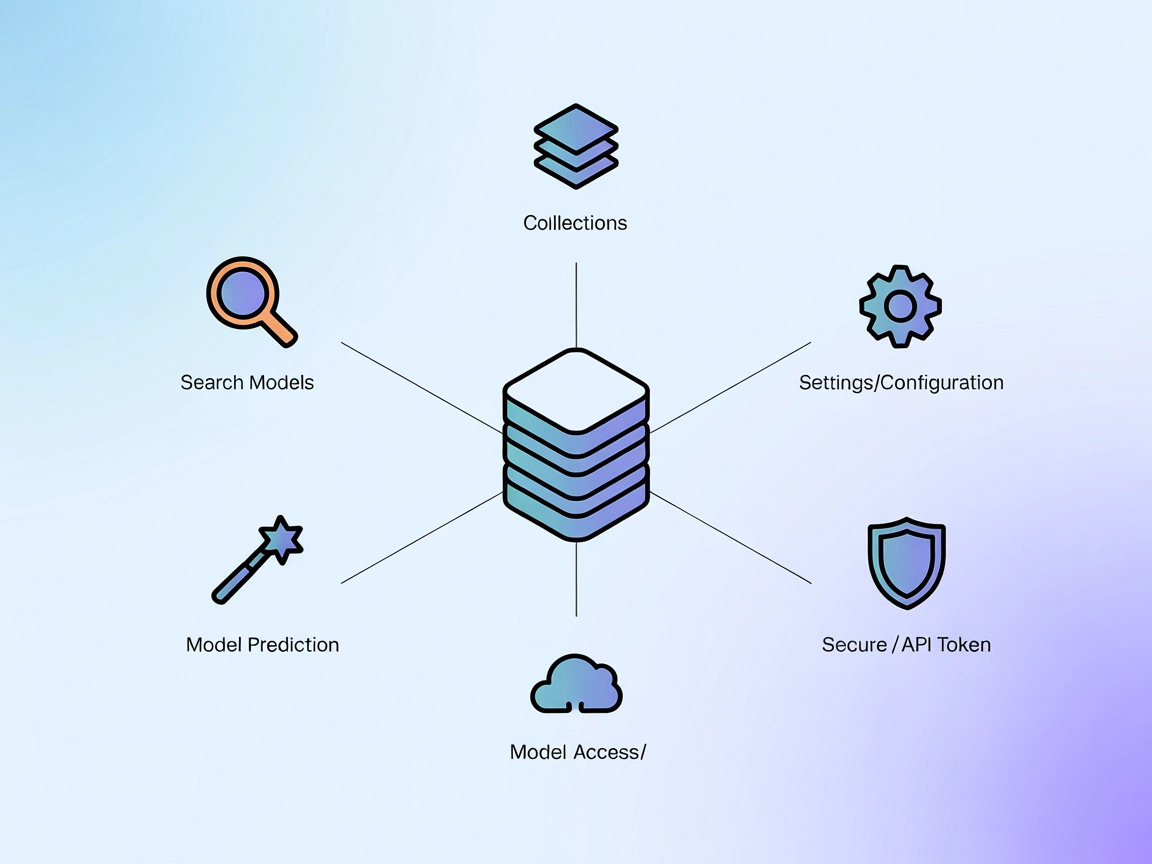
Replicate MCP 服务器集成
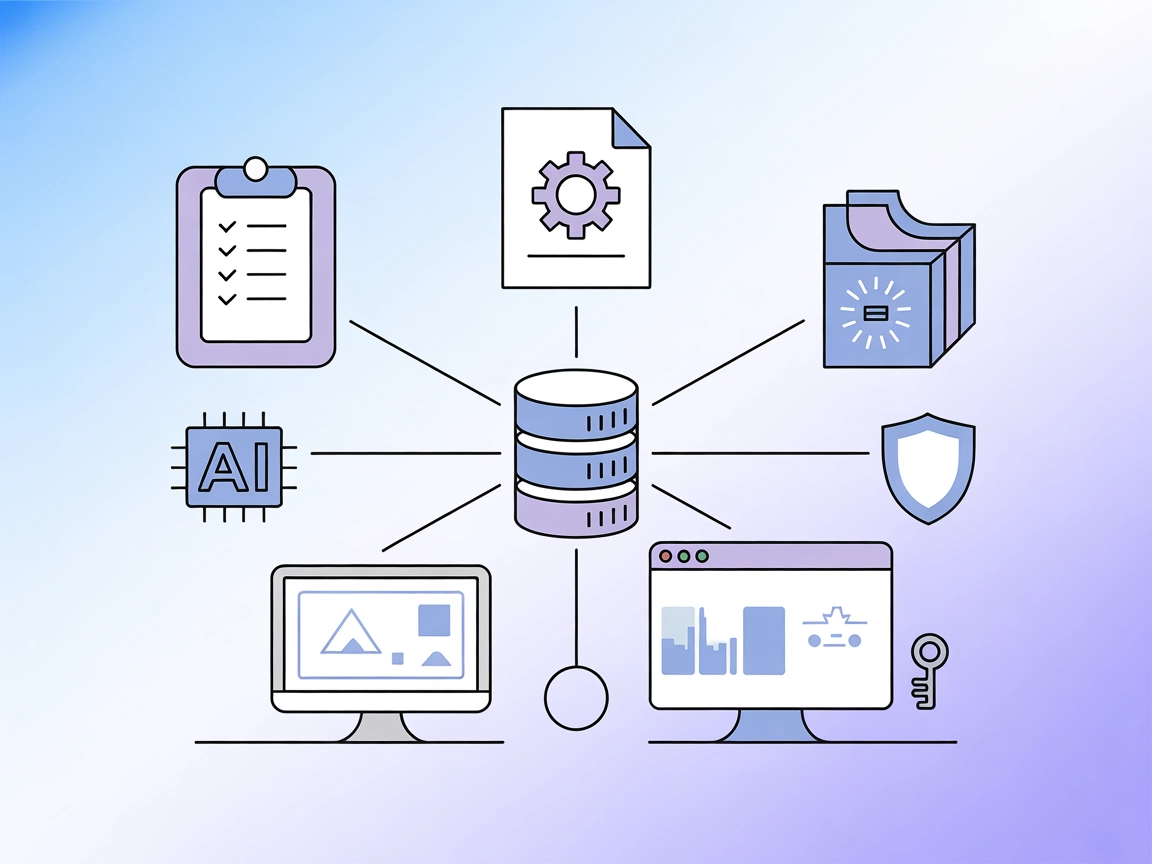
FlowHunt 的 Replicate MCP Server 连接器可无缝访问 Replicate 丰富的 AI 模型中心,使开发者能够在工作流中直接搜索、探索和运行机器学习模型。轻松将模型发现、信息检索、预测和集合管理集成到自动化流程中。...
2 分钟阅读
AI
MCP Server
+5
FlowHunt 的 Replicate MCP Server 连接器可无缝访问 Replicate 丰富的 AI 模型中心,使开发者能够在工作流中直接搜索、探索和运行机器学习模型。轻松将模型发现、信息检索、预测和集合管理集成到自动化流程中。...
使用 Label Studio MCP 服务器集成 AI 助手。通过标准化的 MCP 工具无缝管理标注项目、任务和预测,实现高效的数据标注与机器学习工作流。...
探索2025年最重要的AI趋势,包括AI智能体和AI团队的崛起,了解这些创新如何通过自动化、协作和高级问题解决能力正在改变各行各业。...
