Context Engineering: The Definitive 2025 Guide to Mastering AI System Design
Dive deep into context engineering for AI. This guide covers core principles, from prompt vs. context to advanced strategies like memory management, context rot, and multi-agent design.
AI
LLM
System Design
Agents
Context Engineering
Prompt Engineering
RAG
The AI development landscape has undergone a profound transformation. Where we once obsessed over crafting the perfect prompt, we now face a far more complex challenge: building entire information architectures that surround and empower our language models.
This shift marks the evolution from prompt engineering to context engineering—and it represents nothing less than the future of practical AI development. The systems delivering real value today don’t rely on magical prompts. They succeed because their architects have learned to orchestrate comprehensive information ecosystems.
Andrej Karpathy captured this evolution perfectly when he described context engineering as the careful practice of populating the context window with precisely the right information at exactly the right moment. This deceptively simple statement reveals a fundamental truth: the LLM is no longer the star of the show. It’s a critical component within a carefully designed system where every piece of information—every memory fragment, every tool description, every retrieved document—has been deliberately positioned to maximize results.
What Is Context Engineering?
A Historical Perspective
The roots of context engineering run deeper than most realize. While mainstream discussions about prompt engineering exploded around 2022-2023, the foundational concepts of context engineering emerged over two decades ago from ubiquitous computing and human-computer interaction research.
Back in 2001, Anind K. Dey established a definition that would prove remarkably prescient: context encompasses any information that helps characterize an entity’s situation. This early framework laid the groundwork for how we think about machine understanding of environments.
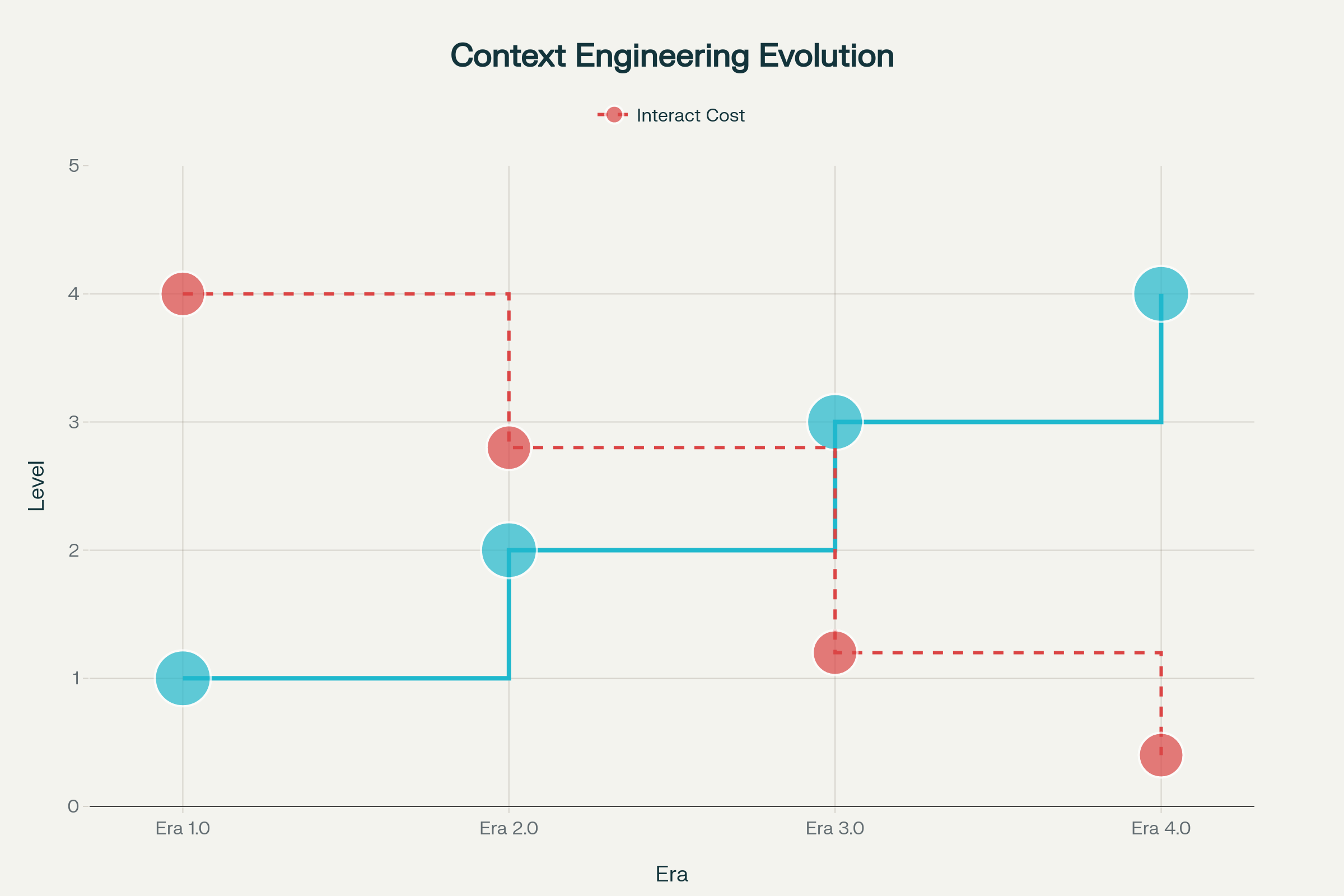
The evolution of context engineering has unfolded across distinct phases, each shaped by advances in machine intelligence:
Era 1.0: Primitive Computation (1990s-2020) — During this extended period, machines could handle only structured inputs and basic environmental signals. Humans bore the full burden of translating contexts into machine-processable formats. Think desktop applications, mobile apps with sensor inputs, and early chatbots with rigid response trees.
