Fragebeantwortung
Fragebeantwortung mit Retrieval-Augmented Generation (RAG) kombiniert Informationsabruf und natürliche Sprachgenerierung, um große Sprachmodelle (LLMs) zu verbe...
5 Min. Lesezeit
AI
Question Answering
+4
Eine Retrieval-Pipeline ermöglicht Chatbots, relevante externe Informationen abzurufen und zu verarbeiten, um genaue, kontextbezogene und Echtzeit-Antworten mit RAG, Embeddings und Vektordatenbanken zu liefern.
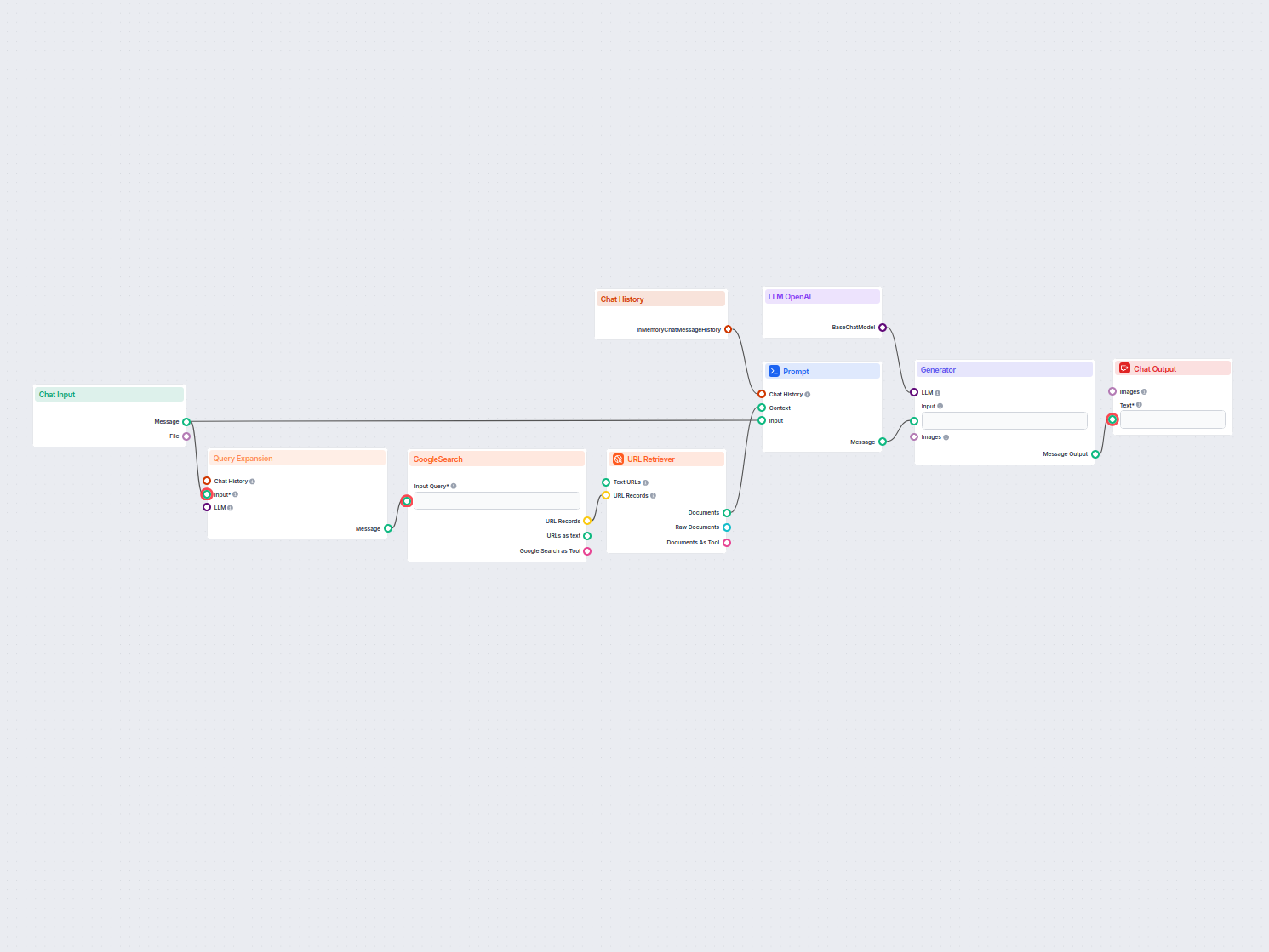
Eine Retrieval-Pipeline für Chatbots bezeichnet die technische Architektur und den Prozess, der Chatbots dazu befähigt, relevante Informationen abzurufen, zu verarbeiten und bereitzustellen, um Nutzeranfragen zu beantworten. Im Gegensatz zu einfachen Frage-Antwort-Systemen, die nur auf vortrainierte Sprachmodelle setzen, binden Retrieval-Pipelines externe Wissensdatenbanken oder Datenquellen ein. So kann der Chatbot genaue, kontextbezogene und aktuelle Antworten liefern, selbst wenn die Daten nicht im Sprachmodell enthalten sind.