了解 Agentic AI 与多智能体系统如何通过自主决策、适应性和协作,彻底革新工作流自动化——推动医疗、电商、IT 等行业的效率、可扩展性与创新。...
了解什么是AI SDR,以及人工智能销售开发代表如何自动化潜在客户挖掘、线索筛选、外联和跟进,提升销售团队的生产力和效率。...
AI 顾问将人工智能技术与商业战略相结合,引导企业实现 AI 集成,推动创新、提升效率并促进增长。了解他们的角色、职责、所需技能,以及 AI 咨询如何改变企业。...
AI 搜索是一种语义或向量化搜索方法,利用机器学习模型理解搜索查询背后的意图和上下文含义,比传统基于关键词的搜索能够提供更相关且更准确的结果。...
了解AI模型准确性与稳定性在机器学习中的重要性。探索这些指标如何影响欺诈检测、医疗诊断和聊天机器人等应用,并学习提升AI可靠性表现的技术方法。...
AI内容创作利用人工智能自动化并提升数字内容的生成、策划与个性化,包括文本、视觉和音频。探索相关工具、优势及分步指南,助力打造高效、可扩展的内容工作流。...
AI驱动的营销利用人工智能技术,如机器学习、自然语言处理和预测分析,来自动化任务、获取客户洞察、提供个性化体验,并优化营销活动以获得更好的结果。...
AI数据分析师将传统数据分析技能与人工智能(AI)和机器学习(ML)相结合,以提取洞见、预测趋势,并提升各行业决策效率。...