Era 2.0: Agent-Centric Intelligence (2020–Present) — GPT-3’s release in 2020 triggered a paradigm shift. Large language models brought genuine natural language comprehension and the ability to work with implicit intentions. This era enabled authentic human-agent collaboration, where ambiguity and incomplete information became manageable through sophisticated language understanding and in-context learning.
Era 3.0 & 4.0: Human and Superhuman Intelligence (Future) — The next waves promise systems that can sense and process high-entropy information with human-like fluidity, eventually moving beyond reactive responses to proactively construct context and surface needs users haven’t even articulated.
Evolution of Context Engineering Across Four Eras: From Primitive Computing to Superhuman Intelligence
A Formal Definition
At its core, context engineering represents the systematic discipline of designing and optimizing how contextual information flows through AI systems—from initial collection through storage, management, and ultimate utilization to enhance machine understanding and task execution.
We can express this mathematically as a transformation function:
$CE: (C, T) \rightarrow f_{context}$
Where:
C represents raw contextual information (entities and their characteristics)
T denotes the target task or application domain
f_{context} yields the resulting context processing function
Breaking this down into practical terms reveals four fundamental operations:
Collecting relevant contextual signals through diverse sensors and information channels
Storing this information efficiently across local systems, network infrastructure, and cloud platforms
Managing complexity through intelligent processing of text, multi-modal inputs, and intricate relationships
Using context strategically by filtering for relevance, enabling cross-system sharing, and adapting based on user requirements
Why Context Engineering Matters: The Entropy Reduction Framework
Context engineering addresses a fundamental asymmetry in human-machine communication. When humans converse, we effortlessly fill conversational gaps through shared cultural knowledge, emotional intelligence, and situational awareness. Machines possess none of these capabilities.
This gap manifests as information entropy. Human communication operates efficiently because we can assume massive amounts of shared context. Machines require everything to be explicitly represented. Context engineering is fundamentally about preprocessing contexts for machines—compressing the high-entropy complexity of human intentions and situations into low-entropy representations machines can process.
As machine intelligence advances, this entropy reduction becomes increasingly automated. Today, in Era 2.0, engineers must manually orchestrate much of this reduction. In Era 3.0 and beyond, machines will handle progressively more of this burden independently. Yet the core challenge remains constant: bridging the gap between human complexity and machine comprehension.
Prompt Engineering vs. Context Engineering: Critical Distinctions
A common mistake conflates these two disciplines. In reality, they represent fundamentally different approaches to AI system architecture.
Prompt engineering centers on crafting individual instructions or queries to shape model behavior. It’s about optimizing the linguistic structure of what you communicate to the model—the phrasing, examples, and reasoning patterns within a single interaction.
Context engineering is a comprehensive systems discipline managing everything the model encounters during inference—including prompts, but also retrieved documents, memory systems, tool descriptions, state information, and more.
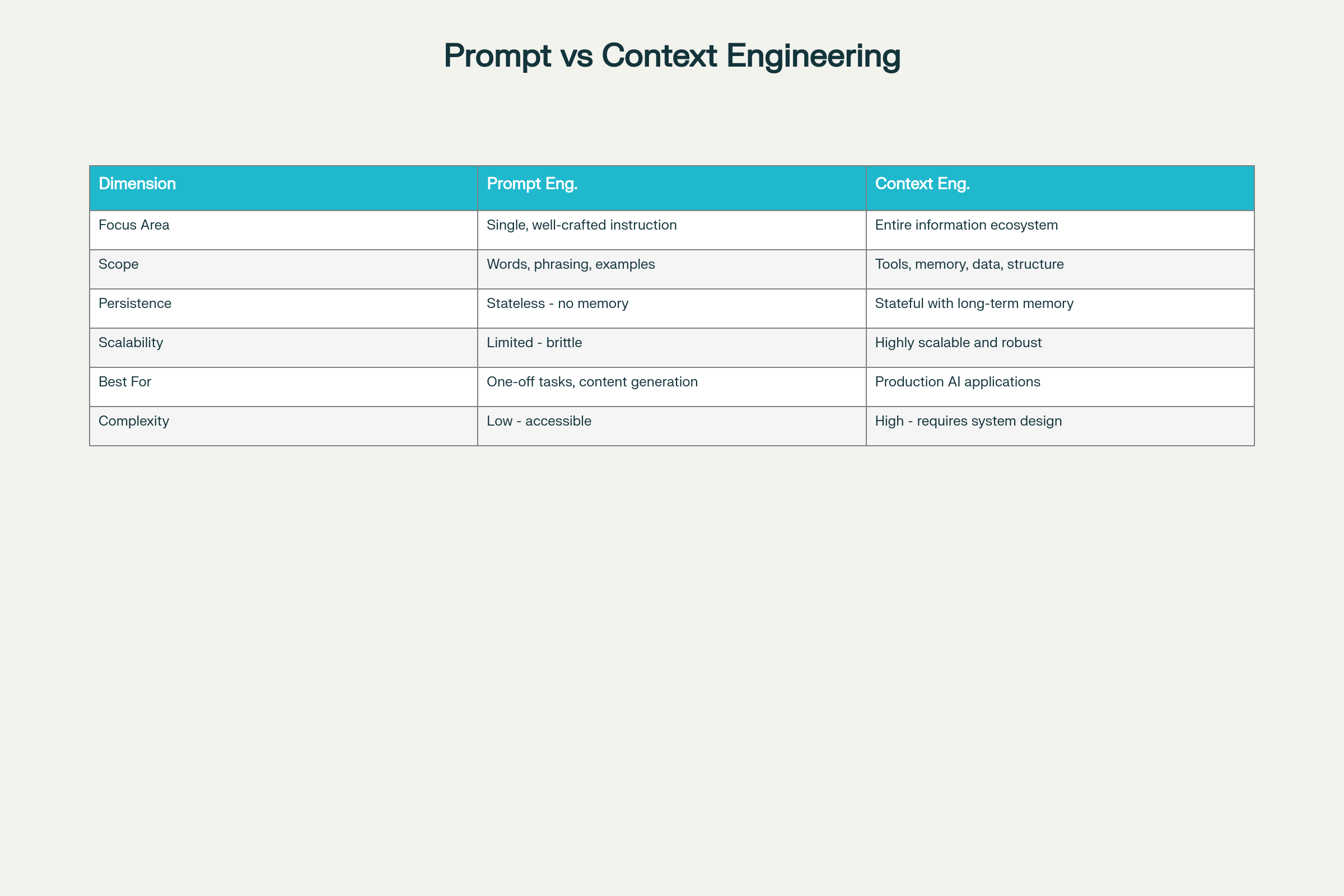
Prompt Engineering vs Context Engineering: Key Differences and Tradeoffs
Consider this distinction: Asking ChatGPT to compose a professional email is prompt engineering. Building a customer service platform that maintains conversation history across multiple sessions, accesses user account details, and remembers previous support tickets—that’s context engineering.
