Human in the Loop Middleware in Python: Building Safe AI Agents with Approval Workflows
Learn how to implement human-in-the-loop middleware in Python using LangChain to add approval, editing, and rejection capabilities to AI agents before tool execution.
Building AI agents that can autonomously execute tools and take actions is powerful, but it comes with inherent risks. What happens when an agent decides to send an email with incorrect information, approve a large financial transaction, or modify critical database records? Without proper safeguards, autonomous agents can cause significant damage before anyone realizes what happened. This is where human-in-the-loop middleware becomes essential. In this comprehensive guide, we’ll explore how to implement human-in-the-loop middleware in Python using LangChain, enabling you to build AI agents that pause for human approval before executing sensitive operations. You’ll learn how to add approval workflows, implement editing capabilities, and handle rejections—all while maintaining the efficiency and intelligence of your autonomous systems.
Understanding AI Agent Loops and Tool Execution
Before diving into human-in-the-loop middleware, it’s crucial to understand how AI agents fundamentally work. An AI agent operates through a continuous loop that repeats until the agent decides it has completed its task. The core agent loop consists of three primary components: a language model that reasons about what to do next, a set of tools that the agent can invoke to take action, and a state management system that tracks the conversation history and any relevant context. The agent begins by receiving an input message from a user, then the language model analyzes this input along with the available tools and decides whether to call a tool or provide a final response. If the model decides to call a tool, that tool is executed, and the results are added back to the conversation history. This cycle continues—model reasoning, tool selection, tool execution, result integration—until the model determines that no further tool calls are needed and provides a final response to the user.
This simple yet powerful pattern has become the foundation for hundreds of AI agent frameworks over the past few years. The elegance of the agent loop lies in its flexibility: by changing the tools available to an agent, you can enable it to perform vastly different tasks. An agent with email tools can manage communications, an agent with database tools can query and update records, and an agent with financial tools can process transactions. However, this flexibility also introduces risk. Because the agent loop operates autonomously, there’s no built-in mechanism to pause and ask a human whether a particular action should actually be taken. The model might decide to send an email, execute a database query, or approve a financial transaction, and by the time a human realizes what happened, the action has already been completed. This is where the limitations of the basic agent loop become apparent in production environments.
Ready to grow your business?
Start your free trial today and see results within days.
Why Human Oversight Matters in Production AI Systems
As AI agents become more capable and are deployed in real-world business environments, the need for human oversight becomes increasingly critical. The stakes of autonomous agent actions vary dramatically depending on the context. Some tool calls are low-risk and can be executed immediately without human review—for example, reading an email or retrieving information from a database. Other tool calls are high-stakes and potentially irreversible, such as sending communications on behalf of a user, transferring funds, deleting records, or making commitments that bind an organization. In production systems, the cost of an agent making a mistake on a high-stakes operation can be enormous. A misworded email sent to the wrong recipient could damage business relationships. An incorrectly approved budget could lead to financial losses. A database deletion executed by mistake could result in data loss that takes hours or days to recover from backups.
Beyond the immediate operational risks, there are also compliance and regulatory considerations. Many industries have strict requirements that certain types of decisions must involve human judgment and approval. Financial institutions must have human oversight of transactions above certain thresholds. Healthcare systems must have human review of certain automated decisions. Legal firms must ensure that communications are reviewed before being sent on behalf of clients. These regulatory requirements aren’t just bureaucratic overhead—they exist because the consequences of fully autonomous decision-making in these domains can be severe. Additionally, human oversight provides a feedback mechanism that helps improve the agent over time. When a human reviews an agent’s proposed action and either approves it or suggests edits, that feedback can be used to refine the agent’s prompts, adjust its tool selection logic, or retrain its underlying models. This creates a virtuous cycle where the agent becomes more reliable and better calibrated to the organization’s specific needs and risk tolerance.
What is Human-in-the-Loop Middleware?