了解AI系统工程师的角色:设计、开发和维护AI系统,集成机器学习,管理基础设施,并推动企业中的AI自动化。
探索AI意图分类在提升用户与技术的交互、改善客户支持、以及通过先进的自然语言处理和机器学习技术优化业务运营中的核心作用。...
AI原型开发是一种迭代设计和创建AI系统初步版本的过程,使开发者能够在全面生产前进行实验、验证和资源优化。探索各行业中的关键库、方法和应用案例。...
人工智能(AI)在网络安全中的应用利用机器学习和自然语言处理(NLP)等AI技术,通过自动化响应、数据分析和提升威胁情报,实现对网络威胁的检测、防御和响应,为数字化防御提供有力支持。...
AI质量保障专家通过制定测试计划、执行测试、发现问题并与开发者协作,确保AI系统的准确性、可靠性和性能。这个关键岗位专注于测试和验证AI模型,确认其在各种场景下按预期运行。...
AI自动化系统将人工智能技术与自动化流程集成,将学习、推理和解决问题等认知能力融入传统自动化,从而以最少的人为干预执行复杂任务。...
Amazon SageMaker 是 AWS 提供的一项全托管机器学习(ML)服务,使数据科学家和开发人员能够通过一套集成的工具、框架和 MLOps 功能,快速构建、训练和部署机器学习模型。...
Anaconda 是一个全面的开源 Python 和 R 发行版,旨在简化科学计算、数据科学和机器学习的包管理与部署。由 Anaconda, Inc. 开发,它为数据科学家、开发者和 IT 团队提供了一个强大的平台和工具集。...
Bagging,全称为自助聚合(Bootstrap Aggregating),是一种人工智能和机器学习中基础的集成学习技术,通过在自助采样的数据子集上训练多个基础模型并聚合其预测,提高模型的准确性和鲁棒性。...
了解BERT(双向编码器表示,来自Transformer),这是由谷歌开发的开源机器学习框架,专为自然语言处理而设计。探索BERT双向Transformer架构如何革新AI语言理解、其在NLP、聊天机器人、自动化中的应用及关键研究进展。...
BigML 是一个旨在简化预测模型创建和部署的机器学习平台。自 2011 年成立以来,其使命是让机器学习变得人人可及、易于理解且经济实惠,提供用户友好的界面和强大的工具,以实现机器学习工作流的自动化。...
Caffe 是 BVLC 推出的开源深度学习框架,在构建卷积神经网络(CNN)方面以速度快和模块化著称。Caffe 广泛应用于图像分类、目标检测及其他人工智能场景,具有灵活的模型配置、高速处理能力和强大的社区支持。...
Chainer 是一个开源深度学习框架,提供了灵活、直观且高性能的神经网络平台,具有动态图 define-by-run 构建、GPU 加速和广泛的架构支持。由 Preferred Networks 开发,并得到主要科技公司的技术贡献,非常适合科研、原型开发和分布式训练,但目前已进入维护阶段。...
ChatGPT 是由 OpenAI 开发的最先进 AI 聊天机器人,利用先进的自然语言处理(NLP)实现类人对话,帮助用户完成从解答问题到内容生成等任务。自 2022 年推出以来,已广泛应用于内容创作、编程、客户支持等多个行业。...
了解更多关于Anthropic的Claude 3.5 Sonnet模型:其与其他模型的对比、优势、劣势,以及在推理、编程和视觉等领域的应用。
Clearbit 是一款强大的数据激活平台,帮助企业,特别是销售和市场团队,丰富客户数据,实现营销个性化,并利用实时全面的 B2B 数据和 AI 驱动的自动化优化销售策略。...
DataRobot 是一个全面的 AI 平台,简化了机器学习模型的创建、部署和管理,使预测性和生成式 AI 对各类技术水平的用户都变得易于使用。...
DL4J(DeepLearning4J)是一个开源的、分布式的深度学习库,适用于 Java 虚拟机(JVM)。作为 Eclipse 生态系统的一部分,它支持使用 Java、Scala 及其他 JVM 语言进行可扩展的深度学习模型开发与部署。...
Dropout 是一种在人工智能,尤其是神经网络中应用的正则化技术,通过在训练过程中随机禁用神经元,促进特征学习的鲁棒性,并提升对新数据的泛化能力,从而抑制过拟合。...