Key Differences Across Eight Dimensions:
Dimension
Prompt Engineering
Context Engineering
Focus Area
Individual instruction optimization
Comprehensive information ecosystem
Scope
Words, phrasing, examples
Tools, memory, data architecture, structure
Persistence
Stateless—no memory retention
Stateful with long-term memory
Scalability
Limited and brittle at scale
Highly scalable and robust
Best For
One-off tasks, content generation
Production-grade AI applications
Complexity
Low barrier to entry
High—requires system design expertise
Reliability
Unpredictable at scale
Consistent and dependable
Maintenance
Fragile to requirement changes
Modular and maintainable
The crucial insight: Production-grade LLM applications overwhelmingly require context engineering rather than merely clever prompts. As Cognition AI observed, context engineering has effectively become the primary responsibility of engineers building AI agents.
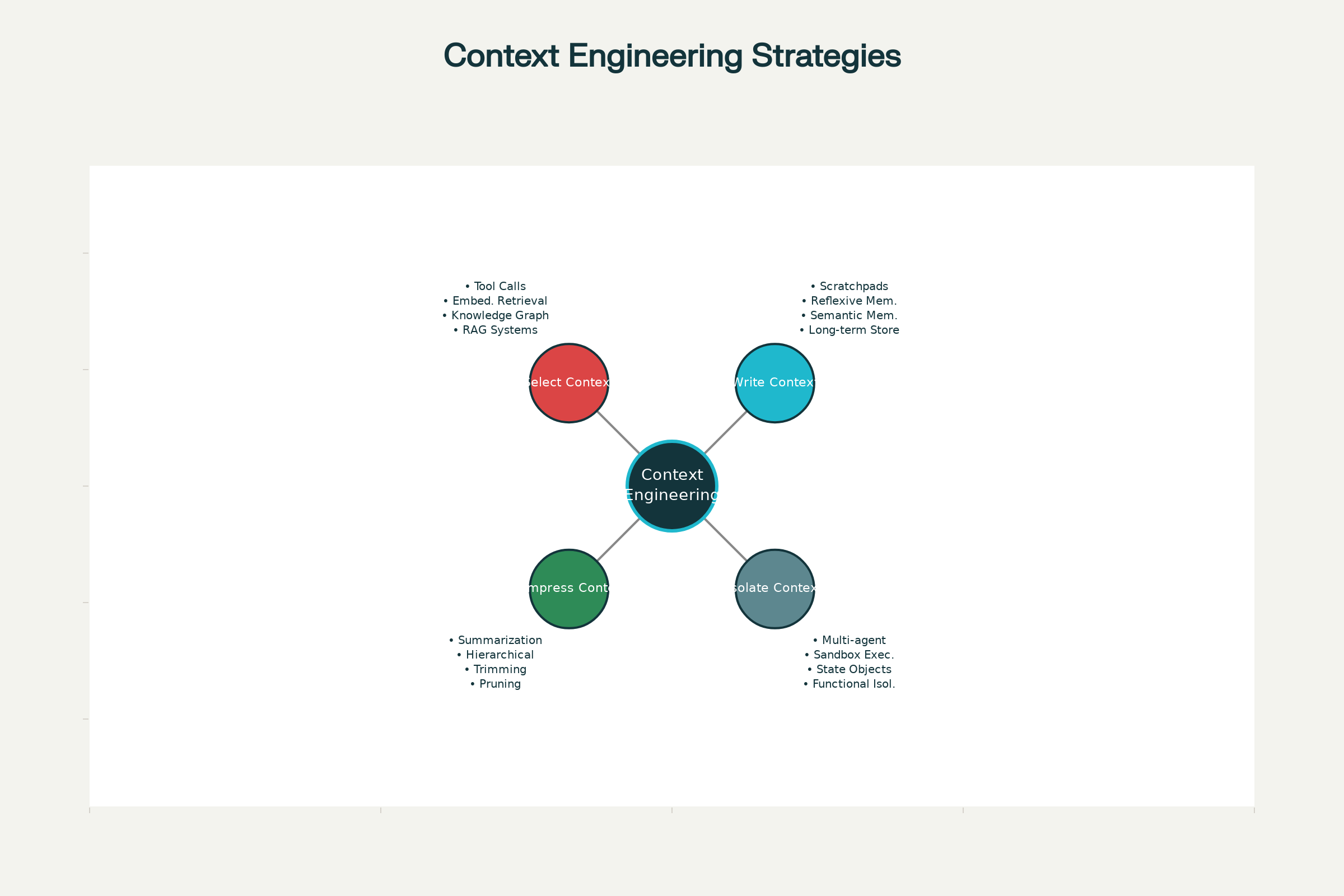
The Four Core Strategies for Context Engineering
Across leading AI systems—from Claude and ChatGPT to specialized agents developed at Anthropic and other frontier labs—four core strategies have crystallized for effective context management. These can be deployed independently or combined for greater effect.
