كيفية التحقق من مصداقية روبوتات الدردشة الذكية
تعرّف على الطرق الموثوقة للتحقق من مصداقية روبوتات الدردشة الذكية في عام 2025. اكتشف تقنيات التحقق الفنية، وفحوصات الأمان، وأفضل الممارسات للتأكد من أنظمة الذكا...
10 دقيقة قراءة
تعرّف على منهجيات شاملة لقياس دقة روبوت الدردشة الذكي للدعم الفني في عام 2025. اكتشف دقة الاسترجاع، معايير F1، مؤشرات رضا المستخدم، وتقنيات التقييم المتقدمة مع FlowHunt.
قُم بقياس دقة روبوت الدردشة الذكي باستخدام عدة مؤشرات بما في ذلك حسابات الدقة والاسترجاع، مصفوفة الالتباس، درجات رضا المستخدم، معدلات الحل، وطرق التقييم المتقدمة المعتمدة على نماذج اللغة الكبيرة. يوفر FlowHunt أدوات شاملة للتقييم الآلي للدقة ولمراقبة الأداء.
يُعد قياس دقة روبوت الدردشة الذكي للدعم الفني أمرًا أساسيًا لضمان تقديمه ردودًا موثوقة ومفيدة على استفسارات العملاء. وعلى عكس مهام التصنيف البسيطة، فإن دقة روبوت الدردشة تتضمن عدة أبعاد يجب تقييمها معًا للحصول على صورة كاملة عن الأداء. تشمل العملية تحليل مدى فهم الروبوت لاستفسارات المستخدمين، وتقديمه للمعلومات الصحيحة، وفعالية حل المشكلات، والحفاظ على رضا المستخدم أثناء التفاعل. تجمع استراتيجية قياس الدقة الشاملة بين المؤشرات الكمية والملاحظات النوعية لتحديد نقاط القوة والجوانب التي تحتاج للتحسين.
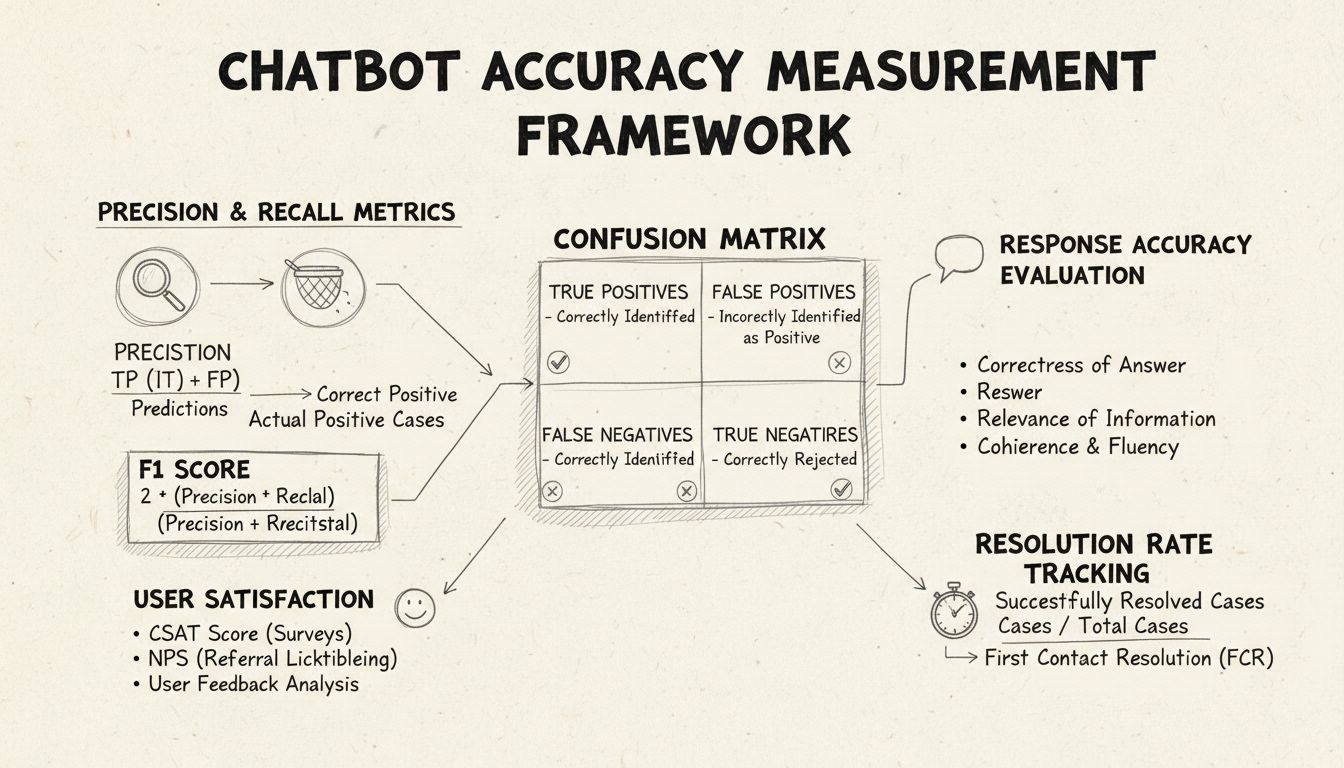
