


튜링 테스트
튜링 테스트는 인공지능(AI) 분야에서 기계가 인간과 구별할 수 없는 지능적 행동을 보일 수 있는지 평가하기 위해 고안된 개념입니다. 1950년 앨런 튜링에 의해 제안된 이 테스트는 인간과 기계가 대화를 나누고, 심판이 어느 쪽이 인간인지 구별하지 못할 경우 기계가 인간처럼 행동한다고 ...
4 분 읽기
AI
Turing Test
+3

튜링 테스트의 기원, AI에 미친 영향, 비판, 대안, 그리고 기계 지능의 미래까지 아우르는 종합 가이드입니다.
1950년, 컴퓨터가 방 한가득 차지하며 간신히 간단한 계산만 하던 시절에 컴퓨터 단말기에 앉아 있다고 상상해 보세요. 이때 한 천재 수학자가 언젠가 이 기계들이 실제 사람과 구분 못 할 정도로 인간다운 대화를 나눌 수 있을 거라고 제안합니다. 이는 단순한 SF가 아니었습니다. 그는 순수 수학, 암호 해독, 컴퓨터 과학, 철학을 넘나든 폴리매스였습니다. 2차 세계대전 동안 브레츨리 파크에서 독일 에니그마 암호를 해독한 그의 업적은 전쟁을 단축시키고 수많은 생명을 구했습니다.
하지만 튜링의 비전은 전쟁을 훨씬 넘어 있었습니다. 1936년, 이미 그는 “튜링 머신"을 고안했고, 이것은 “기계가 생각할 수 있는가?“라는 논란이 많은 질문에 현실적인 틀을 제공했습니다. 튜링은 의식과 마음의 본질에 관한 철학적 논쟁에 빠지기보다, 답할 수 없는 질문을 “기계가 생각할 수 있는가?“에서 검증 가능한 시나리오로 대체했습니다.
튜링 테스트의 우아함은 단순함에 있지만, 그 함의는 심오합니다. 원래 “모방 게임"은 다음과 같이 진행됩니다:
심문자는 무엇이든 질문할 수 있습니다:
기계가 심문자를 최소 30%의 확률로 속이면(튜링이 제시한 기준) 테스트를 통과한 것입니다. 이 퍼센트가 낮아 보일 수 있지만, 튜링은 실제 대화에서 인간조차 항상 “인간답게” 행동하지 않는다는 점을 인식했습니다.
이 접근이 혁명적이었던 이유는 구조적 유사성이 아니라 행동적 지능에 초점을 맞췄기 때문입니다. 튜링은 기계가 인간과 똑같은 뇌를 가져야 한다고 생각하지 않았습니다.
2014년 챗봇 ‘유진 구스트만’이 약간이나마 튜링의 30% 기준을 넘긴 사례가 있었습니다. 하지만 이 승리는 크게 논란이 됐습니다.
비판자들은 유진이 전략적 기만으로 성공했다고 지적합니다:
예시 대화:
오늘날 GPT-4, Claude, Gemini 같은 AI는 튜링이 상상하지 못했을 대화를 펼칩니다. 이들은,
하지만 이러한 시스템은 튜링의 선견지명과 한계를 동시에 드러냅니다. 비공식적 튜링 테스트는 쉽게 통과하지만, 테스트가 상정하지 못한 새로운 지능의 형태도 보여줍니다.
역사적 의의에도 불구하고, 튜링 테스트는 AI가 발전함에 따라 더욱 본질적인 비판에 직면합니다.
인간의 지능은 언어 소통을 훨씬 뛰어넘습니다:
어떤 시스템은 대화에는 능하지만, 떨어뜨린 유리가 깨진다는 상식이나 “밀기” 표시가 붙은 문은 밀어도 안 열린다는 것조차 이해하지 못할 수 있습니다.
ARC는 AI가 시각적 패턴 인식, 추상적 사고를 얼마나 잘하는지 판단합니다:
이런 과제는 인간에겐 자연스럽지만, 최첨단 AI도 어려워하는 영역입니다. 단순 대화만으로는 드러나지 않는 기계 추론의 한계를 보여줍니다.