1. Write Context: Persisting Information Outside the Context Window
The foundational principle is elegantly simple: don’t force the model to remember everything. Instead, persist critical information outside the context window where it can be reliably accessed when needed.
Scratchpads offer the most intuitive implementation. Just as humans jot notes while tackling complex problems, AI agents use scratchpads to preserve information for future reference. Implementation can be as straightforward as a tool the agent calls to save notes, or as sophisticated as fields in a runtime state object that persist across execution steps.
Anthropic’s multi-agent researcher demonstrates this beautifully: the LeadResearcher begins by formulating an approach and saving its plan to Memory for persistence, recognizing that if the context window exceeds 200,000 tokens, truncation will occur and the plan must be retained.
Memories extend the scratchpad concept across sessions. Rather than capturing information only within a single task (session-scoped memory), systems can build long-term memories that persist and evolve across many user-agent interactions. This pattern has become standard in products like ChatGPT, Claude Code, Cursor, and Windsurf.
Research initiatives like Reflexion pioneered reflective memories—having the agent reflect on each turn and generate memories for future reference. Generative Agents extended this approach by periodically synthesizing memories from collections of past feedback.
Three Types of Memories:
Episodic: Concrete examples of past behaviors or interactions (invaluable for few-shot learning)
Procedural: Instructions or rules governing behavior (ensuring consistent operation)
Semantic: Facts and relationships about the world (providing grounded knowledge)
2. Select Context: Pulling the Right Information In
Once information is preserved, the agent must retrieve only what’s relevant for the current task. Poor selection can be as detrimental as having no memory at all—irrelevant information can confuse the model or trigger hallucinations.
Memory Selection Mechanisms:
Simpler approaches employ narrow, always-included files. Claude Code uses a CLAUDE.md file for procedural memories, while Cursor and Windsurf utilize rules files. However, this approach struggles to scale when an agent has accumulated hundreds of facts and relationships.
For larger memory collections, embedding-based retrieval and knowledge graphs are commonly deployed. The system converts both memories and the current query into vector representations, then retrieves the most semantically similar memories.
Yet as Simon Willison famously demonstrated at the AIEngineer World’s Fair, this approach can fail spectacularly. ChatGPT unexpectedly injected his location from memories into a generated image, illustrating how even sophisticated systems can retrieve memories inappropriately. This underscores why meticulous engineering is essential.
Tool Selection presents its own challenge. When agents have access to dozens or hundreds of tools, simply enumerating them all can cause confusion—overlapping descriptions lead models to select inappropriate tools. One effective solution: apply RAG principles to tool descriptions. By retrieving only semantically relevant tools, systems have achieved threefold improvements in tool selection accuracy.
Knowledge Retrieval perhaps represents the richest problem space. Code agents exemplify this challenge at production scale. As one Windsurf engineer noted, indexing code doesn’t equal effective context retrieval. They perform indexing and embedding search with AST parsing and chunking along semantically meaningful boundaries. But embedding search becomes unreliable as codebases grow. Success requires combining techniques like grep/file search, knowledge graph-based retrieval, and a re-ranking step where context is ranked by relevance.
3. Compress Context: Retaining Only What’s Necessary
As agents work on long-horizon tasks, context naturally accumulates. Scratchpad notes, tool outputs, and interaction history can rapidly exceed the context window. Compression strategies address this challenge by intelligently distilling information while preserving what matters.
Summarization is the primary technique. Claude Code implements “auto-compact”—when the context window reaches 95% capacity, it summarizes the entire trajectory of user-agent interactions. This can employ various strategies:
Recursive summarization: Creating summaries of summaries to build compact hierarchies
Hierarchical summarization: Generating summaries at multiple abstraction levels
Targeted summarization: Compressing specific components (like token-heavy search results) rather than the entire context
Cognition AI revealed that they use fine-tuned models for summarization at agent-agent boundaries to reduce token usage during knowledge handoff—demonstrating the engineering depth this step can require.
Context Trimming offers a complementary approach. Rather than employing an LLM to intelligently summarize, trimming simply prunes context using hard-coded heuristics—removing older messages, filtering by importance, or using trained pruners like Provence for question-answering tasks.
The key insight: What you remove can matter as much as what you keep. A focused 300-token context often outperforms an unfocused 113,000-token context in conversation tasks.
4. Isolate Context: Splitting Information Across Systems
Finally, isolation strategies acknowledge that different tasks require different information. Rather than cramming all context into a single model’s window, isolation techniques partition context across specialized systems.
Multi-agent Architectures are the most prevalent approach. The OpenAI Swarm library was explicitly designed around “separation of concerns”—where specialized sub-agents handle specific tasks with their own tools, instructions, and context windows.
Anthropic’s research demonstrates the power of this approach: many agents with isolated contexts outperformed single-agent implementations, largely because each subagent context window can be allocated to a more narrow sub-task. Subagents operate in parallel with their own context windows, exploring different aspects of the question simultaneously.
However, multi-agent systems involve tradeoffs. Anthropic reported up to fifteen times higher token usage compared to single-agent chat. This requires careful orchestration, prompt engineering for planning, and sophisticated coordination mechanisms.
Sandbox Environments offer another isolation strategy. HuggingFace’s CodeAgent demonstrates this: instead of returning JSON that the model must reason about, the agent outputs code that executes in a sandbox. Selected outputs (return values) are passed back to the LLM, keeping token-heavy objects isolated in the execution environment. This approach excels for visual and audio data.