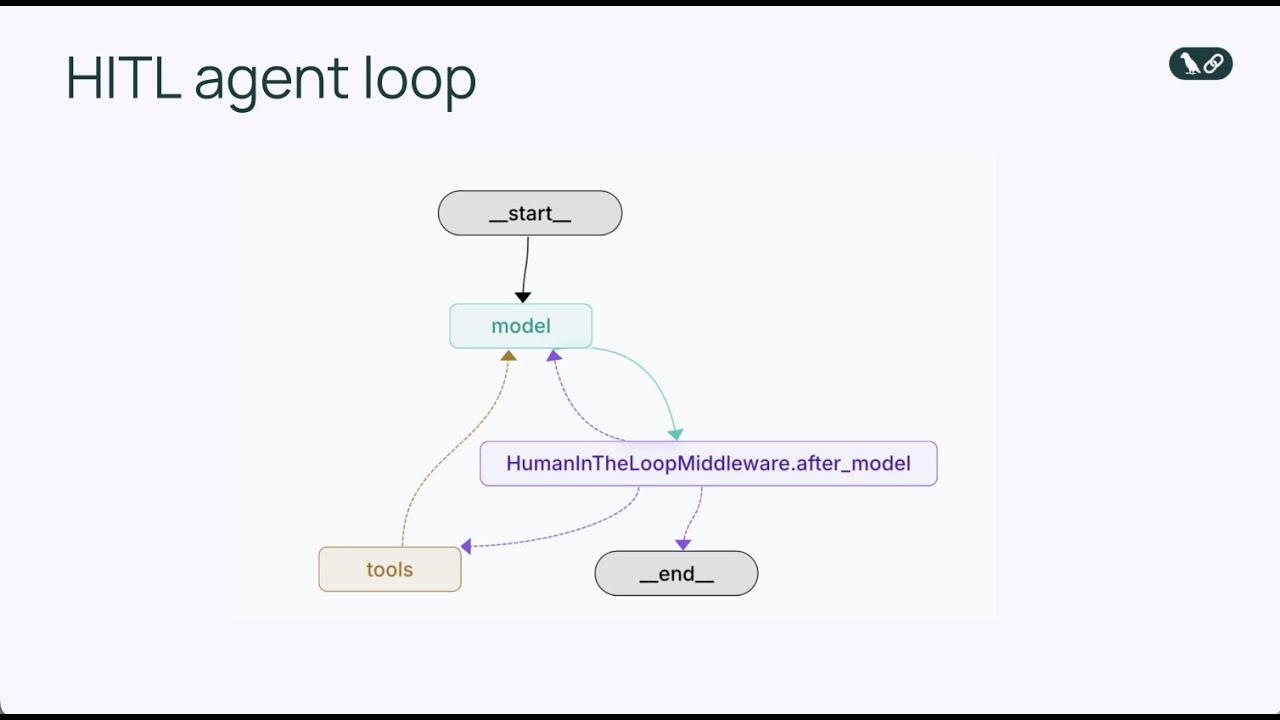
Human-in-the-loop middleware is a specialized component that intercepts the agent loop at a critical juncture: right before a tool is executed. Instead of allowing the agent to immediately run a tool call, the middleware pauses execution and presents the proposed action to a human for review. The human then has several options for how to respond. They can approve the action, allowing it to proceed exactly as the agent proposed. They can edit the action, modifying the parameters (such as changing the email recipient or adjusting the message content) before allowing execution. Or they can reject the action entirely, sending feedback back to the agent explaining why the action was inappropriate and asking it to reconsider its approach. This three-way decision mechanism—approve, edit, reject—provides a flexible framework that accommodates different types of human oversight needs.