Die Retrieval-Pipeline besteht typischerweise aus mehreren Komponenten wie Datenaufnahme, Erstellung von Embeddings, Vektorspeicherung, Kontextabruf und Antwortgenerierung. Häufig kommt dabei Retrieval-Augmented Generation (RAG) zum Einsatz, das die Stärken von Datenabrufsystemen und großen Sprachmodellen (LLMs) kombiniert.
Eine Retrieval-Pipeline erweitert die Fähigkeiten eines Chatbots, indem sie es ermöglicht:
Dokumentenaufnahme
Sammeln und Vorverarbeiten von Rohdaten, z. B. PDFs, Textdateien, Datenbanken oder APIs. Tools wie LangChain oder LlamaIndex werden häufig für eine nahtlose Datenaufnahme eingesetzt.
Beispiel: Laden von Kundenservice-FAQs oder Produktspezifikationen ins System.
Dokumentenvorverarbeitung
Lange Dokumente werden in kleinere, semantisch sinnvolle Abschnitte unterteilt. Das ist wichtig, um den Text in Embedding-Modelle mit begrenzter Tokenanzahl (z. B. 512 Tokens) einzupassen.
Beispiel-Code-Snippet:
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(document_list)
Erstellung von Embeddings
Textdaten werden mit Hilfe von Embedding-Modellen in hochdimensionale Vektorrepräsentationen konvertiert. Diese Embeddings kodieren die semantische Bedeutung der Daten numerisch.
Beispiel-Embedding-Modell: OpenAI’s text-embedding-ada-002 oder Hugging Face’s e5-large-v2.
Vektorspeicherung
Embeddings werden in Vektordatenbanken gespeichert, die für Ähnlichkeitssuchen optimiert sind. Häufig verwendete Tools sind Milvus, Chroma oder PGVector.
Beispiel: Speichern von Produktbeschreibungen und ihren Embeddings für effizienten Abruf.
Anfrageverarbeitung
Bei einer Nutzeranfrage wird diese mit demselben Embedding-Modell in einen Anfragevektor umgewandelt. So ist eine semantische Ähnlichkeitsabfrage mit gespeicherten Embeddings möglich.
Beispiel-Code-Snippet:
query_vector = embedding_model.encode("What are the specifications of Product X?")
retrieved_docs = vector_db.similarity_search(query_vector, k=5)
Datenabruf
Das System ruft die relevantesten Datenabschnitte basierend auf Ähnlichkeitsscores (z. B. Kosinus-Ähnlichkeit) ab. Multimodale Retrievalsysteme kombinieren ggf. SQL-Datenbanken, Wissensgraphen und Vektorsuchen für robustere Ergebnisse.
Antwortgenerierung
Die abgerufenen Daten werden mit der Nutzeranfrage kombiniert und an ein großes Sprachmodell (LLM) zur Generierung einer finalen, natürlichen Antwort übergeben. Dieser Schritt wird oft als augmented generation bezeichnet.
Beispiel-Prompt-Template:
prompt_template = """
Context: {context}
Question: {question}
Please provide a detailed response using the context above.
"""
Nachbearbeitung und Validierung
Fortgeschrittene Retrieval-Pipelines enthalten Mechanismen zur Halluzinationserkennung, Relevanzprüfung oder Antwortbewertung, um faktisch korrekte und relevante Ergebnisse sicherzustellen.
Kundenservice
Chatbots rufen Benutzerhandbücher, Fehlerbehebungshilfen oder FAQs ab, um sofortige Antworten auf Kundenanfragen zu liefern.
Beispiel: Ein Chatbot hilft beim Zurücksetzen eines Routers, indem er den passenden Abschnitt aus dem Handbuch bereitstellt.
Unternehmensweites Wissensmanagement
Interne Chatbots greifen auf unternehmensspezifische Daten wie HR-Richtlinien, IT-Support-Dokumente oder Compliance-Vorgaben zu.
Beispiel: Mitarbeitende fragen einen internen Chatbot nach Regelungen zum Krankheitsurlaub.
E-Commerce
Chatbots unterstützen Nutzer durch Abruf von Produktdetails, Bewertungen oder Verfügbarkeiten.
Beispiel: „Was sind die wichtigsten Eigenschaften von Produkt Y?“
Gesundheitswesen
Chatbots rufen medizinische Literatur, Leitlinien oder Patientendaten ab, um Fachpersonal oder Patienten zu unterstützen.
Beispiel: Ein Chatbot ruft Warnhinweise zu Wechselwirkungen von Medikamenten aus einer pharmazeutischen Datenbank ab.
Bildung und Forschung
Akademische Chatbots nutzen RAG-Pipelines, um wissenschaftliche Artikel abzurufen, Fragen zu beantworten oder Forschungsergebnisse zusammenzufassen.
Beispiel: „Kannst du die Ergebnisse dieser Studie von 2023 zum Klimawandel zusammenfassen?“
Recht und Compliance
Chatbots rufen juristische Dokumente, Gesetzestexte oder Compliance-Anforderungen ab, um Fachkräfte zu unterstützen.
