
MLflow
MLflow 是一个开源平台,旨在简化和管理机器学习(ML)生命周期。它为实验跟踪、代码打包、模型管理和协作提供工具,提升了 ML 项目的可复现性、部署和生命周期控制。...
1 分钟阅读
MLflow
Machine Learning
+3
Kubeflow 是一个基于 Kubernetes 的开源机器学习(ML)平台,简化了 ML 工作流的部署、管理和扩展。它提供了一整套涵盖 ML 全生命周期的工具,从模型开发到部署和监控,提升了可扩展性、可复现性和资源利用率。
Kubeflow 的使命是借助 Kubernetes 的能力,使 ML 模型的扩展和生产部署变得尽可能简单。这包括在多样化基础设施上的轻松、可重复和可移植的部署。该平台最初作为在 Kubernetes 上运行 TensorFlow 任务的方法诞生,如今已发展成支持多种 ML 框架和工具的多功能框架。
Kubeflow Pipelines 是一个核心组件,允许用户将 ML 工作流定义并以有向无环图(DAG)的方式执行。它为基于 Kubernetes 的便携、可扩展机器学习工作流提供了平台。Pipelines 组件包括:
这些功能使数据科学家能够自动化数据预处理、模型训练、评估和部署的端到端流程,促进 ML 项目的可复现性和协作。平台支持组件与流水线的复用,从而简化 ML 解决方案的开发。
Kubeflow 中央控制台是访问 Kubeflow 及其生态系统的主要界面。它聚合了集群中各种工具和服务的用户界面,为管理机器学习活动提供统一入口。控制台还具备用户认证、多用户隔离和资源管理等功能。
Kubeflow 集成了 Jupyter Notebooks,为数据探索、实验和模型开发提供了交互式环境。Notebook 支持多种编程语言,允许用户协作创建和执行 ML 工作流。
Kubeflow Metadata 是用于追踪和管理与 ML 实验、运行以及产物相关元数据的集中存储库。它为 ML 项目提供一致的元数据视图,确保可复现性、协作和治理。
Katib 是 Kubeflow 中的自动机器学习(AutoML)组件。它支持超参数调优、提前终止和神经网络结构搜索,通过自动化寻找最优超参数,优化 ML 模型性能。
Kubeflow 广泛应用于各行业组织,以简化其 ML 运维。常见应用场景包括:
Spotify 利用 Kubeflow 支持其数据科学家和工程师大规模开发与部署机器学习模型。通过与现有基础设施集成,Spotify 优化了 ML 工作流,缩短了新功能上线时间,并提升了推荐系统的效率。
Kubeflow 允许组织根据需求灵活扩展或缩减 ML 工作流,并可在本地、云端及混合环境等多种基础设施间部署。这种灵活性有助于避免厂商锁定,实现不同计算环境间的平滑迁移。
Kubeflow 的组件化架构方便实验和模型的复现。它提供数据集、代码、模型参数的版本控制与追踪工具,保障数据科学家间的协作与一致性。
Kubeflow 设计为可扩展平台,可与多种其他工具和服务(包括云端 ML 平台)集成。组织可根据需求自定义并扩展 Kubeflow,充分利用现有工具和工作流,增强 ML 生态系统。
通过自动化 ML 工作流的部署与管理相关任务,Kubeflow 让数据科学家和工程师能够专注于模型开发与优化等高价值工作,从而提升生产效率和工作成效。
Kubeflow 与 Kubernetes 的集成提升了资源利用效率,优化了硬件资源分配,降低了运行 ML 工作负载的成本。
要开始使用 Kubeflow,用户可选择在本地或云端的 Kubernetes 集群上进行部署。官方提供多种安装指南,适配不同经验水平和基础设施需求。对于 Kubernetes 新手,Vertex AI Pipelines 等托管服务是更易入门的选择,无需关注底层基础设施,只需专注于构建和运行 ML 工作流。
本篇详尽介绍了 Kubeflow 的功能、优势及应用场景,为希望提升机器学习能力的组织提供了全面的参考。
免费获取最新提示、趋势和优惠。
Kubeflow 是一个开源项目,旨在简化在 Kubernetes 上部署、编排和管理机器学习模型。它为机器学习工作流提供了完整的端到端技术栈,让数据科学家和工程师更轻松地构建、部署和管理可扩展的机器学习模型。
在不同云服务商上使用 Kubeflow 部署 ML 模型
作者:Aditya Pandey 等(2022)
本文探讨了如何在多种云平台上通过 Kubeflow 部署机器学习模型。内容涵盖 Kubeflow 的安装流程、部署模型和性能指标,是初学者的实用指南。作者介绍了该工具的功能与局限,并展示了如何利用 Kubeflow 构建端到端的机器学习流水线。该论文旨在帮助缺乏 Kubernetes 经验的用户使用 Kubeflow 进行模型部署。
阅读全文
CLAIMED:面向可信 AI 的可视化可扩展组件库
作者:Romeo Kienzler, Ivan Nesic(2021)
本文聚焦于可信 AI 组件与 Kubeflow 的集成,关注模型可解释性、鲁棒性和公平性等问题。论文介绍了 CLAIMED 框架,将 AI Explainability360 和 AI Fairness360 等工具集成到 Kubeflow 流水线,通过可视化编辑器(如 ElyraAI)促进生产级机器学习应用开发。
阅读全文
基于深度学习的喷注能量校准作为 Kubeflow 流水线
作者:Daniel Holmberg 等(2023)
该论文利用 Kubeflow 构建了用于 CMS 实验中喷注能量校准的机器学习流水线。作者采用深度学习模型提升喷注能量校准精度,展示了 Kubeflow 在高能物理领域的可扩展能力。内容还包括流水线在云资源上扩展超参数调优和模型服务的有效性。
阅读全文
MLflow 是一个开源平台,旨在简化和管理机器学习(ML)生命周期。它为实验跟踪、代码打包、模型管理和协作提供工具,提升了 ML 项目的可复现性、部署和生命周期控制。...