الدقة والاسترجاع هما مؤشرين أساسيين مشتقين من مصفوفة الالتباس ويقيسان جوانب مختلفة من أداء الروبوت. الدقة تُمثل نسبة الردود الصحيحة من بين جميع الردود التي قدمها الروبوت، وتحسب بالمعادلة: الدقة = الإجابات الصحيحة الإيجابية / (الإجابات الصحيحة الإيجابية + الإيجابيات الكاذبة). يجيب هذا المؤشر على سؤال: “عندما يقدم الروبوت إجابة، كم مرة تكون صحيحة؟” تشير الدقة العالية إلى أن الروبوت نادرًا ما يقدم معلومات غير صحيحة، وهو أمر بالغ الأهمية للحفاظ على ثقة المستخدم في سيناريوهات الدعم الفني.
الاسترجاع، ويُعرف أيضًا بالحساسية، يقيس نسبة الردود الصحيحة من بين جميع الإجابات الصحيحة التي كان يجب أن يقدمها الروبوت، وذلك بالمعادلة: الاسترجاع = الإجابات الصحيحة الإيجابية / (الإجابات الصحيحة الإيجابية + السلبيات الكاذبة). يوضح هذا المؤشر ما إذا كان الروبوت ينجح في تحديد جميع مشكلات العملاء الحقيقية والرد عليها. في سياق الدعم الفني، يضمن الاسترجاع العالي حصول العملاء على المساعدة بدلاً من إبلاغهم بعدم القدرة على المساعدة عندما يكون ذلك ممكنًا بالفعل. هناك علاقة عكسية بين الدقة والاسترجاع: تحسين أحدهما غالبًا ما يقلل الآخر، لذا يجب تحقيق توازن مناسب بناءً على أولويات العمل الخاصة بك.
توفر درجة F1 مؤشرًا موحدًا يوازن بين الدقة والاسترجاع، وتحسب كالمتوسط التوافقي: F1 = 2 × (الدقة × الاسترجاع) / (الدقة + الاسترجاع). يعتبر هذا المؤشر ذا قيمة خاصة عند الحاجة إلى مؤشر أداء موحد أو عند التعامل مع مجموعات بيانات غير متوازنة حيث تهيمن فئة على أخرى. على سبيل المثال، إذا كان الروبوت يتعامل مع 1000 استفسار روتيني و50 تصعيدًا معقدًا فقط، تمنع درجة F1 انحياز المؤشر للفئة الأكبر. تتراوح درجة F1 بين 0 إلى 1، حيث تمثل 1 دقة واسترجاع مثالية، ما يجعلها سهلة الفهم لأصحاب المصلحة لرؤية أداء الروبوت بشكل عام.