State Object Isolation is perhaps the most underrated technique. An agent’s runtime state can be designed as a structured schema (such as a Pydantic model) with multiple fields. One field (like messages) is exposed to the LLM at each step, while other fields remain isolated for selective use. This provides fine-grained control without architectural complexity.
Four Core Strategies for Effective Context Engineering in AI Agents
The Context Rot Problem: A Critical Challenge
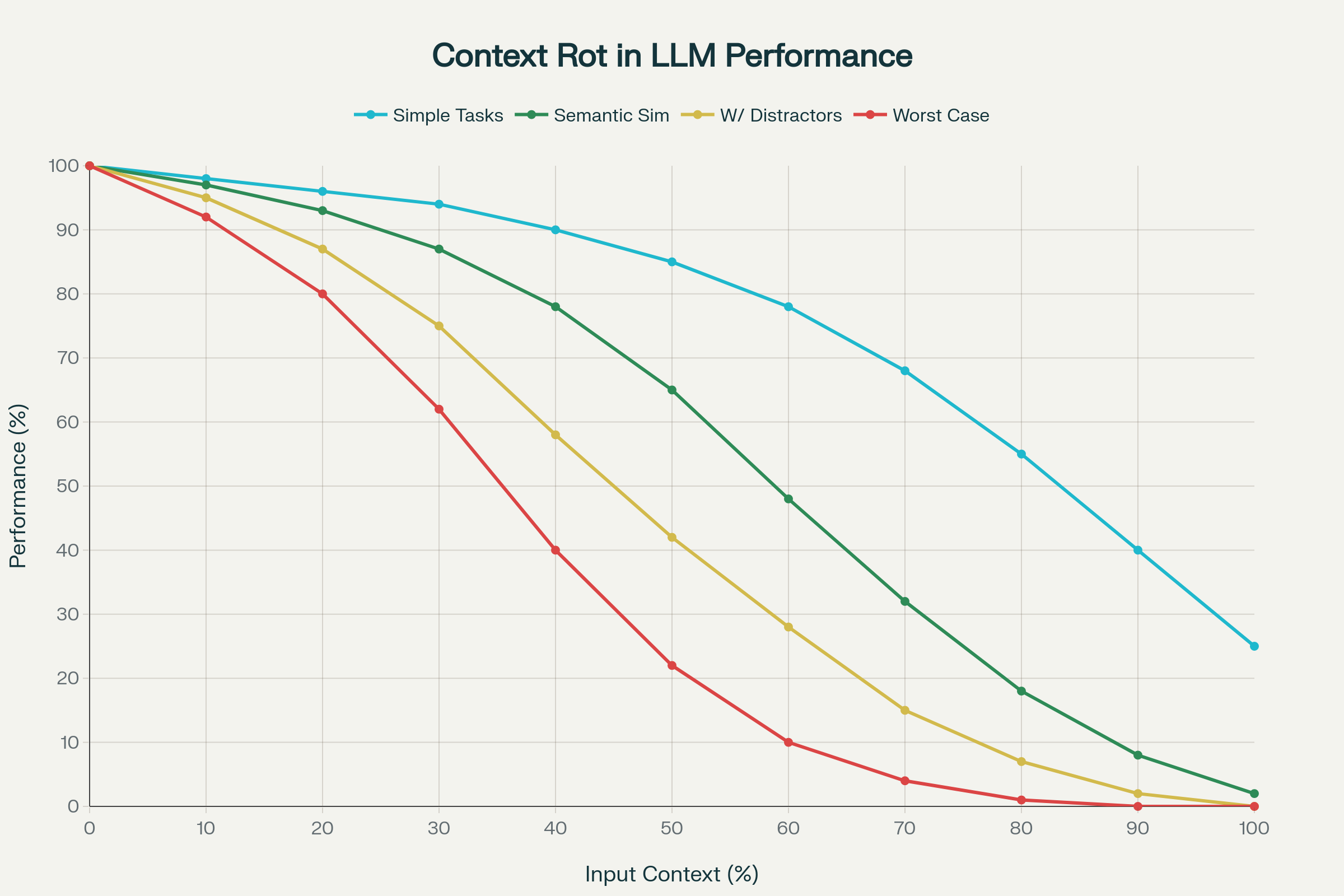
While advances in context length have been celebrated across the industry, recent research reveals a troubling reality: longer context doesn’t automatically translate to better performance.
A landmark study analyzing 18 leading LLMs—including GPT-4.1, Claude 4, Gemini 2.5, and Qwen 3—uncovered a phenomenon termed context rot: the unpredictable and often severe degradation of performance as input context expands.
Key Findings on Context Rot
1. Non-Uniform Performance Degradation
Performance doesn’t decline in a linear, predictable manner. Instead, models exhibit sharp, idiosyncratic drops depending on the specific model and task. A model might maintain 95% accuracy up to a certain context length, then suddenly plummet to 60%. These cliffs are unpredictable across different models.
2. Semantic Complexity Amplifies Context Rot
Simple tasks (like copying repeated words or exact semantic retrieval) show moderate decline. But when “needles in the haystack” require semantic similarity rather than exact matches, performance drops steeply. Adding plausible distractors—information that’s similar but not quite what the model needs—worsens accuracy dramatically.
3. Position Bias and Attention Collapse
Transformer attention doesn’t scale linearly across long contexts. Tokens at the beginning (primacy bias) and end (recency bias) receive disproportionate attention. In extreme cases, attention collapses entirely, causing the model to ignore substantial portions of input.
Gemini 2.5: Introduces unrelated fragments or punctuation
Claude Opus 4: May refuse tasks or become overly cautious
5. Real-World Impact in Conversational Settings
Perhaps most damning: in the LongMemEval benchmark, models with access to full conversations (approximately 113k tokens) performed significantly better when given only the focused 300-token segment. This demonstrates that context rot degrades both retrieval and reasoning in actual dialogue settings.