F-分数,也称为F-度量或F1分数,是一种用于评估测试或模型准确性的统计指标,尤其适用于二元分类。它在精确率和召回率之间取得平衡,能够全面反映模型的表现,特别适用于数据集类别分布不均衡的情况。...
由 Black Forest Labs 推出的 Flux AI 模型是一套先进的文本到图像生成系统,可将自然语言提示通过复杂的机器学习算法转化为高度细致、逼真的图像。...
Gensim 是一个流行的开源 Python 自然语言处理(NLP)库,专注于无监督主题建模、文档索引和相似性检索。它高效处理大规模数据集,支持语义分析,被广泛应用于文本挖掘、分类和聊天机器人等研究与工业领域。...
Google Colaboratory(Google Colab)是谷歌推出的基于云的 Jupyter 笔记本平台,使用户能够在浏览器中编写和执行 Python 代码,并免费访问 GPU/TPU,非常适合机器学习和数据科学。...
Horovod 是一个强大的开源分布式深度学习训练框架,旨在实现多 GPU 或多机器间的高效扩展。它支持 TensorFlow、Keras、PyTorch 和 MXNet,优化了机器学习模型训练的速度与可扩展性。...
Hugging Face Transformers 是领先的开源 Python 库,使在自然语言处理、计算机视觉和音频处理等机器学习任务中实现 Transformer 模型变得轻松。它提供数千个预训练模型的访问,并支持如 PyTorch、TensorFlow 和 JAX 等主流框架。...
Jupyter Notebook 是一个开源的网页应用程序,使用户能够创建和分享包含实时代码、公式、可视化和叙述性文本的文档。它被广泛应用于数据科学、机器学习、教育和科研,支持 40 多种编程语言,并可无缝集成 AI 工具。...
k-近邻算法(KNN)是一种非参数、监督学习算法,广泛应用于机器学习中的分类和回归任务。它通过寻找距离最近的‘k’个数据点,利用距离度量和多数投票来预测结果,以其简单性和多功能性而著称。...
Kaggle 是一个在线社区和平台,供数据科学家和机器学习工程师协作、学习、竞赛和分享见解。2017 年被谷歌收购,Kaggle 成为竞赛、数据集、笔记本和教育资源的中心,推动了 AI 创新与技能发展。...
Keras 是一个功能强大且用户友好的开源高级神经网络 API,由 Python 编写,可运行于 TensorFlow、CNTK 或 Theano 之上。它支持快速实验,并以模块化和简洁性强力支持生产和科研场景。...
KNIME(康斯坦茨信息挖掘器)是一款强大的开源数据分析平台,提供可视化工作流、无缝数据集成、先进分析和自动化,适用于各行业。...
Kubeflow 是一个基于 Kubernetes 的开源机器学习(ML)平台,简化了 ML 工作流的部署、管理和扩展。它提供了一整套涵盖 ML 全生命周期的工具,从模型开发到部署和监控,提升了可扩展性、可复现性和资源利用率。...
K均值聚类是一种流行的无监督机器学习算法,通过最小化数据点与其聚类中心之间的平方距离之和,将数据集划分为预定义数量的不同且不重叠的聚类。...
LightGBM(全称 Light Gradient Boosting Machine)是微软开发的先进梯度提升框架。专为高性能机器学习任务(如分类、排序和回归)设计,LightGBM 能高效处理大规模数据集,内存占用极低,同时保证高精度表现。...
MLflow 是一个开源平台,旨在简化和管理机器学习(ML)生命周期。它为实验跟踪、代码打包、模型管理和协作提供工具,提升了 ML 项目的可复现性、部署和生命周期控制。...
Apache MXNet 是一个开源深度学习框架,专为高效且灵活地训练和部署深度神经网络而设计。它以可扩展性、混合编程模式以及多语言支持而闻名,使研究人员和开发者能够构建先进的人工智能解决方案。...
自然语言工具包(NLTK)是一套全面的 Python 库和程序,专为符号和统计自然语言处理(NLP)而设计。在学术界和工业界广泛应用,提供分词、词干提取、词形还原、词性标注等多种工具。...
NumPy 是一个开源的 Python 库,对于数值计算至关重要,提供高效的数组操作和数学函数。它支持科学计算、数据科学和机器学习流程,通过实现快速、大规模的数据处理。...
探索NVIDIA Blackwell系统如何开启加速计算新时代,通过先进的GPU技术、人工智能与机器学习,彻底变革各行各业。了解黄仁勋的愿景,以及GPU在超越传统CPU扩展后的颠覆性影响。...