The middleware operates by modifying the standard agent loop to include an additional decision point. In the basic agent loop, the sequence is: model calls tools → tools execute → results return to model. With human-in-the-loop middleware, the sequence becomes: model calls tools → middleware intercepts → human reviews → human decides (approve/edit/reject) → if approved or edited, tool executes → results return to model. This insertion of a human decision point doesn’t break the agent loop; rather, it enhances it by adding a safety valve. The middleware is configurable, meaning you can specify exactly which tools should trigger human review and which tools can execute automatically. You might want to interrupt on all email-sending tools but allow read-only database queries to execute without review. This granular control ensures that you’re adding human oversight exactly where it’s needed without creating unnecessary bottlenecks for low-risk operations.
Join our newsletter
Get latest tips, trends, and deals for free.
The Three Response Types: Approval, Editing, and Rejection
When a human-in-the-loop middleware interrupts an agent’s tool execution, the human reviewer has three primary ways to respond, each serving a different purpose in the approval workflow. Understanding these three response types is essential for designing effective human-in-the-loop systems.
Approval is the simplest response type. When a human reviews a proposed tool call and determines that it’s appropriate and should proceed exactly as the agent proposed, they provide an approval decision. This signals to the middleware that the tool should execute with the exact parameters that the agent specified. In the context of an email assistant, approval means the email draft looks good and should be sent to the specified recipient with the specified subject line and body text. Approval is the path of least resistance—it allows the agent’s proposed action to proceed without modification. This is appropriate when the agent has done its job well and the human reviewer agrees with the proposed action. Approval decisions are typically fast to make, which is important because you don’t want human review to become a bottleneck that slows down your entire workflow.
Editing is a more nuanced response type that acknowledges that the agent’s general approach is correct, but some details need adjustment before execution. When a human provides an edit response, they’re not rejecting the agent’s decision to take action; rather, they’re refining the specifics of how that action should be taken. In an email scenario, editing might mean changing the recipient email address, modifying the subject line to be more professional, or adjusting the body text to include additional context or remove potentially problematic language. The key characteristic of an edit response is that it modifies the tool parameters while keeping the same tool call. The agent decided to send an email, and the human agrees that sending an email is the right action, but the human wants to adjust what that email says or who it goes to. After the human provides their edits, the tool executes with the modified parameters, and the results return to the agent. This approach is particularly valuable because it allows the agent to propose actions while giving humans the ability to fine-tune those actions based on their domain expertise or knowledge of organizational context that the agent might not have.
Rejection is the most significant response type because it not only stops the proposed action from executing but also sends feedback back to the agent explaining why the action was inappropriate. When a human rejects a tool call, they’re saying that the agent’s proposed action should not be taken at all, and they’re providing guidance on how the agent should reconsider its approach. In the email example, rejection might occur when the agent proposes to send an email approving a major budget request without sufficient detail or justification. The human rejects this action and provides a message back to the agent explaining that more detail is needed before approval can be given. This rejection message becomes part of the agent’s context, and the agent can then reason about this feedback and propose a revised approach. The agent might then propose a different email that asks for more information about the budget proposal before committing to approval. Rejection responses are crucial for preventing the agent from repeatedly proposing the same inappropriate action. By providing clear feedback about why an action was rejected, you help the agent learn and improve its decision-making.
Implementing Human-in-the-Loop Middleware: A Practical Example
Let’s walk through a concrete implementation of human-in-the-loop middleware using LangChain and Python. The example we’ll use is an email assistant—a practical scenario that demonstrates the value of human oversight while being easy to understand. The email assistant will have the ability to send emails on behalf of a user, and we’ll add human-in-the-loop middleware to ensure that all email sends are reviewed before execution.
First, we need to define the email tool that our agent will use. This tool takes three parameters: a recipient email address, a subject line, and the email body. The tool is straightforward—it simply represents the action of sending an email. In a real implementation, this might integrate with an email service like Gmail or Outlook, but for demonstration purposes, we can keep it simple. Here’s the basic structure:
defsend_email(recipient: str, subject: str, body: str) -> str:
"""Send an email to the specified recipient."""returnf"Email sent to {recipient} with subject '{subject}'"
Next, we create an agent that uses this email tool. We’ll use GPT-4 as the language model and provide a system prompt that tells the agent it’s a helpful email assistant. The agent is initialized with the email tool and is ready to respond to user requests:
from langchain.agents import create_agent
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o")
tools = [send_email]
agent = create_agent(
model=model,
tools=tools,
system_prompt="You are a helpful email assistant for Sydney. You can send emails on behalf of the user.")