Context Rot: Performance Degradation as Input Token Length Increases Across 18 LLMs
Implications: Quality Over Quantity
The primary takeaway from context rot research is stark: the quantity of input tokens is not the sole determinant of quality. How the context is constructed, filtered, and presented is equally, if not more, vital.
This finding validates the entire context engineering discipline. Rather than viewing long context windows as a panacea, sophisticated teams recognize that careful context engineering—through compression, selection, and isolation—is essential for maintaining performance with substantial inputs.
Context Engineering in Practice: Real-World Applications
Case Study 1: Multi-Turn Agent Systems (Claude Code, Cursor)
Claude Code and Cursor represent state-of-the-art implementations of context engineering for code assistance:
Collection: These systems gather context from multiple sources—open files, project structure, edit history, terminal output, and user comments.
Management: Rather than dumping all files into the prompt, they intelligently compress. Claude Code uses hierarchical summaries. Context is tagged by function (for example, “currently edited file,” “referenced dependency,” “error message”).
Usage: At each turn, the system selects which files and context elements are relevant, presents them in a structured format, and maintains separate tracks for reasoning and visible output.
Compression: When approaching context limits, auto-compact triggers, summarizing the interaction trajectory while preserving key decisions.
Result: These tools remain usable across large projects (thousands of files) without degraded performance, despite context window constraints.
Case Study 2: Tongyi DeepResearch (Open-Source Deep Research Agent)
Tongyi DeepResearch demonstrates how context engineering enables complex research tasks:
Data Synthesis Pipeline: Rather than relying on limited human-annotated data, Tongyi uses a sophisticated data synthesis approach creating PhD-level research questions through iterative complexity upgrades. Each iteration deepens knowledge boundaries and constructs more complex reasoning tasks.
Context Management: The system uses the IterResearch paradigm—in each research round, it reconstructs a streamlined workspace using only essential outputs from the previous round. This prevents “cognitive suffocation” from accumulating all information into one context window.
Parallel Exploration: Multiple research agents operate in parallel with isolated contexts, each exploring different aspects. A synthesis agent then integrates their findings for comprehensive answers.
Results: Tongyi DeepResearch achieves performance on par with proprietary systems like OpenAI’s DeepResearch, scoring 32.9 on Humanity’s Last Exam and 75 on user-centric benchmarks.
Case Study 3: Anthropic’s Multi-Agent Researcher
Anthropic’s research demonstrates how isolation and specialization improve performance:
Architecture: Specialized sub-agents handle specific research tasks (literature review, synthesis, verification) with separate context windows.
Benefits: This approach outperformed single-agent systems, with each subagent’s context optimized for its narrow task.
Tradeoff: While superior in quality, token usage increased up to fifteen times compared to single-agent chat.
This highlights a key insight: context engineering often involves tradeoffs between quality, speed, and cost. The right balance depends on application requirements.
The Design Considerations Framework
Implementing effective context engineering requires systematic thinking across three dimensions: collection & storage, management, and usage.
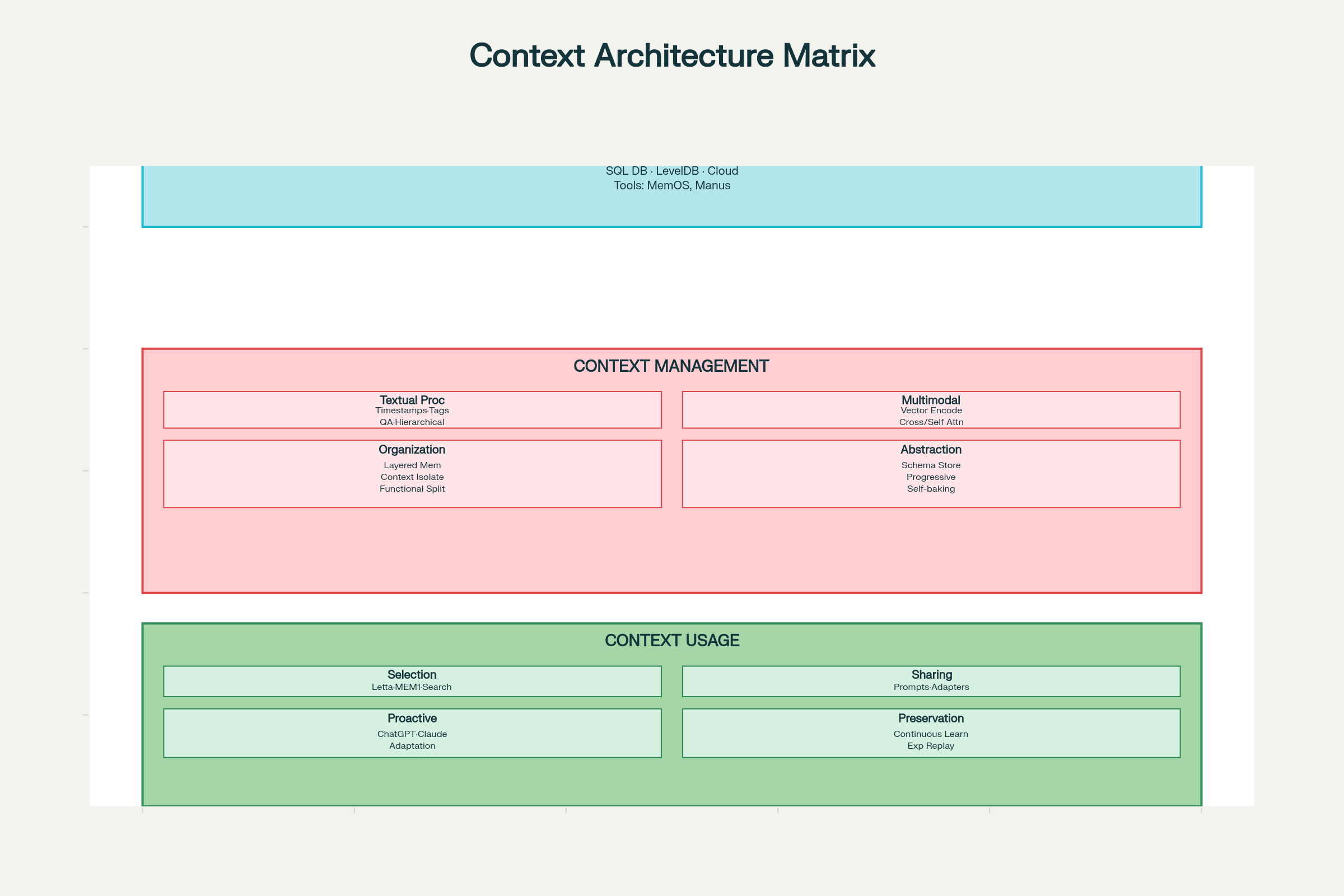
Context Engineering Design Considerations: Full System Architecture and Components
Collection & Storage Design Decisions
Storage Technology Choices:
Local Storage (SQLite, LevelDB): Fast, low-latency, suitable for client-side agents
Cloud Storage (DynamoDB, PostgreSQL): Scalable, accessible from anywhere
Distributed Systems: For massive scale with redundancy and fault tolerance
Design Patterns:
MemOS: Memory operating system for unified memory management
Manus: Structured memory with role-based access
Key principle: Design for efficient retrieval, not just storage. The optimal storage system is one where you can quickly find what you need.