OpenAI 是一家领先的人工智能研究机构,以开发 GPT、DALL·E 和 ChatGPT 而闻名,致力于为人类创造安全且有益的通用人工智能(AGI)。...
OpenCV 是一个先进的开源计算机视觉与机器学习库,提供 2500 多种图像处理、目标检测和实时应用的算法,支持多种语言和平台。...
Pandas 是一个开源的 Python 数据处理与分析库,以其多功能性、强大的数据结构和在处理复杂数据集时的易用性而著称。它是数据分析师和数据科学家的基石,支持高效的数据清洗、转换与分析。...
Pathways 语言模型(PaLM)是谷歌推出的先进大型语言模型家族,专为文本生成、推理、代码分析和多语言翻译等多种应用而设计。PaLM 基于 Pathways 计划构建,具有卓越的性能、可扩展性和负责任的 AI 实践。...
Perplexity AI 是一款先进的 AI 驱动搜索引擎与对话工具,利用自然语言处理和机器学习,能够为用户提供带有引用的精准、具备上下文的答案。非常适合科研、学习和专业用途,它集成了多种大型语言模型和信息来源,实现了准确、实时的信息检索。...
PyTorch 是由 Meta AI 开发的开源机器学习框架,以其灵活性、动态计算图、GPU 加速和无缝的 Python 集成而著称。它广泛应用于深度学习、计算机视觉、自然语言处理和科研领域。...
Q学习是人工智能(AI)和机器学习中的一个基础概念,尤其在强化学习领域。它使智能体能够通过与环境的交互和通过奖励或惩罚获得反馈,逐步学习最优的行为,从而随着时间提升决策能力。...
接收者操作特征(ROC)曲线是一种图形表示方式,用于评估二分类器系统在不同判别阈值下的性能。该曲线起源于二战期间的信号检测理论,如今在机器学习、医学和人工智能等领域成为模型评估的重要工具。...
Scikit-learn 是一个功能强大的开源 Python 机器学习库,提供简单高效的工具用于预测性数据分析。被数据科学家和机器学习实践者广泛使用,它涵盖分类、回归、聚类等多种算法,并且能够无缝集成到 Python 生态系统中。...
SciPy 是一个强大的开源 Python 库,用于科学和技术计算。在 NumPy 的基础上,它提供了高级的数学算法、优化、积分、数据处理、可视化,并与 Matplotlib 和 Pandas 等库高度兼容,使其成为科学计算和数据分析不可或缺的工具。...
spaCy 是一个强大的开源 Python 库,专为高级自然语言处理(NLP)而设计,以其速度、效率和面向生产的特性(如分词、词性标注和命名实体识别)而闻名。...
TensorFlow 是由 Google Brain 团队开发的开源库,旨在进行数值计算和大规模机器学习。它支持深度学习、神经网络,并可在 CPU、GPU 和 TPU 上运行,简化了数据获取、模型训练和部署流程。...
Top-k准确率是一种机器学习评估指标,用于评估真实类别是否出现在前k个预测类别中,在多类别分类任务中提供了全面且宽容的衡量方式。...
Torch 是一个基于 Lua 的开源机器学习库和科学计算框架,专为深度学习和 AI 任务优化。它提供神经网络开发工具,支持 GPU 加速,并且是 PyTorch 的前身。...
OpenAI Whisper 是一款先进的自动语音识别(ASR)系统,可将语音转录为文本,支持 99 种语言,对口音和噪音有强大适应性,并且作为开源项目可灵活应用于多种 AI 场景。...
可解释人工智能(XAI)是一套旨在让人工智能模型输出结果对人类可理解的方法和流程,促进复杂机器学习系统的透明性、可解释性和责任追溯。...
XGBoost 代表极端梯度提升(Extreme Gradient Boosting)。它是一款经过优化的分布式梯度提升库,旨在高效且可扩展地训练机器学习模型,以速度快、性能高和强大的正则化功能著称。...
半监督学习(SSL)是一种机器学习技术,结合有标签和无标签数据来训练模型,非常适用于全部数据都难以或成本高昂进行标注的场景。它融合了监督学习和无监督学习的优势,提高了模型的准确性和泛化能力。...
贝叶斯网络(BN)是一种概率图模型,通过有向无环图(DAG)表示变量及其条件依赖关系。贝叶斯网络用于建模不确定性,支持推理和学习,广泛应用于医疗、人工智能、金融等领域。...
变换器是一种革命性的神经网络架构,彻底改变了人工智能,尤其是在自然语言处理领域。自2017年“Attention is All You Need”提出以来,它们实现了高效的并行处理,成为BERT和GPT等模型的基础,深刻影响了NLP、视觉等多个领域。...