At this point, we have a basic agent that can send emails. However, there’s no human oversight—the agent can send emails without any review. Now let’s add the human-in-the-loop middleware. The implementation is remarkably simple, requiring just two lines of code:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
system_prompt="You are a helpful email assistant for Sydney. You can send emails on behalf of the user.",
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={"send_email": True}
)
]
)
By adding the HumanInTheLoopMiddleware and specifying interrupt_on={"send_email": True}, we’re telling the agent to pause before executing any send_email tool calls and wait for human approval. The True value means that all send_email calls will trigger an interrupt with default configuration. If we wanted more granular control, we could specify which types of decisions are allowed (approve, edit, reject) or provide custom descriptions for the interrupt.
Testing the Middleware with Low-Stakes Scenarios
Once the middleware is in place, let’s test it with a low-stakes email scenario. Imagine a user asks the agent to respond to a casual email from a colleague named Alice who’s suggesting coffee next week. The agent processes this request and decides to send a friendly response email. Here’s what happens:
The user sends a message: “Please respond to Alice’s email about grabbing coffee next week.”
The agent’s language model processes this and decides to call the send_email tool with parameters like recipient=“alice@example.com
”, subject=“Coffee next week?”, body=“I’d love to grab coffee with you next week!”
Before the email actually sends, the middleware intercepts the tool call and raises an interrupt.
The human reviewer sees the proposed email and reviews it. The email looks appropriate—it’s friendly, professional, and addresses the user’s request.
The human approves the action by providing an approval decision.
The middleware allows the tool to execute, and the email is sent.
This workflow demonstrates the basic approval path. The human review adds a safety layer without significantly slowing down the process. For low-stakes operations like this, the approval typically happens quickly because the agent’s proposed action is reasonable and doesn’t require modification.
Testing the Middleware with High-Stakes Scenarios: The Edit Response
Now let’s consider a more consequential scenario where editing becomes valuable. Imagine the agent receives a request to respond to an email from a startup partner asking the user to sign off on a $1 million engineering budget for Q1. This is a high-stakes decision that requires careful consideration. The agent might propose an email that says something like: “I’ve reviewed and approved the proposal for the $1 million engineering budget for Q1.”
When this proposed email reaches the human reviewer through the middleware interrupt, the human recognizes that this is a significant financial commitment that shouldn’t be approved without more careful consideration. The human doesn’t want to reject the entire idea of responding to the email, but they want to modify the response to be more cautious. The human provides an edit response that modifies the email body to say something like: “Thank you for the proposal. I’d like to review the details more carefully before providing approval. Can you send me a breakdown of how the budget will be allocated?”
Here’s what an edit response looks like in code:
edit_decision = {
"type": "edit",
"edited_action": {
"name": "send_email",
"args": {
"recipient": "partner@startup.com",
"subject": "Q1 Engineering Budget Proposal",
"body": "Thank you for the proposal. I'd like to review the details more carefully before providing approval. Can you send me a breakdown of how the budget will be allocated?" }
}
}
When the middleware receives this edit decision, it executes the tool with the modified parameters. The email is sent with the human’s revised content, which is more appropriate for a high-stakes financial decision. This demonstrates the power of the edit response type: it allows humans to leverage the agent’s ability to draft communications while ensuring that the final output reflects human judgment and organizational standards.
Testing the Middleware with Rejection and Feedback
The rejection response type is particularly powerful because it not only stops an inappropriate action but also provides feedback that helps the agent improve its reasoning. Let’s consider another scenario with the same high-stakes budget email. Suppose the agent proposes an email that says: “I’ve reviewed and approved the $1 million engineering budget for Q1.”