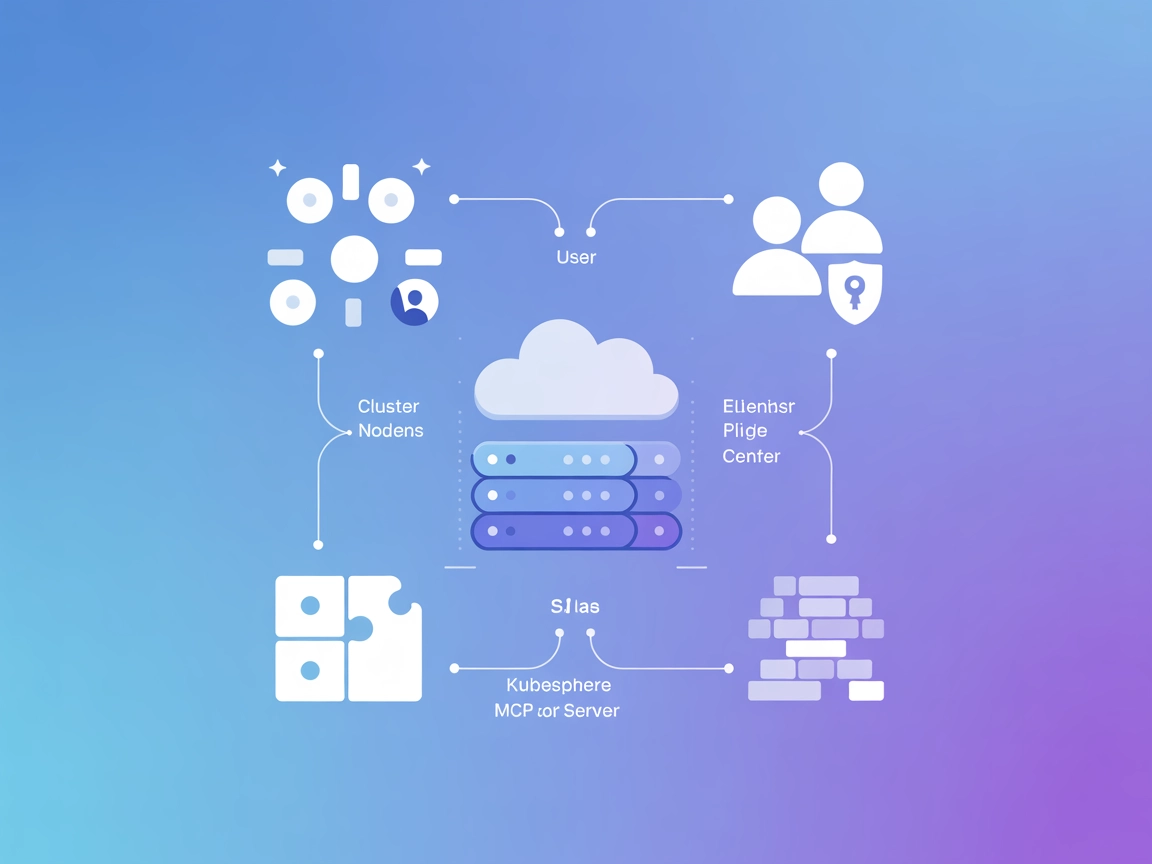
KubeSphere MCP服务器让AI助手和LLM开发工具能够无缝管理KubeSphere集群,实现如工作空间、集群、用户和扩展管理等任务自动化,加速云原生开发与DevOps工作流。...
Keboola MCP 服务器将您的 Keboola 项目与现代 AI 工具连接起来,使 AI 助理和客户端能够从其环境中访问存储、运行 SQL 转换、管理组件并编排作业。这一集成极大地简化了开发流程,并解锁了高级自动化场景。...