财务预测是一种高级分析过程,通过分析历史数据、市场趋势及其他相关因素,预测企业未来的财务结果。它对关键财务指标进行预测,帮助做出明智决策、制定战略规划并进行风险管理。...
参数高效微调(PEFT)是一种人工智能(AI)和自然语言处理(NLP)领域的创新方法,通过仅更新大型预训练模型中一小部分参数,使其能够适应特定任务,从而降低计算成本和训练时间,实现高效部署。...
超参数调优是机器学习中的一个基本过程,通过调整学习率和正则化等参数来优化模型性能。探索如网格搜索、随机搜索、贝叶斯优化等方法。...
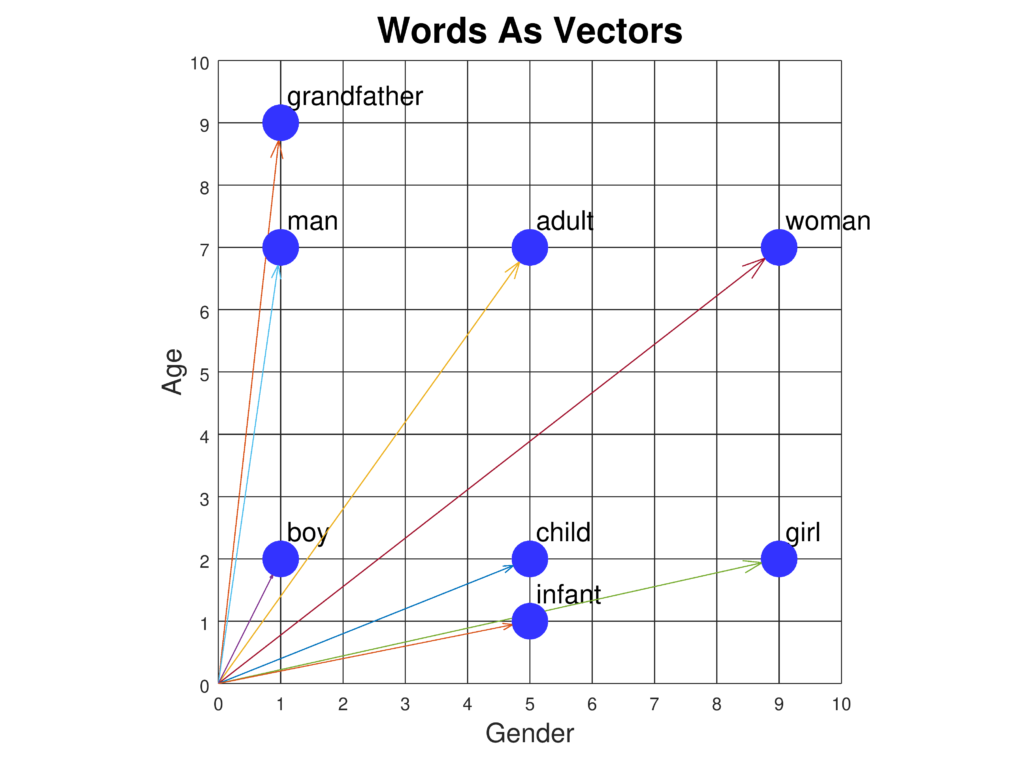
词嵌入是在连续向量空间中对单词进行高级表示的方法,能够捕捉语义和句法关系,用于文本分类、机器翻译和情感分析等高级NLP任务。...
了解如何使用 FlowHunt.io 的 API 和工作流构建器自动生成图片的描述性文本,帮助作者以一致且吸引人的内容提升在线影响力。...
了解训练和部署大型语言模型(LLM,如GPT-3和GPT-4)所涉及的成本,包括计算、能源和硬件开支,并探索管理和降低这些成本的策略。...
调整后的R平方是一种用于评估回归模型拟合优度的统计量,通过考虑预测变量的数量来避免过拟合,并提供对模型性能更准确的评估。...
了解什么是洞察引擎——一种先进的、由人工智能驱动的平台,通过理解上下文和意图提升数据搜索与分析能力。学习洞察引擎如何整合自然语言处理、机器学习和深度学习技术,从结构化和非结构化数据源中提取可操作的洞察。...
对话式人工智能指的是一系列让计算机通过自然语言处理(NLP)、机器学习等语言技术来模拟人类对话的技术。它驱动着客户支持、医疗、零售等领域的聊天机器人、虚拟助手和语音助手,提高了效率和个性化体验。...