Management Design Decisions
Textual Context Processing:
Timestamp Marking: Simple but limited. Preserves chronological order but provides no semantic structure, leading to scalability issues as interactions accumulate.
Role/Function Tagging: Tag each context element with its function—“goal,” “decision,” “action,” “error,” and so forth. Supports multi-dimensional tagging (priority, source, confidence). Recent systems like LLM4Tag enable this at scale.
Compression with QA Pairs: Convert interactions into compressed question-answer pairs, preserving essential information while reducing tokens.
Hierarchical Notes: Progressive compression into meaning vectors, as in H-MEM systems, capturing semantic essence across multiple abstraction levels.
Multi-modal Context Processing:
Comparable Vector Spaces: Encode all modalities (text, image, audio) into comparable vector spaces using shared embedding models (as in ChatGPT and Claude).
Cross-Attention: Use one modality to guide attention to another (as in Qwen2-VL).
Independent Encoding with Self-Attention: Encode modalities separately, then combine through unified attention mechanisms.
Context Organization:
Layered Memory Architecture: Separate working memory (current context), short-term memory (recent history), and long-term memory (persistent facts).
Functional Context Isolation: Use sub-agents with separate context windows for different functions (Claude’s approach).
Context Abstraction (Self-Baking):
The term “self-baking” refers to a context’s ability to improve through repeated processing. Patterns include:
Store raw context, then add natural-language summaries (Claude Code, Gemini CLI)
Extract key facts using fixed schemas (ChatSchema approach)
Progressively compress into meaning vectors (H-MEM systems)
Embedding selected context into prompts (AutoGPT, ChatDev approach)
Structured message exchange between agents (Letta, MemOS)
Shared memory via indirect communication (A-MEM systems)
Across systems:
Adapters that convert context format (Langroid)
Shared representations across platforms (Sharedrop)
Proactive User Inference:
ChatGPT and Claude analyze interaction patterns to anticipate user needs
Context systems learn to surface information before explicitly requested
Balance between helpfulness and privacy remains a key design challenge
Context Engineering Skills and What Teams Need to Master
As context engineering becomes increasingly central to AI development, certain skills separate effective teams from those struggling to scale.
1. Strategic Context Assembly
Teams must understand what information serves each task. This isn’t just about gathering data—it’s about understanding task requirements deeply enough to know what’s truly necessary versus what’s distracting noise.
In Practice:
Analyze task failure modes to identify missing context
A/B test different context combinations to measure impact
Build observability to track which context elements drive performance
2. Memory System Architecture
Designing effective memory systems requires understanding different memory types and when to use them:
When should information be in short-term versus long-term memory?
How should different memory types interact?
What compression strategies maintain fidelity while reducing tokens?
3. Semantic Search and Retrieval
Moving beyond simple keyword matching, teams need expertise in:
Embedding models and their limitations
Vector similarity metrics and their tradeoffs
Re-ranking and filtering strategies
Handling ambiguous queries
4. Token Economy and Cost Analysis
Every byte of context carries tradeoffs:
Monitor token usage across different context compositions
Understand model-specific token processing costs
Balance quality against cost and latency
5. System Orchestration
With multiple agents, tools, and memory systems, careful orchestration becomes essential:
Coordination between sub-agents
Failure mode handling and recovery
State management across long-horizon tasks
6. Evaluation and Measurement
Context engineering is fundamentally an optimization discipline:
Define metrics that capture performance
A/B test context engineering approaches
Measure impact on end-user experience, not just model accuracy
As one senior engineer noted, the fastest path to delivering quality AI software to customers involves taking small, modular concepts from agent building and incorporating them into existing products.
Best Practices for Implementing Context Engineering
1. Start Simple, Evolve Deliberately
Begin with basic prompt engineering plus scratchpad-style memory. Only add complexity (multi-agent isolation, sophisticated retrieval) when you have clear evidence it’s necessary.