مصفوفة الالتباس هي أداة أساسية تُحلل أداء الروبوت إلى أربع فئات: الإيجابيات الحقيقية (ردود صحيحة على استفسارات صحيحة)، والسلبيات الحقيقية (رفض صحيح للأسئلة الخارجة عن النطاق)، والإيجابيات الكاذبة (ردود غير صحيحة)، والسلبيات الكاذبة (فرص مساعدة ضائعة). تكشف هذه المصفوفة أنماطًا محددة في إخفاقات الروبوت، مما يمكّن من إجراء تحسينات مستهدفة. فعلى سبيل المثال، إذا أظهرت المصفوفة سلبيات كاذبة مرتفعة في استفسارات الفواتير، يمكن تحديد أن بيانات تدريب الروبوت تفتقر لأمثلة كافية في مجال الفواتير وتحتاج إلى تعزيز.
| المؤشر | التعريف | طريقة الحساب | الأثر على الأعمال |
|---|---|---|---|
| الإيجابيات الحقيقية (TP) | ردود صحيحة على استفسارات صحيحة | تُحسب مباشرة | تبني ثقة العملاء |
| السلبيات الحقيقية (TN) | رفض صحيح للأسئلة الخارجة عن النطاق | تُحسب مباشرة | تمنع المعلومات الخاطئة |
| الإيجابيات الكاذبة (FP) | ردود غير صحيحة | تُحسب مباشرة | تضر بالمصداقية |
| السلبيات الكاذبة (FN) | فرص مساعدة ضائعة | تُحسب مباشرة | تقلل من الرضا |
| الدقة | جودة التوقعات الإيجابية | TP / (TP + FP) | مؤشر الموثوقية |
| الاسترجاع | تغطية الإجابات الصحيحة | TP / (TP + FN) | مؤشر الشمولية |
| الدقة الإجمالية | الصحة الشاملة | (TP + TN) / الإجمالي | الأداء العام |
تقيس دقة الردود مدى تقديم الروبوت لمعلومات صحيحة من الناحية الواقعية وتلائم سؤال المستخدم بشكل مباشر. يتجاوز ذلك المطابقة البسيطة للنمط ليقيّم ما إذا كان المحتوى دقيقًا وحديثًا ومناسبًا للسياق. تتضمن عمليات المراجعة اليدوية قيام مقيمين بشريين بفحص عينة عشوائية من المحادثات، ومقارنة ردود الروبوت بقاعدة معرفية محددة للإجابات الصحيحة. يمكن تنفيذ طرق مقارنة آلية باستخدام تقنيات معالجة اللغة الطبيعية لمقارنة الردود مع الإجابات المتوقعة المخزنة في النظام، مع ضرورة ضبطها بعناية لتجنب السلبيات الكاذبة عندما يقدم الروبوت معلومات صحيحة بصياغة مختلفة عن المرجع.
تقيس ملاءمة الرد ما إذا كان جواب الروبوت يعالج فعليًا ما طلبه المستخدم حتى إن لم يكن الجواب صحيحًا تمامًا. تلتقط هذه البُعد الحالات التي يقدم فيها الروبوت معلومات مفيدة تساعد في حل المشكلة حتى وإن لم تكن الإجابة دقيقة. يمكن استخدام طرق معالجة اللغة الطبيعية مثل قياس التشابه الكوني لقياس التشابه الدلالي بين سؤال المستخدم ورد الروبوت، ما يوفر درجة ملاءمة آلية. توفر آليات ملاحظات المستخدم، مثل تقييم الإعجاب/عدم الإعجاب بعد كل تفاعل، تقييماً مباشراً للملاءمة من العملاء أنفسهم. يجب جمع وتحليل هذه الإشارات باستمرار لتحديد أنماط الاستفسارات التي يتعامل معها الروبوت بشكل جيد أو ضعيف.
يقيس مؤشر رضا العملاء رضا المستخدمين عن تفاعلهم مع الروبوت من خلال استبيانات مباشرة، عادةً باستخدام مقياس من 1 إلى 5 أو تقييمات بسيطة للرضا. بعد كل تفاعل، يُطلب من المستخدمين تقييم رضاهم، ما يوفر تغذية راجعة فورية حول ما إذا كان الروبوت قد لبى احتياجاتهم. تشير الدرجات التي تتجاوز 80% إلى أداء قوي، بينما تشير الدرجات دون 60% إلى وجود مشكلات تتطلب التحقيق. يتميز مؤشر CSAT ببساطته ومباشرته، لكنه قد يتأثر بعوامل تتجاوز دقة الروبوت، مثل تعقيد المشكلة أو توقعات المستخدم.