对数损失(Log Loss),又称对数/交叉熵损失,是评估机器学习模型性能的关键指标,尤其适用于二分类,通过衡量预测概率与实际结果之间的差异,惩罚错误或过于自信的预测。...
人工智能(AI)在法律文件审查中的应用,代表了法律专业人士应对法律流程中大量文件处理方式的重大变革。通过采用机器学习、自然语言处理(NLP)和光学字符识别(OCR)等AI技术,法律行业在文件处理的效率、准确性和速度方面得到了显著提升。...
反向传播是一种通过调整权重以最小化预测误差,用于训练人工神经网络的算法。了解其工作原理、步骤以及在神经网络训练中的基本原则。...
泛化误差衡量机器学习模型对未见数据的预测能力,通过平衡偏差和方差,确保 AI 应用的稳健性与可靠性。了解其重要性、数学定义,以及减少泛化误差的有效技术,助力真实世界的成功。...
了解什么是非结构化数据,以及它与结构化数据的区别。学习非结构化数据所面临的挑战,以及常用的处理工具。
AI分类器是一种机器学习算法,它根据从历史数据中学习到的模式,将输入数据分配到类别标签中,将信息分类到预定义的类别。分类器是AI和数据科学中的基础工具,推动着各行业的决策过程。...
借助人工智能的个性化营销利用人工智能,根据客户的行为、偏好和互动,为每一位客户量身定制营销策略和沟通内容,从而提升客户参与度、满意度和转化率。...
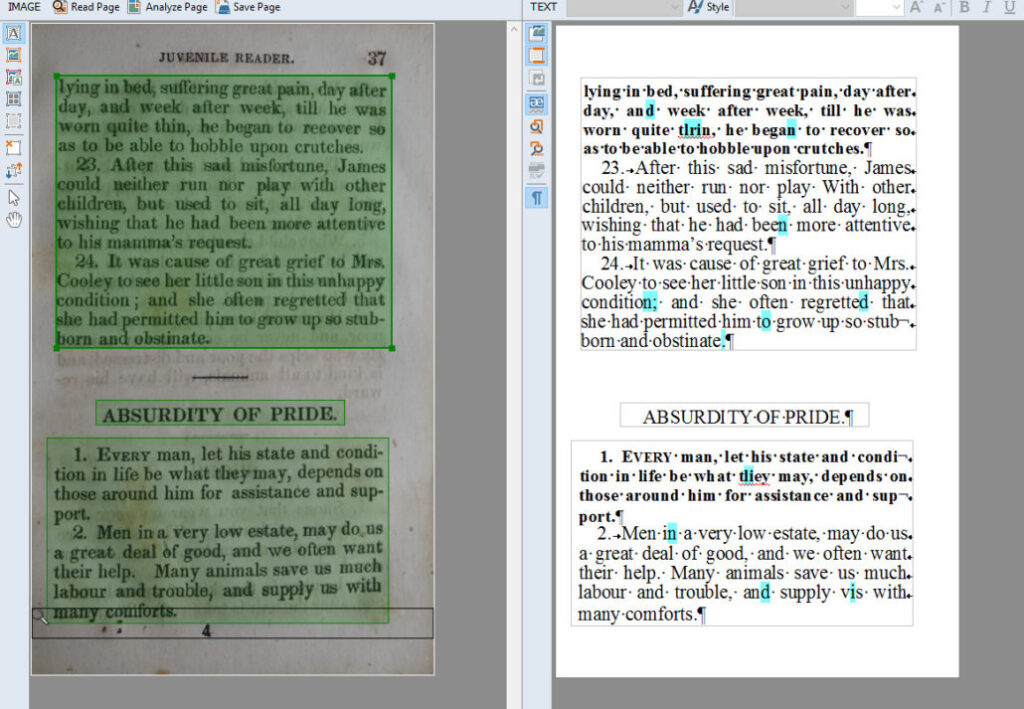
光学字符识别(OCR)是一项变革性技术,可将扫描文件、PDF或图像等文档转换为可编辑和可检索的数据。了解OCR的工作原理、类型、应用、优势、局限性,以及AI驱动OCR系统的最新进展。...
过拟合是人工智能(AI)和机器学习(ML)中的一个关键概念,指的是模型对训练数据学习过度,包括噪声,导致在新数据上泛化能力差。了解如何通过有效的技术识别并防止过拟合。...