2. Measure Everything
Use tools like LangSmith for observability. Track:
Token usage across context engineering approaches
Performance metrics (accuracy, correctness, user satisfaction)
Cost and latency tradeoffs
3. Automate Memory Management
Manual memory curation doesn’t scale. Implement:
Automated summarization at context boundaries
Intelligent filtering and relevance scoring
Decay functions for older information
4. Design for Clarity and Auditability
Context quality matters more when you can understand what the model sees. Use:
Clear, structured formats (JSON, Markdown)
Tagged context with explicit roles
Separation of concerns across context components
5. Build Context-First, Not LLM-First
Rather than starting with “which LLM should we use,” start with “what context does this task require?” The LLM becomes a component in a larger context-driven system.
6. Embrace Layered Architectures
Separate:
Working memory (current context window)
Short-term memory (recent interactions)
Long-term memory (persistent facts)
Each layer serves different purposes and can be optimized independently.
Challenges and Future Directions
Current Challenges
1. Context Rot and Scaling
While techniques exist to mitigate context rot, the fundamental problem remains unsolved. As inputs grow, sophisticated selection and compression mechanisms become increasingly necessary.
2. Memory Consistency and Coherence
Maintaining consistency across different memory types and time scales presents challenges. Conflicting memories or outdated information can degrade performance.
3. Privacy and Selective Disclosure
As systems maintain richer context about users, balancing personalization with privacy becomes critical. The “context window no longer belongs to them” problem emerges when unexpected information surfaces.
4. Computational Overhead
Sophisticated context engineering adds computational cost. Selection, compression, and retrieval mechanisms all consume resources. Finding the right balance remains an open challenge.
Promising Future Directions
1. Learned Context Engineers
Rather than hand-engineering context management, systems could learn optimal context selection strategies through meta-learning or reinforcement learning.
2. Emergence of Symbolic Mechanisms
Recent research suggests LLMs develop emergent symbolic processing mechanisms. Leveraging these could enable more sophisticated context abstraction and reasoning.
3. Cognitive Tools and Prompt Programming
Frameworks like IBM’s “Cognitive Tools” approach encapsulate reasoning operations as modular components. This treats context engineering more like composable software—small, reusable pieces that work together.
4. Neural Field Theory for Context
Rather than discrete context elements, modeling context as a continuous neural field could enable smoother, more adaptive context management.
5. Quantum Semantics and Superposition
Early research explores whether context could leverage quantum superposition concepts—where information exists in multiple states until needed. This could radically change how we store and retrieve context.
Conclusion: Why Context Engineering Matters Now
We stand at an inflection point in AI development. For years, the focus was on making models larger and smarter. The question was: “How can we improve the LLM?”
Today’s frontier question is different: “How can we engineer systems around LLMs to extract their full potential?”
Context engineering answers that question. It’s not a narrow technical hack—it’s a fundamental discipline for building AI systems that are reliable, scalable, and genuinely useful in production environments.
The evidence is overwhelming. Teams at Anthropic, Alibaba (Tongyi), and leading tech companies have proven that sophisticated context engineering beats raw model scale. A small, well-engineered team with a less powerful model, guided by careful context management, consistently outperforms large teams with access to frontier models but poor context discipline.
This has profound implications:
Context engineering democratizes AI: You don’t need the largest model; you need the best-engineered context for your task.
It’s becoming a core competency: Engineering teams that master context engineering will have outsized impact on AI outcomes.
It’s foundational for agents: As AI moves from single-turn interactions to long-horizon, multi-step reasoning, context engineering becomes non-negotiable.
It’s here to stay: Regardless of how much smarter future models become, the challenge of filling the context window wisely will remain.
The next generation of AI systems will be defined not by their language model parameters, but by how thoughtfully their contexts are engineered.
References and Further Reading
For teams wanting to deepen their context engineering expertise, these resources provide both theoretical foundation and practical implementation guidance:
Context Engineering 2.0: The Context of Context Engineering — Comprehensive paper covering 20+ years of context evolution across four eras
LangChain’s Context Engineering Guide — Practical patterns for write, select, compress, and isolate strategies
Tongyi DeepResearch — Production example of sophisticated context engineering for research agents
12-Factor Agents — Principles for building reliable LLM applications, including context window management
Context Rot Research — Understanding how to mitigate performance degradation with increased input length
Prompt engineering focuses on crafting a single instruction for an LLM. Context engineering is a broader systems discipline that manages the entire information ecosystem for an AI model, including memory, tools, and retrieved data, to optimize performance on complex, stateful tasks.
Context rot is the unpredictable degradation of an LLM's performance as its input context grows longer. Models may exhibit sharp drops in accuracy, ignore parts of the context, or hallucinate, highlighting the need for quality and careful management of context over sheer quantity.
The four core strategies are: 1. Write Context (persisting information outside the context window, like scratchpads or memory), 2. Select Context (retrieving only relevant information), 3. Compress Context (summarizing or trimming to save space), and 4. Isolate Context (using multi-agent systems or sandboxes to separate concerns).
Arshia is an AI Workflow Engineer at FlowHunt. With a background in computer science and a passion for AI, he specializes in creating efficient workflows that integrate AI tools into everyday tasks, enhancing productivity and creativity.
Arshia Kahani
AI Workflow Engineer
Master Context Engineering
Ready to build the next generation of AI systems? Explore our resources and tools to implement advanced context engineering in your projects.
Long Live Context Engineering: Building Production AI Systems with Modern Vector Databases
Explore how context engineering is reshaping AI development, the evolution from RAG to production-ready systems, and why modern vector databases like Chroma are...
How to Use AI Chatbot Prompts: Complete Guide to Effective Prompt Engineering
Master AI chatbot prompts with our comprehensive guide. Learn the CARE framework, prompt engineering techniques, and best practices to get better AI responses. ...
Explore Andrej Karpathy's nuanced perspective on AGI timelines, AI agents, and why the next decade will be critical for artificial intelligence development. Und...
20 min read
AI
AGI
+3
Cookie Consent We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.