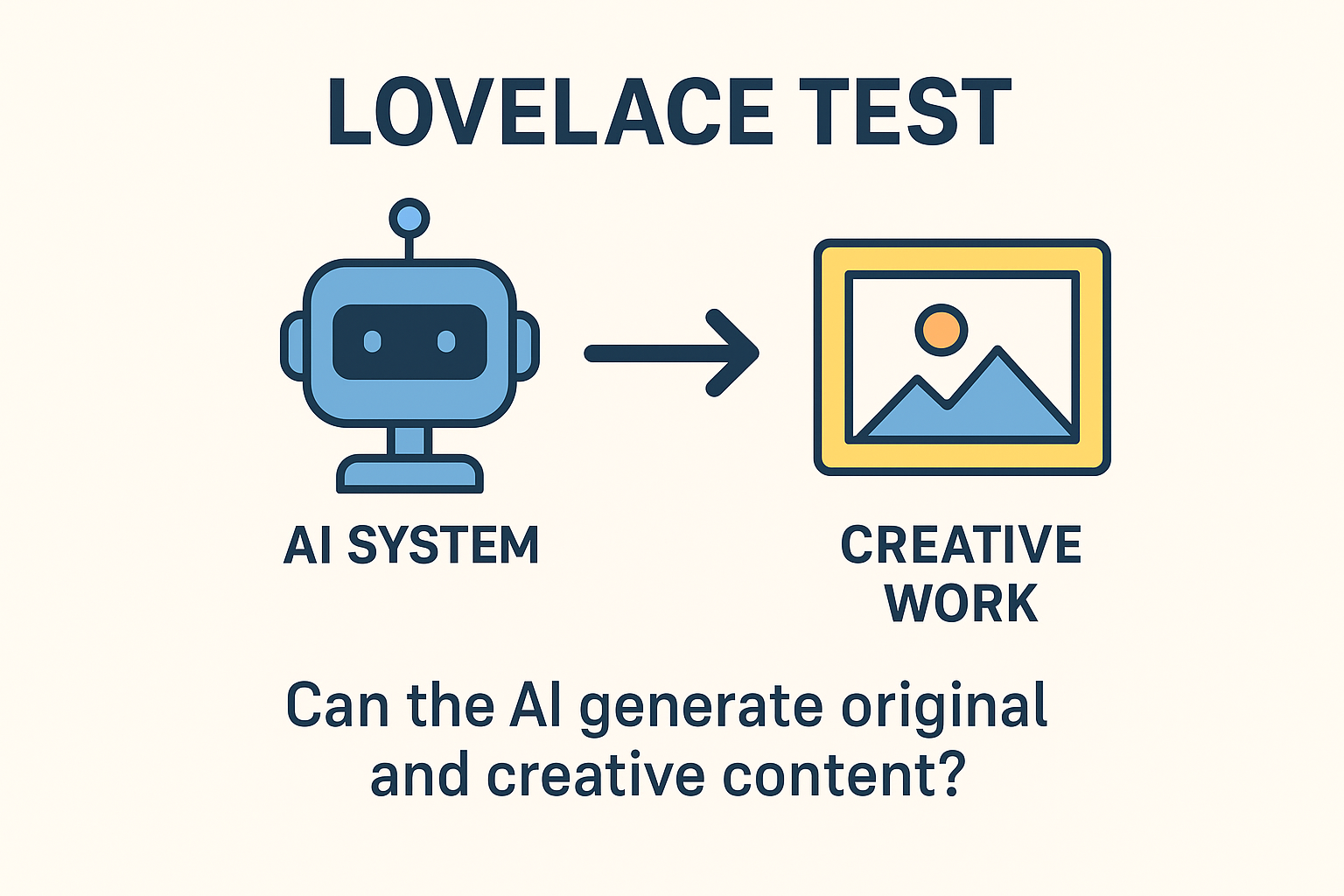
최초의 프로그래머로 꼽히는 에이다 러브레이스를 딴 이 테스트는 AI에게,
이것은 단순 모방을 넘어 진정한 생성적 지능을 시험합니다. 즉, 정신 상태는 내부 구현이 아니라 기능적 역할로 정의된다는 입장(기능주의)입니다.
하지만 이런 관점은 여전히 철학자와 인지과학자들의 논쟁을 불러옵니다:
기계가 인간을 완벽히 흉내 내더라도, 그 기계는 무언가를 ‘경험’할까요? 기계 안에 ‘느낌’이 존재할까요, 아니면 단지 정교한 시뮬레이션에 불과할까요?
기호(단어, 개념)는 어떻게 의미를 갖게 될까요? 인간이 ‘빨강’이라고 할 때는 풍부한 감각 경험을 떠올리지만, AI가 ‘빨강’을 말할 때는 실질적 참조점이 없는 단순 토큰 조작에 불과할까요?
지능적 시스템은 어떻게 맥락에서 중요한 정보를 선별할까요? 인간은 수많은 무관한 요소 중 핵심만을 집중적으로 다루지만, AI는 이 능력을 가질 수 있을까요?