合成数据是指通过人工生成的信息,用以模拟真实世界数据。它是利用算法和计算机仿真创建的,可作为真实数据的替代或补充。在人工智能领域,合成数据对于训练、测试和验证机器学习模型至关重要。...
混淆矩阵是机器学习中用于评估分类模型性能的工具,详细展示了真/假阳性和真/假阴性结果,能够提供超越准确率的洞察力,尤其适用于数据不均衡的场景。...
机器学习(ML)是人工智能(AI)的一个子集,使机器能够从数据中学习,识别模式,进行预测,并随着时间的推移在没有明确编程的情况下改进决策。...
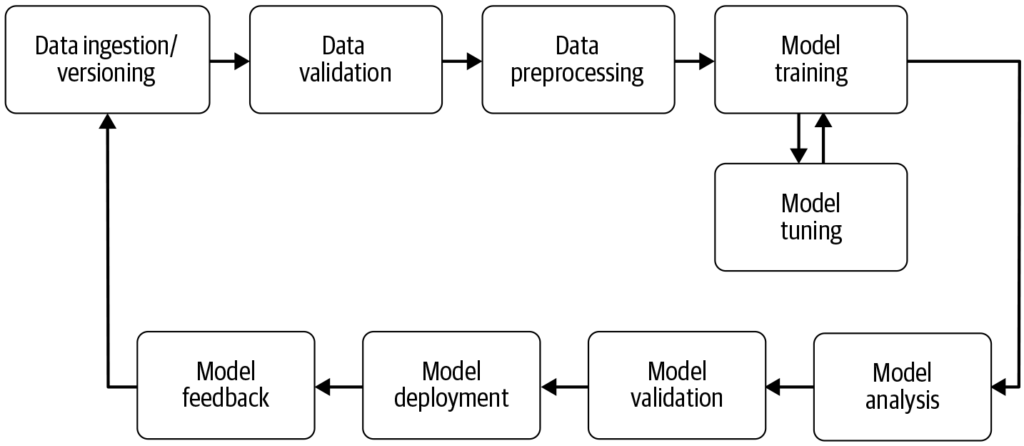
机器学习流水线是一种自动化工作流程,可高效且大规模地简化和标准化机器学习模型的开发、训练、评估与部署流程,将原始数据转化为可执行洞察。...
探索机器学习中的召回率:这是评估模型性能的重要指标,尤其在分类任务中,正确识别正例至关重要。了解召回率的定义、计算方法、重要性、应用场景及提升策略。...
基础AI模型是一种在海量数据上训练的大规模机器学习模型,能够适应广泛的任务。基础模型通过为NLP、计算机视觉等各领域的专业AI应用提供通用底座,彻底变革了人工智能。...
基于AI的学生反馈利用人工智能为学生提供个性化、实时的评估见解和建议。通过机器学习和自然语言处理,这些系统分析学术作业,以提升学习效果、提高效率,并在保障隐私和公平的同时,提供数据驱动的洞察。...
基于人类反馈的强化学习(RLHF)是一种将人类输入整合到强化学习算法训练过程中的机器学习技术。与仅依赖预定义奖励信号的传统强化学习不同,RLHF利用人类的判断来塑造和优化AI模型的行为。这种方法确保AI更贴合人类的价值观和偏好,使其在复杂和主观性较强的任务中尤为有用。...
激活函数是人工神经网络的基础,通过引入非线性特性,使其能够学习复杂的模式。本文探讨了激活函数的作用、类型、挑战以及在人工智能、深度学习和神经网络中的关键应用。...
计算机视觉是人工智能(AI)领域的一个分支,专注于让计算机能够解释和理解视觉世界。通过利用来自摄像头、视频和深度学习模型的数字图像,机器能够准确识别和分类物体,并对它们“看到”的内容做出反应。...
监督学习是机器学习和人工智能中的一种基础方法,通过让算法从带标签的数据集中学习,以实现预测或分类。了解其流程、类型、关键算法、应用和挑战。...
监督学习是一种基础的人工智能和机器学习概念,其中算法通过有标签的数据进行训练,从而能对新的、未知的数据做出准确的预测或分类。了解其关键组成部分、类型和优势。...
探索人工智能中检索增强生成(RAG)与缓存增强生成(CAG)的关键区别。了解RAG如何动态检索实时信息以实现灵活、准确的响应,而CAG则利用预缓存数据实现快速一致的输出。找出哪种方法更适合您的项目需求,并探讨实际应用场景、优势与局限性。...
显示 1 至 100 共 211 结果