Beispiel: „Was ist der aktuelle Stand der DSGVO-Regularien?“
Ein Chatbot, der Fragen aus dem jährlichen Finanzbericht eines Unternehmens im PDF-Format beantwortet.
Ein Chatbot, der SQL, Vektorsuche und Wissensgraphen kombiniert, um Mitarbeiteranfragen zu beantworten.
Durch den Einsatz von Retrieval-Pipelines sind Chatbots nicht mehr auf statische Trainingsdaten beschränkt und können dynamische, präzise und kontextreiche Interaktionen ermöglichen.
Retrieval-Pipelines spielen eine zentrale Rolle in modernen Chatbotsystemen und ermöglichen intelligente, kontextbewusste Interaktionen.
„Lingke: A Fine-grained Multi-turn Chatbot for Customer Service“ von Pengfei Zhu et al. (2018)
Stellt Lingke vor, einen Chatbot, der Informationsabruf integriert, um mehrstufige Dialoge zu führen. Er nutzt fein abgestimmte Pipeline-Prozesse, um Antworten aus unstrukturierten Dokumenten zu extrahieren, und setzt auf aufmerksames Kontext-Antwort-Matching für sequenzielle Interaktionen – das verbessert die Fähigkeit des Chatbots, komplexe Nutzeranfragen zu adressieren.
Lesen Sie das Paper hier
.
„FACTS About Building Retrieval Augmented Generation-based Chatbots“ von Rama Akkiraju et al. (2024)
Untersucht Herausforderungen und Methoden beim Aufbau von Enterprise-Chatbots mit Retrieval-Augmented Generation (RAG) Pipelines und großen Sprachmodellen (LLMs). Die Autoren stellen das FACTS-Framework vor, das auf Aktualität, Architektur, Kosten, Testung und Sicherheit bei der Entwicklung von RAG-Pipelines fokussiert. Die empirischen Ergebnisse beleuchten das Spannungsfeld zwischen Genauigkeit und Latenz beim Skalieren von LLMs und bieten wertvolle Einblicke in den Aufbau sicherer und leistungsstarker Chatbots. Lesen Sie das Paper hier.
„From Questions to Insightful Answers: Building an Informed Chatbot for University Resources“ von Subash Neupane et al. (2024)
Präsentiert BARKPLUG V.2, ein Chatbot-System für den Hochschulbereich. Mithilfe von RAG-Pipelines liefert das System präzise, domänenspezifische Antworten zu Campus-Ressourcen und verbessert so den Informationszugang. Die Studie bewertet die Effektivität des Chatbots mit Frameworks wie RAG Assessment (RAGAS) und zeigt dessen Nutzbarkeit im akademischen Umfeld. Lesen Sie das Paper hier.
Eine Retrieval-Pipeline ist eine technische Architektur, die es Chatbots ermöglicht, relevante Informationen aus externen Quellen als Antwort auf Nutzeranfragen abzurufen, zu verarbeiten und bereitzustellen. Sie kombiniert Datenaufnahme, Embedding, Vektorspeicherung und LLM-Antwortgenerierung für dynamische, kontextbezogene Antworten.
RAG verbindet die Stärken von Datenabrufsystemen und großen Sprachmodellen (LLMs), sodass Chatbots ihre Antworten auf aktuellen, externen Fakten stützen können. Das verringert Halluzinationen und erhöht die Genauigkeit.
Zu den wichtigsten Komponenten gehören Dokumentenaufnahme, Vorverarbeitung, Embedding-Erstellung, Vektorspeicherung, Anfrageverarbeitung, Datenabruf, Antwortgenerierung und Validierung durch Nachbearbeitung.
Anwendungsfälle sind u. a. Kundenservice, unternehmensweites Wissensmanagement, Produktinformationen im E-Commerce, medizinische Beratung, Bildung und Forschung sowie Unterstützung bei rechtlichen und Compliance-Fragen.
Herausforderungen sind Latenz durch Echtzeitabruf, Betriebskosten, Datenschutz und Skalierbarkeitsanforderungen beim Umgang mit großen Datenmengen.
Nutzen Sie die Vorteile von Retrieval-Augmented Generation (RAG) und externer Datenintegration, um intelligente, präzise Chatbot-Antworten zu liefern. Probieren Sie noch heute die No-Code-Plattform von FlowHunt aus.
Fragebeantwortung mit Retrieval-Augmented Generation (RAG) kombiniert Informationsabruf und natürliche Sprachgenerierung, um große Sprachmodelle (LLMs) zu verbe...
Wissensquellen machen es kinderleicht, die KI nach Ihren Bedürfnissen zu trainieren. Entdecken Sie alle Möglichkeiten, Wissen mit FlowHunt zu verknüpfen. Verbin...
Ein Echtzeit-Chatbot, der Google Search auf Ihre eigene Domain beschränkt, relevante Webinhalte abruft und das OpenAI LLM nutzt, um Benutzeranfragen mit aktuell...
Cookie-Zustimmung
Wir verwenden Cookies, um Ihr Surferlebnis zu verbessern und unseren Datenverkehr zu analysieren. See our privacy policy.