يقيس مؤشر صافي المروجين احتمال أن يوصي المستخدمون بالروبوت للآخرين، ويحسب عبر سؤال “ما مدى احتمالية أن توصي بهذا الروبوت لزميل؟” على مقياس من 0 إلى 10. من يجيبون بدرجة 9-10 هم المروجون، و7-8 محايدون، و0-6 منتقصون. NPS = (عدد المروجين - عدد المنتقصين) / إجمالي المشاركين × 100. يرتبط هذا المؤشر بقوة بولاء العملاء على المدى الطويل ويوفر نظرة على مدى إيجابية التجارب التي يخلقها الروبوت. يعتبر NPS فوق 50 ممتازًا، بينما يشير NPS السلبي إلى مشكلات أداء خطيرة.
يحلل تحليل المشاعر النبرة العاطفية لرسائل المستخدمين قبل وبعد التفاعل مع الروبوت لقياس الرضا. تصنف تقنيات معالجة اللغة المتقدمة الرسائل إلى إيجابية أو محايدة أو سلبية، كاشفة ما إذا كان المستخدمون أصبحوا أكثر رضا أو إحباطاً أثناء المحادثة. يشير التحول الإيجابي في المشاعر إلى أن الروبوت نجح في حل المخاوف، بينما تشير التحولات السلبية إلى احتمال أن الروبوت أحبط المستخدمين أو فشل في تلبية احتياجاتهم. يلتقط هذا المؤشر الأبعاد العاطفية التي تغفلها مؤشرات الدقة التقليدية، ما يوفر سياقًا مهمًا لفهم جودة تجربة المستخدم.
يقيس معدل الحل من أول تواصل النسبة المئوية من مشكلات العملاء التي يحلها الروبوت دون الحاجة للتصعيد إلى موظفين بشريين. يؤثر هذا المؤشر بشكل مباشر على الكفاءة التشغيلية ورضا العملاء، إذ يفضل العملاء حل مشكلاتهم فوراً بدلاً من تحويلهم. تشير معدلات FCR التي تتجاوز 70% إلى أداء قوي للروبوت، بينما تدل المعدلات دون 50% على نقص المعرفة أو القدرة الكافية للتعامل مع الاستفسارات الشائعة. يكشف تتبع معدل FCR حسب فئة المشكلة عن أنواع المشكلات التي يتعامل معها الروبوت جيدًا وتلك التي تتطلب تدخلاً بشريًا، ما يوجه تحسينات التدريب وقاعدة المعرفة.
يقيس معدل التصعيد مدى تكرار تحويل الروبوت للمحادثات إلى الموظفين البشريين، بينما يقيس تكرار الاستعانة بردود احتياطية مدى تكرار استخدام الروبوت ردودًا عامة مثل “لا أفهم” أو “يرجى إعادة صياغة سؤالك”. تشير معدلات التصعيد العالية (أكثر من 30%) إلى نقص المعرفة أو الثقة في العديد من السيناريوهات، بينما تشير معدلات الاستعانة المرتفعة إلى ضعف في التعرف على النوايا أو نقص بيانات التدريب. تحدد هذه المؤشرات الفجوات المحددة في قدرات الروبوت التي يمكن معالجتها بتوسيع قاعدة المعرفة، أو إعادة تدريب النموذج، أو تحسين مكونات فهم اللغة الطبيعية.
يقيس زمن الاستجابة مدى سرعة رد الروبوت على رسائل المستخدم، وغالبًا ما يُقاس بالمللي ثانية إلى ثوانٍ. يتوقع المستخدمون ردودًا شبه فورية؛ إذ تؤدي التأخيرات التي تتجاوز 3-5 ثوانٍ إلى انخفاض الرضا بشكل ملحوظ. يقيس زمن المعالجة المدة الإجمالية منذ بدء المستخدم للتواصل حتى حل المشكلة أو تصعيدها، ما يوفر مؤشرًا على كفاءة الروبوت. تشير أزمنة المعالجة الأقصر إلى قدرة الروبوت على فهم المشكلات وحلها بسرعة، بينما تشير الأوقات الأطول إلى الحاجة لجولات توضيح متعددة أو صعوبة في التعامل مع الاستفسارات المعقدة. يجب تتبع هذه المؤشرات بشكل منفصل لفئات المشكلات المختلفة، حيث تتطلب المشكلات التقنية المعقدة بطبيعتها وقت معالجة أطول من أسئلة الأسئلة الشائعة البسيطة.
