ما هو مكون LLM xAI؟
يقوم مكون LLM xAI بتوصيل نموذج Grok بتدفقك. بينما تحدث المعالجة الفعلية في المولدات والوكلاء الذكيين، تتيح لك مكونات LLM التحكم بالنموذج المستخدم. جميع المكونات تأتي افتراضياً مع ChatGPT-4. يمكنك توصيل هذا المكون إذا أردت تغيير النموذج أو الحصول على تحكم أكبر فيه.
تذكر أن توصيل مكون LLM هو اختياري. جميع المكونات التي تستخدم LLM تأتي مع ChatGPT-4o كإعداد افتراضي. تسمح لك مكونات LLM بتغيير النموذج والتحكم في إعداداته.
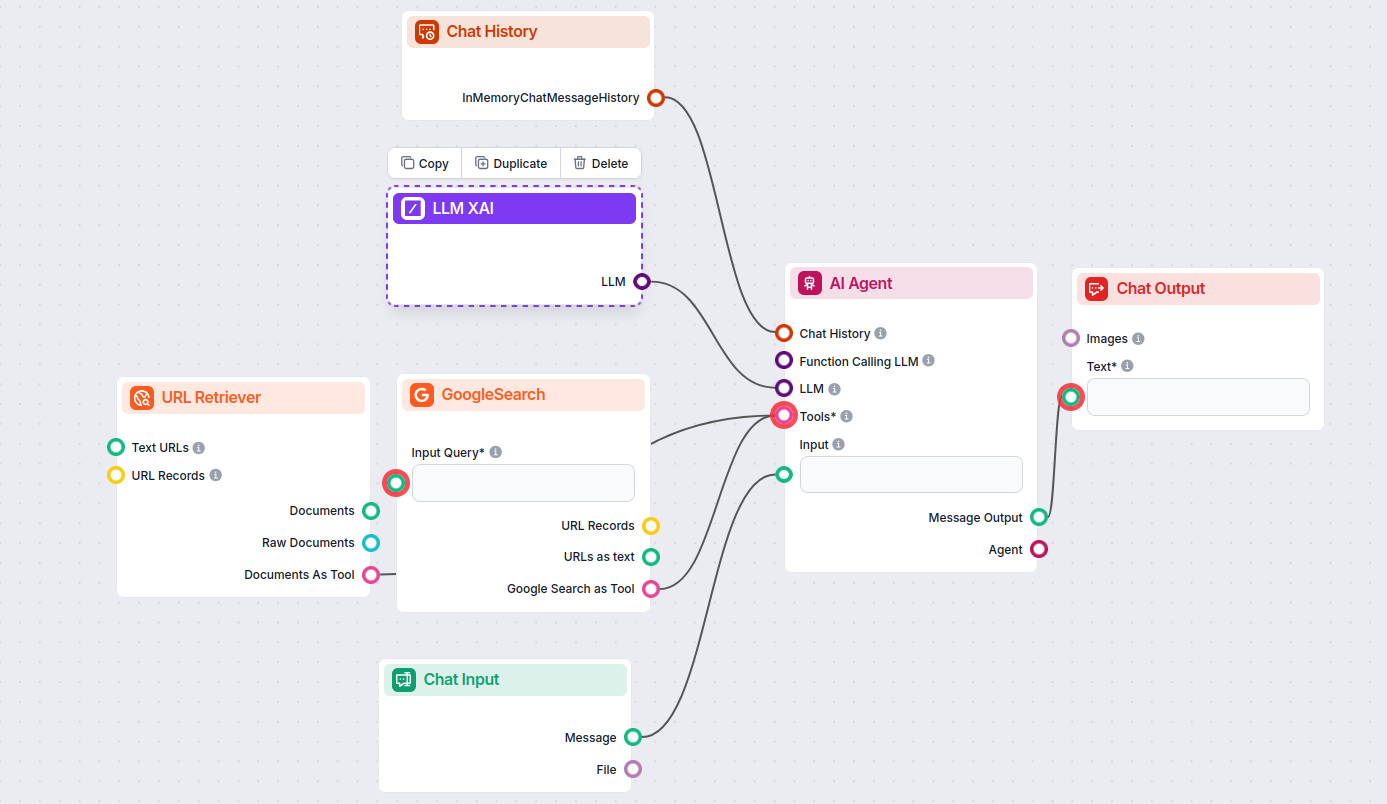
إعدادات مكون LLM xAI
الحد الأقصى للرموز (Max Tokens)
الرموز هي الوحدات الفردية من النص التي يعالجها النموذج وينتجها. يختلف استخدام الرموز بين النماذج، ويمكن أن يكون الرمز كلمة أو جزءاً من كلمة أو حتى حرفاً واحداً. غالباً ما يتم تسعير النماذج بملايين الرموز.
يحدد إعداد الحد الأقصى للرموز العدد الكلي للرموز الممكن معالجتها في تفاعل أو طلب واحد، لضمان أن تكون الإجابات ضمن حدود معقولة. الحد الافتراضي هو 4000 رمز، وهو الحجم الأمثل لتلخيص المستندات وعدة مصادر لإنتاج إجابة.
درجة الحرارة (Temperature)
تتحكم درجة الحرارة في تنويع الإجابات، وتتراوح من 0 إلى 1.
درجة حرارة 0.1 ستجعل الإجابات مركزة جداً ولكن قد تكون متكررة أو ناقصة.
درجة حرارة عالية مثل 1 تسمح بأقصى قدر من الإبداع في الإجابات لكنها ترفع خطورة أن تكون الإجابات غير ذات صلة أو حتى متخيلة.