The human reviewer sees this and recognizes that this is far too hasty. A $1 million commitment shouldn’t be approved without extensive review, discussion with stakeholders, and understanding of the budget details. The human doesn’t just want to edit the email; they want to reject this entire approach and ask the agent to reconsider. The human provides a rejection response with feedback:
reject_decision = {
"type": "reject",
"message": "I cannot approve this budget without more information. Please draft an email asking for a detailed breakdown of the proposal, including how the funds will be allocated across different engineering teams and what specific deliverables are expected."}
When the middleware receives this rejection decision, it doesn’t execute the tool. Instead, it sends the rejection message back to the agent as part of the conversation context. The agent now sees that its proposed action was rejected and understands why. The agent can then reason about this feedback and propose a different approach. In this case, the agent might propose a new email that asks for more details about the budget proposal, which is a more appropriate response to a high-stakes financial request. The human can then review this revised proposal and either approve it, edit it further, or reject it again if needed.
This iterative process—propose, review, reject with feedback, propose again—is one of the most valuable aspects of human-in-the-loop middleware. It creates a collaborative workflow where the agent’s speed and reasoning capabilities are combined with human judgment and domain expertise.
Supercharge Your Workflow with FlowHunt
Experience how FlowHunt automates your AI content and SEO workflows — from research and content generation to publishing and analytics — all in one place.
Advanced Configuration: Granular Control Over Interrupts
While the basic implementation of human-in-the-loop middleware is simple, LangChain provides more advanced configuration options that allow you to fine-tune exactly how and when interrupts occur. One important configuration option is specifying which types of decisions are allowed for each tool. For example, you might want to allow approval and editing for email sends, but not rejection. Or you might want to allow all three decision types for financial transactions but only approval for read-only database queries.
Here’s an example of more granular configuration:
from langchain.agents.middleware import HumanInTheLoopMiddleware
agent = create_agent(
model=model,
tools=tools,
middleware=[
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"]
},
"read_database": False, # Auto-approve, no interrupt"delete_record": {
"allowed_decisions": ["approve", "reject"] # No editing for deletes }
}
)
]
)
In this configuration, email sends will interrupt and allow all three decision types. Read operations will execute automatically without interruption. Delete operations will interrupt but won’t allow editing—the human can only approve or reject, not modify the delete parameters. This granular control ensures that you’re adding human oversight exactly where it’s needed while avoiding unnecessary bottlenecks for low-risk operations.
Another advanced feature is the ability to provide custom descriptions for interrupts. By default, the middleware provides a generic description like “Tool execution requires approval.” You can customize this to provide more context-specific information:
HumanInTheLoopMiddleware(
interrupt_on={
"send_email": {
"allowed_decisions": ["approve", "edit", "reject"],
"description": "Email sends require human approval before execution" }
}
)
Important Implementation Considerations: Checkpointers and State Management
One critical aspect of implementing human-in-the-loop middleware that’s easy to overlook is the need for a checkpointer. A checkpointer is a mechanism that saves the state of the agent at the point of interruption, allowing the workflow to be resumed later. This is essential because human review doesn’t happen instantaneously—there might be a delay between when the interrupt occurs and when the human provides their decision. Without a checkpointer, the agent’s state would be lost during this delay, and you wouldn’t be able to resume the workflow properly.
LangChain provides several checkpointer options. For development and testing, you can use an in-memory checkpointer:
For production systems, you’ll typically want to use a persistent checkpointer that saves state to a database or file system, ensuring that interrupts can be resumed even if the application restarts. The checkpointer maintains a complete record of the agent’s state at each step, including the conversation history, any tool calls that have been made, and the results of those calls. When a human provides a decision (approve, edit, or reject), the middleware uses the checkpointer to retrieve the saved state, apply the human’s decision, and resume the agent loop from that point.