تُمثل طريقة “النموذج كلجنة حكم” نهج تقييم متقدم حيث يقوم نموذج لغوي كبير بتقييم جودة مخرجات نظام ذكاء اصطناعي آخر. يثبت هذا النهج فعاليته الخاصة عند تقييم ردود الروبوت عبر أبعاد جودة متعددة في وقت واحد مثل الدقة، والملاءمة، والترابط، والطلاقة، والأمان، والكمال، والنبرة. تظهر الأبحاث أن لجان الحكم من النماذج تصل إلى توافق مع التقييم البشري بنسبة تصل إلى 85%، ما يجعلها بديلًا قابلاً للتوسع للمراجعة اليدوية. يتضمن النهج تحديد معايير تقييم محددة، وصياغة مطالبات تقييم تفصيلية مع أمثلة، وتزويد لجنة الحكم بكل من سؤال المستخدم الأصلي ورد الروبوت، والحصول على درجات منظمة أو تغذية راجعة مفصلة.
عادة ما توظف عملية “النموذج كلجنة حكم” طريقتين للتقييم: تقييم مخرجات فردية، حيث تقوم اللجنة بتقييم رد فردي باستخدام التقييم بدون مرجع (دون حقيقة مرجعية) أو المقارنة المرجعية (مقارنة بإجابة متوقعة)، والمقارنة الزوجية، حيث تقارن اللجنة بين مخرجين لتحديد الأفضل. يتيح هذا المرونة في تقييم الأداء المطلق والتحسينات النسبية عند اختبار إصدارات أو إعدادات مختلفة للروبوت. تدعم منصة FlowHunt تنفيذ أساليب “النموذج كلجنة حكم” من خلال واجهتها البصرية، ودمجها مع نماذج بارزة مثل ChatGPT وClaude، وأدوات CLI لإعداد التقارير المتقدمة والتقييمات الآلية.
بعيدًا عن حسابات الدقة الأساسية، يكشف التحليل التفصيلي لمصفوفة الالتباس أنماطًا محددة في إخفاقات الروبوت. من خلال دراسة أنواع الاستفسارات التي تنتج إيجابيات كاذبة مقابل سلبيات كاذبة، يمكنك تحديد نقاط الضعف المنهجية. على سبيل المثال، إذا أظهرت المصفوفة أن الروبوت يخطئ في تصنيف أسئلة الفواتير كدعم فني، فهذا يكشف عن اختلال في بيانات التدريب أو مشكلة في التعرف على النوايا ضمن مجال الفواتير. يسمح إنشاء مصفوفات التباس منفصلة لفئات المشكلات المختلفة بإجراء تحسينات مستهدفة بدلاً من إعادة تدريب النموذج بشكل عام.
يقارن اختبار A/B بين إصدارات مختلفة من الروبوت لتحديد أيها يقدم أداءً أفضل في المؤشرات الرئيسية. قد يشمل ذلك اختبار قوالب ردود مختلفة، أو إعدادات قاعدة المعرفة، أو نماذج لغوية أساسية متنوعة. من خلال توجيه جزء من حركة المرور لكل إصدار ومقارنة مؤشرات مثل معدل FCR، ودرجات CSAT، ودقة الردود، يمكنك اتخاذ قرارات مبنية على البيانات بشأن أي التحسينات يجب تطبيقها. يجب أن يستمر اختبار A/B لمدة كافية لالتقاط التغيرات الطبيعية في استفسارات المستخدمين وضمان دلالة إحصائية للنتائج.