튜링 테스트는 이런 심층적 질문을 피하고 관찰 가능한 행동에만 집중합니다. 결국 AI의 목적은 인간 능력을 보완하고 실제 문제를 해결하는 것입니다.
튜링 테스트가 남긴 가장 큰 유산은 우리가 다음 단계의 질문을 하도록 유도했다는 점일지 모릅니다. 인간 모방에 집착하는 것은 지능 자체에 대한 이해를 제한할 수 있습니다.
AI가 인간처럼 생각하길 고집하기보다,
“AI가 인간을 속일 수 있는가?” 대신,
앨런 튜링의 단순한 사고 실험은 놀라운 성과를 남겼습니다. 기계 지능이란 개념이 순전한 공상으로만 여겨지던 시대에, 그는 인류에게 새로운 사고의 틀을 제시했습니다. 이 테스트는 상상력을 자극하고 연구를 촉진했으며, 의식·지능·인간다움에 대한 본질적 질문을 마주하게 했습니다.
하지만 AI가 점점 더 정교해지면서, 이제는 단순 모방 게임을 넘어서야 할 때입니다.
이제 “기계는 인간처럼 생각할 수 있는가?“가 아니라,
튜링 테스트는 이런 대화를 시작하게 해주었습니다. 이제 우리는 지혜와 창의성, 그리고 우리가 살아가는 지능 혁명의 의미를 깊이 성찰하며 이 대화를 이어가야 합니다.
아마 이것이 튜링 테스트의 가장 큰 유산일 것입니다. 최종 해답이 아니라, 지능·의식·미래에 대해 더 나은 질문을 던지게 해주었다는 점에서 말입니다.
튜링이 1950년에 시작한 대화는 지금도 계속되고 있습니다. 단순한 인간 흉내를 넘어서면서 말이죠.
튜링 테스트를 대체한 것은 무엇인가요?
현대 AI 평가는 위노그래드 스키마 챌린지(상식적 추론), MMLU(다중 과제 지식), ARC(추상적 추론), 그리고 창의성·윤리·현실 문제 해결 등 다양한 벤치마크를 통해 보다 포괄적으로 지능을 측정합니다.
튜링 테스트는 기계가 인간과 구별되지 않는 대화를 할 수 있는지 평가합니다. 심문자가 기계와 인간을 확실히 구분하지 못하면, 그 기계는 테스트를 통과했다고 볼 수 있습니다.
튜링 테스트는 영국의 수학자이자 컴퓨터 과학자인 앨런 튜링이 1950년 논문 '계산 기계와 지능'에서 제안했습니다.
2014년 유진 구스트만(Eugene Goostman)과 같은 일부 챗봇이 특정 조건에서 통과했다고 주장된 적이 있지만, 이러한 결과는 여전히 논란의 여지가 많으며 진정한 이해보다는 대화 기술에 의존하는 경우가 많았습니다.
역사적으로 중요한 의미가 있지만, 오늘날 많은 전문가들은 구시대적이라 평가합니다. 현대 AI는 추론, 창의성, 과제 수행 등 더 폭넓은 벤치마크로 평가받고 있습니다.
대안으로는 추론을 평가하는 위노그래드 스키마 챌린지, 창의성을 평가하는 러브레이스 테스트, 다중 과제 지식 평가를 위한 MMLU 벤치마크 등이 있습니다.
아르시아는 FlowHunt의 AI 워크플로우 엔지니어입니다. 컴퓨터 과학 배경과 AI에 대한 열정을 바탕으로, 그는 AI 도구를 일상 업무에 통합하여 생산성과 창의성을 높이는 효율적인 워크플로우를 설계하는 데 전문성을 가지고 있습니다.
Flowhunt의 노코드 플랫폼으로 워크플로우 자동화, 질의 응답, 지능형 에이전트 구축 등 튜링 테스트 같은 단순 벤치마크를 뛰어넘는 AI를 경험하세요.
튜링 테스트는 인공지능(AI) 분야에서 기계가 인간과 구별할 수 없는 지능적 행동을 보일 수 있는지 평가하기 위해 고안된 개념입니다. 1950년 앨런 튜링에 의해 제안된 이 테스트는 인간과 기계가 대화를 나누고, 심판이 어느 쪽이 인간인지 구별하지 못할 경우 기계가 인간처럼 행동한다고 ...
AI는 어떻게 오늘날의 모습에 도달했을까?
OpenAI의 o1 Preview가 내부 계획, 창의성, 제약 준수를 통해 GPT-4를 능가하며 복잡한 글쓰기 프롬프트를 마스터하는 방법을 알아보고, 크리에이티브 산업 등에서 AI의 새로운 가능성을 엿보세요....