Real-World Applications and Use Cases
Human-in-the-loop middleware is applicable to a wide variety of real-world scenarios where autonomous agents need to take actions but those actions require human oversight. In the financial services industry, agents that process transactions, approve loans, or manage investments can use human-in-the-loop middleware to ensure that high-value decisions are reviewed by qualified humans before execution. In healthcare, agents that might recommend treatments or access patient records can use middleware to ensure compliance with privacy regulations and clinical protocols. In legal services, agents that draft communications or access confidential documents can use middleware to ensure that attorney oversight is maintained. In customer service, agents that might issue refunds, make commitments to customers, or escalate issues can use middleware to ensure that these actions align with company policies.
Beyond these industry-specific applications, human-in-the-loop middleware is valuable in any scenario where the cost of an agent making a mistake is significant. This includes content moderation systems where agents might remove user-generated content, HR systems where agents might process employment decisions, and supply chain systems where agents might place orders or adjust inventory. The common thread across all these applications is that the agent’s proposed actions have real consequences, and those consequences are significant enough to warrant human review before execution.
Comparison with Alternative Approaches
It’s worth considering how human-in-the-loop middleware compares to alternative approaches for adding human oversight to agent systems. One alternative is to have humans review all agent outputs after execution, but this approach has significant limitations. By the time a human reviews an action, it’s already been executed, and reversing the action might be difficult or impossible. An email has already been sent, a database record has already been deleted, or a financial transaction has already been processed. Human-in-the-loop middleware prevents these irreversible actions from happening in the first place.
Another alternative is to have humans manually perform all the tasks that agents might do, but this defeats the purpose of having agents in the first place. Agents are valuable precisely because they can handle routine tasks quickly and efficiently, freeing humans to focus on higher-level decision-making. The goal of human-in-the-loop middleware is to find the right balance: let agents handle the routine work, but pause for human review when the stakes are high.
A third alternative is to implement guardrails or validation rules that prevent agents from taking inappropriate actions. For example, you might implement a rule that prevents an agent from sending emails to addresses outside your organization or deleting records without explicit confirmation. While guardrails are valuable and should be used in conjunction with human-in-the-loop middleware, they have limitations. Guardrails are typically rule-based and can’t account for all possible inappropriate actions. An agent might pass all your guardrails but still propose an action that’s inappropriate in a specific context. Human judgment is more flexible and context-aware than rule-based guardrails, which is why human-in-the-loop middleware is so valuable.
Best Practices for Implementing Human-in-the-Loop Workflows
When implementing human-in-the-loop middleware in your applications, several best practices can help ensure that your system is both effective and efficient. First, be strategic about which tools require interrupts. Interrupting on every single tool call will create bottlenecks and slow down your workflow. Instead, focus interrupts on tools that are expensive, risky, or have significant consequences if executed incorrectly. Read-only operations typically don’t need interrupts. Write operations that modify data or take external actions typically do.
Second, provide clear context to human reviewers. When an interrupt occurs, the human needs to understand what action the agent is proposing and why. Make sure your interrupt descriptions are clear and provide relevant context. If the agent is proposing to send an email, show the full email content. If the agent is proposing to delete a record, show what record is being deleted and why. The more context you provide, the faster and more accurate human decisions will be.
Third, make the approval process as frictionless as possible. Humans are more likely to approve actions quickly if the process is simple and doesn’t require extensive navigation or data entry. Provide clear buttons or options for approve, edit, and reject. If editing is allowed, make it easy for humans to modify the relevant parameters without having to understand the underlying code or data structures.
Fourth, use rejection feedback strategically. When rejecting an agent’s proposed action, provide clear feedback about why the action was inappropriate and what the agent should do instead. This feedback helps the agent learn and improve its decision-making. Over time, as the agent receives feedback on its proposals, it should become better calibrated to your organization’s standards and risk tolerance.