توفر منصة FlowHunt بيئة متكاملة لبناء، ونشر، وتقييم روبوتات الدردشة الذكية للدعم الفني مع قدرات متقدمة لقياس الدقة. يمكّن الباني البصري للمنصة المستخدمين غير التقنيين من إنشاء تدفقات روبوت دردشة متطورة، بينما تدمج مكوناتها الذكية مع نماذج لغوية رائدة مثل ChatGPT وClaude. يدعم صندوق أدوات التقييم من FlowHunt تنفيذ منهجية “النموذج كلجنة حكم”، ما يتيح لك تحديد معايير تقييم مخصصة وتقييم أداء الروبوت تلقائيًا عبر مجموعة بيانات المحادثات الكاملة لديك.
لبدء قياس الدقة الشامل مع FlowHunt، حدد أولاً معايير التقييم الخاصة بك بما يتماشى مع أهداف العمل—سواء كنت تركز على الدقة، أو السرعة، أو رضا المستخدم، أو معدلات الحل. قُم بضبط النموذج الحاكم في المنصة بمطالبات مفصلة توضح كيفية تقييم الردود، بما في ذلك أمثلة واقعية للردود الجيدة والسيئة. حمّل مجموعة بيانات محادثاتك أو اربطها بالحركة الحية، ثم نفذ التقييمات للحصول على تقارير مفصلة توضح الأداء عبر جميع المؤشرات. يوفر لك لوحة تحكم FlowHunt رؤية فورية لأداء الروبوت، ما يمكّنك من تحديد المشكلات بسرعة والتحقق من فعالية التحسينات.
ابدأ بقياس خط الأساس قبل تنفيذ أي تحسينات، لإنشاء نقطة مرجعية لتقييم أثر أي تغييرات لاحقة. اجمع المؤشرات باستمرار وليس بشكل دوري فقط، مما يتيح الكشف المبكر عن تراجع الأداء بسبب تغير البيانات أو تدهور النموذج. فعّل حلقات التغذية الراجعة حيث تُدمج تقييمات المستخدم وتصحيحاته تلقائيًا في عملية التدريب لتحسين دقة الروبوت باستمرار. قُم بتقسيم المؤشرات حسب فئة المشكلة، ونوع المستخدم، والفترة الزمنية لتحديد الجوانب التي تتطلب الاهتمام بدلاً من الاعتماد فقط على المؤشرات الإجمالية.
تأكد من أن مجموعة التقييم تمثل استفسارات المستخدمين الحقيقية والإجابات المتوقعة، وتجنب الحالات الاختبارية المصطنعة التي لا تعكس أنماط الاستخدام الفعلية. قُم باستمرار بمقارنة المؤشرات الآلية بالحكم البشري من خلال تقييم عينات من المحادثات يدويًا، لضمان بقاء نظام القياس مضبوطًا على الجودة الفعلية. وثق منهجية القياس وتعريفات المؤشرات بوضوح، ما يضمن التقييم المستمر والمتسق بمرور الوقت وسهولة التواصل مع أصحاب المصلحة. وأخيرًا، حدد أهداف أداء لكل مؤشر تتماشى مع أهداف العمل، لخلق مسؤولية للتحسين المستمر وتوفير أهداف واضحة لجهود التحسين.
منصة FlowHunt المتقدمة لأتمتة الذكاء الاصطناعي تساعدك على إنشاء، نشر، وتقييم روبوتات الدردشة للدعم الفني عالية الأداء مع أدوات قياس الدقة المدمجة وإمكانيات تقييم مبنية على نماذج اللغة الكبيرة.
تعرّف على الطرق الموثوقة للتحقق من مصداقية روبوتات الدردشة الذكية في عام 2025. اكتشف تقنيات التحقق الفنية، وفحوصات الأمان، وأفضل الممارسات للتأكد من أنظمة الذكا...
تعرّف على استراتيجيات اختبار روبوتات الدردشة الشاملة بالذكاء الاصطناعي بما في ذلك اختبار الوظائف، الأداء، الأمان، وسهولة الاستخدام. اكتشف أفضل الممارسات والأدوا...
اكتشف أهمية دقة واستقرار نماذج الذكاء الاصطناعي في التعلم الآلي. تعرف على تأثير هذه المقاييس على التطبيقات مثل كشف الاحتيال، التشخيص الطبي، والدردشة الآلية، واس...
الموافقة على ملفات تعريف الارتباط
نستخدم ملفات تعريف الارتباط لتعزيز تجربة التصفح وتحليل حركة المرور لدينا. See our privacy policy.