على سبيل المثال، درجة الحرارة الموصى بها لروبوت خدمة العملاء هي بين 0.2 و0.5. هذا المستوى يحافظ على ملاءمة الإجابات للنص مع السماح ببعض التنوع الطبيعي في الردود.
النموذج (Model)
هذا هو محدد النموذج. هنا ستجد جميع النماذج المدعومة من مزود xAI. النموذج النصي الرئيسي لـ xAI يسمى Grok. حالياً، ندعم فقط نموذج grok-beta، لأنه الوحيد المتاح للاستخدام العام عبر واجهة البرمجة.
هل ترغب في معرفة المزيد عن Grok-beta ومقارنته بالنماذج الأخرى؟ اطلع على هذا المقال.
كيف تضيف LLM xAI إلى تدفقك
ستلاحظ أن جميع مكونات LLM لديها فقط مقبض إخراج. المدخلات لا تمر عبر المكون، لأنه يمثل النموذج فقط، بينما تتم عملية التوليد الفعلية في الوكلاء الذكيين والمولدات.
مقبض LLM يكون دائماً أرجواني. مقبض إدخال LLM يوجد في أي مكون يستخدم الذكاء الاصطناعي لتوليد النصوص أو معالجة البيانات. يمكنك رؤية الخيارات بالنقر على المقبض:
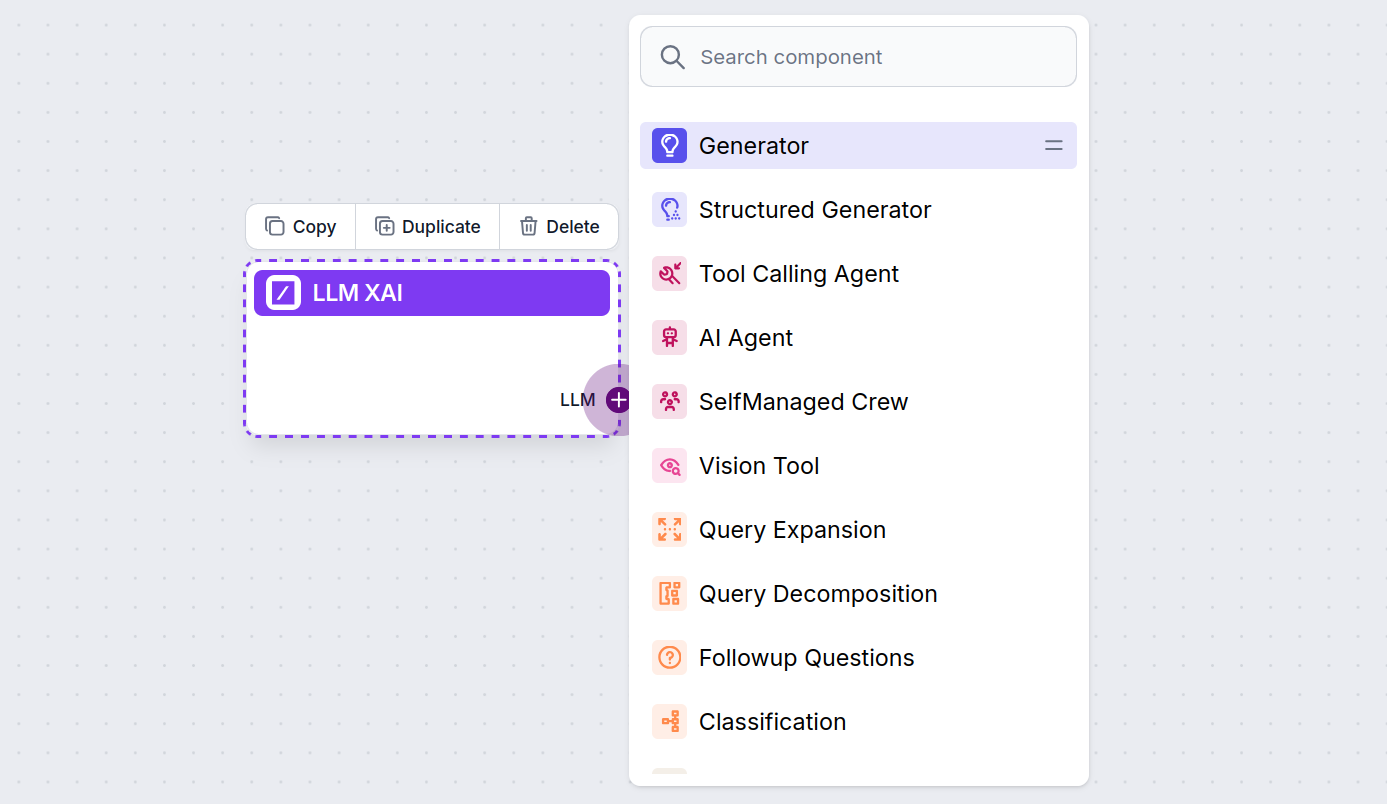
يتيح لك هذا إنشاء جميع أنواع الأدوات. لنرَ المكون أثناء العمل. إليك تدفق دردشة ذكي بسيط لوكيل ذكاء اصطناعي يستخدم grok-beta من xAI لتوليد الردود. يمكنك اعتباره دردشة xAI أساسية.
يتضمن هذا التدفق البسيط للدردشة الذكية:
- إدخال الدردشة: يمثل الرسالة التي يرسلها المستخدم في الدردشة.
- سجل الدردشة: يضمن أن الدردشة الذكية تتذكر وتأخذ في الاعتبار الردود السابقة.
- إخراج الدردشة: يمثل الرد النهائي للدردشة الذكية.
- وكيل الذكاء الاصطناعي: وكيل ذكي مستقل يقوم بتوليد الردود.
- LLM xAI: الاتصال بنماذج توليد النصوص من xAI.