Fifth, monitor and analyze interrupt patterns. Keep track of which tools are being interrupted most frequently, which decisions (approve, edit, reject) are most common, and how long the approval process takes. This data can help you identify bottlenecks, refine your interrupt configuration, and potentially improve your agent’s prompts or tool selection logic.
Integrating Human-in-the-Loop Middleware with FlowHunt
For organizations looking to implement human-in-the-loop workflows at scale, FlowHunt provides a comprehensive platform that integrates seamlessly with LangChain’s middleware capabilities. FlowHunt enables you to build, deploy, and manage AI agents with built-in approval workflows, making it easy to add human oversight to your automation processes. With FlowHunt, you can configure which tools require human approval, customize the approval interface for your specific needs, and track all approvals and rejections for compliance and audit purposes. The platform handles the complexity of state management, checkpointing, and workflow orchestration, allowing you to focus on building effective agents and defining appropriate approval policies. FlowHunt’s integration with LangChain means you can leverage the full power of human-in-the-loop middleware while benefiting from a user-friendly interface and enterprise-grade reliability.
Conclusion
Human-in-the-loop middleware represents a crucial bridge between the efficiency of autonomous AI agents and the necessity of human oversight in production systems. By implementing approval workflows, editing capabilities, and rejection feedback mechanisms, you can build agents that are both powerful and safe. The three-way decision model—approve, edit, reject—provides flexibility to handle different types of human oversight needs, from low-stakes operations that can be approved quickly to high-stakes decisions that require careful consideration and modification. The implementation is straightforward, requiring just a few lines of code to add to your existing LangChain agents, yet the impact on system reliability and safety is substantial. As AI agents become increasingly capable and are deployed in more critical business processes, human-in-the-loop middleware will become an essential component of responsible AI deployment. Whether you’re building email assistants, financial systems, healthcare applications, or any other domain where agent actions have real consequences, human-in-the-loop middleware provides the framework you need to ensure that human judgment remains central to your automation workflows.
Frequently asked questions
Human-in-the-loop middleware is a component that pauses AI agent execution before running specific tools, allowing humans to approve, edit, or reject the proposed action. This adds a safety layer for expensive or risky operations.
Use it for high-stakes operations like sending emails, financial transactions, database writes, or any tool execution that requires compliance oversight or could have significant consequences if executed incorrectly.
The three main response types are: Approval (execute the tool as proposed), Edit (modify the tool parameters before execution), and Reject (refuse execution and send feedback back to the model for revision).
Import HumanInTheLoopMiddleware from langchain.agents.middleware, configure it with the tools you want to interrupt on, and pass it to your agent creation function. You'll also need a checkpointer to maintain state across interruptions.
Arshia is an AI Workflow Engineer at FlowHunt. With a background in computer science and a passion for AI, he specializes in creating efficient workflows that integrate AI tools into everyday tasks, enhancing productivity and creativity.
Arshia Kahani
AI Workflow Engineer
Automate Your AI Workflows Safely with FlowHunt
Build intelligent agents with built-in approval workflows and human oversight. FlowHunt makes it easy to implement human-in-the-loop automation for your business processes.
Building Extensible AI Agents: A Deep Dive into Middleware Architecture
Learn how LangChain 1.0's middleware architecture revolutionizes agent development, enabling developers to build powerful, extensible deep agents with planning,...
Why Top Engineers Are Ditching MCP Servers: 3 Proven Alternatives for Efficient AI Agents
Discover why leading engineers are moving away from MCP servers and explore three proven alternatives—CLI-based approaches, script-based tools, and code executi...
Rendervid AI Integration - Generate Videos with Claude Code, Cursor & MCP
Learn how to integrate Rendervid with AI agents using MCP (Model Context Protocol). Generate videos from natural language prompts with Claude Code, Cursor, Wind...
21 min read
Rendervid
AI Integration
+4
Cookie Consent We use cookies to enhance your browsing experience and analyze our traffic. See our privacy policy.